Last week, we began looking at index construction in detail.
We said an ADT for dictionaries should support: (1) Insert a new entry for term T, (2) Find and return the entry for term T (if present), and (3) Find and return the entries for all terms that start with a given prefix `P`.
(1) and (2) are needed for index construction, (2) and (3) are needed at query time, with (3) not strictly being neccessary.
We begin today by looking at some different kinds of dictionaries and how to implement them...
Dictionary Types
For a typical natural language text collection, the dictionary is relatively small compared to the total index size... In the book's example, an uncompressed index for GOV2 is 0.6% of the total index size, for Shakespeare they get 7% of the total index size.
This makes sense because in a larger collection we will tend to have seen all of the available words. Still, contrary to what you might think the number of distinct terms is not finite, but empirically grows something like `O(\sqrt(n))` where `n` is the number of documents seen.
The dictionary is small enough though that for moderately large indexes it can often still fit in memory.
In which case, the two most common in-memory dictionaries are:
A sort-based dictionary, in which all terms that appear in the text collection are arranged in a sorted array or in a search tree. Look up operations are realized through tree traversal.
A hash-based dictionary, in which each index term has a corresponding entry in a hash table. Collisions in the hash table are resolved by means of chaining.
Storing Dictionary Terms
If a sort-based dictionary is being used it is important that all the entries have the same size.
In GOV2 though the longest alpha-numeric sequence is 74,147 bytes long; the average sequence is 9.2 bytes long.
We could imagine truncating or padding all terms to length 20. Then storing sorted 20 bytes terms together with 8 byte integer offsets into the posting lists.
This approach would waste 10.8 bytes on average/term.
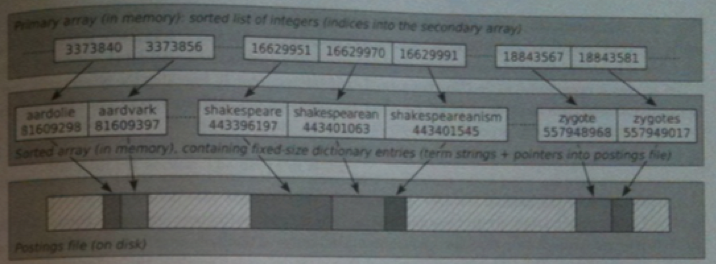
Instead, a dictionary-as-a-string approach is often used. Here we have two arrays: a primary sorted array of integer offsets into a secondary array containing the actual terms followed by their posting list offset.
Two adjacent elements in the primary array suffice to tell us the length of a term in the secondary array so we don't even have to store a null at the end of each string.
This scheme saves 10.8 - 4 (for the primary array) = 6.8 bytes over the original scheme.
Sort-based versus Hash-based dictionaries
For most applications a hash-based approach is faster than a sort-based implementation as a binary search and/or tree traversal is avoided.
This is assuming the collision chains are kept relatively small. i.e., Assuming the hash-table grows linearly with the number of terms.
The book gives a table showing that a properly scaled hash-table is about three times faster than a sort-based dictionary.
Unfortunately, the speed advantage is only for single term look-ups. Prefix lookups require linear scans; whereas, if you are using a sort-based approach they can be done via binary search and so done much more efficiently.
For this reason, many engines actually implement both approaches.
Posting Lists
We now look at posting lists.
As opposed to dictionaries, posting lists contain the majority of the information stored in an inverted index and tend to
be too large to store in memory.
Lists are transferred into memory on an as need basis.
To make the transfer of postings from disk to memory as efficient as possible, each term's posting list should be stored in a contiguous region of the hard-drive.
For single term queries one typically accesses a posting list in a sequential fashion.
On the other hand, for conjunctive queries we want to do things like galloping and binary search.
Random Accesses of Posting Lists
Binary search of a posting list of 50 million items, might take `|~ log_2(5 times 10^7)~| = 26` many random list accesses.
On a disk, that many accesses (each require a nonsequential page lookup) would be prohibitively slow, on the order of hundreds of milliseconds.
Alternatively one can try to read the whole posting list into memory, and then do in memory binary search.
50 million postings, each of 8 bytes, on a reasonably new hard drive would take about 4 seconds to read into memory.
So we need to do something different... one common idea is to use a per-term index.
A per-term index is a disk-based data structure that is part of the header of a posting list. It contains a copy of a subset of the postings in the posting list -- for example, every 5000th posting -- and the location in the posting list for these items.
When accessing the posting list, this structure is read into memory.
Searches are first done on the per-term posting list, then the relevant block of 5000 postings is read into memory.
Elements of the per-term-index are sometimes called synchronization points, and the whole per-term index method is sometimes called self-indexing.
Sometimes people consider using B-trees rather than per-term indexes, but in practice an at most two-tier per-term index suffices for even postings lists with billions of postings.
Prefix Queries
We already said that for prefix queries one needs to take a sorted approach to the dictionary.
This also holds for where the postings lists are stored on disk.
For example, if one does a search on "inform*" in GOV2, there are 4,365 different terms with that stem and 67million
postings corresponding to them.
By storing posting lists in lex order, we are ensuring that each of these posting lists will be close to each other on disk and
hence reduce our seek times.
If we had to do both a disk seek and rotational latency wait for each of the different terms, because they were stored on the disk in some random order, it would take a minute to access all the terms, not counting the times to do any operations on them.
If the postings lists were contiguous, on the other hand, this could be done in about 2 seconds.
Interleaving Dictionary and Posting Lists
The dictionary for the GOV2 collection consists in about 49 million distinct terms -- and this is small compared to Clue Web or say Google.
To hold all these entries together with pointers to the appropriate posting lists take about 1GB of memory -- doable, but it shows that even for large collections the dictionary itself might not fit into memory, even if compression is used.
If term bigrams are used the dictionary even gets larger.
Storing the entire dictionary on disk, however, is slow, it would require at least one more disk seek per term.
One solution to this problem is to dictionary interleaving: All entries are stored on disk, each entry right before the respective posting list. This allows the terms and posting list to be read with one read operation. In addition to this some dictionary entries are keep in memory. Lookup of nearest two entries is done in memory, then binary search between the pointers is used to find the correct posting list.
Usually, a block size of between 4 and 16KB between in memory dictionary entries suffices to reduce the in memory dictionary size to be easily storable in RAM.
Quiz
Which of the following is true?
Class autoloading in PHP is done using the Class:forName() method.
ASCII characters in UTF-8 take two bytes to store.
The page rank of a document might be stored in the document map part of the index.
Dropping the distinction between terms and postings
One can take the dictionary interleaving strategy further, by viewing index data as a sequence of pairs (term, posting).
The on-disk index could be divided into 64KB index blocks.
All postings are stored on-disk in alphabetical-order of their terms. Postings for the same term are stored in order of increasing posting offset.
The in-memory data structure used to access this on-disk index is a simple array, containing for each index block a pair of the form (term, posting) for the first term in the given block.
This approach unifies the self-indexing and interleaving methods we have described into a single thing to do.
Unfortunately, this approach tends to have higher memory requirements.