So far we have been assuming that the collection does not change during the process of index creation
For many applications such as indexing file systems, digital libraries, and the web, the collection does in fact change with time.
A dynamic index needs to support: (1) document insertions, (2) document deletions and (3) document modifications.
Since the semester is winding down and we still have a lot to cover, we will at handle the first two.
Collections that support the first two are sometimes called semi-static.
Batch Updates
For some applications, it might be okay to collect changes to the text collection over a period of time,
and then add them in one go in a batch update operation.
This is typically implemented in one of two ways:
(REBUILD) A new index is built from scratch. When this process is finished, the old index is deleted and replaced with the new one.
(REMERGE) An index is built from the text found in the newly inserted documents. After this index has been created, it is merged with the previously existing index.
Obviously, REBUILD is easier to implement, but it slower to add new data than REMERGE.
The situation as to which is better in the presence of both insertions and deletions is less clear...
REBUILD versus REMERGE
Suppose the original index `I_(old)` contains postings for `d_(old)` documents and all these documents are about the same size.
Suppose the batch update consists of `d_(\d\e\l\e\te)` deletions and `d_(\i\n\s\e\r\t)` insertions.
The new index, `I_(\n\e\w)` will contain postings for:
`d_(\n\e\w) = d_(old) - d_(\d\e\l\e\te) + d_(\i\n\s\e\r\t)`
documents
The time for REBUILD only depends on `I_(\n\e\w)`. For merge-based index construction, it can build `I_(\n\e\w)` in time `c cdot d_(\n\e\w) = c cdot (d_(old) - d_(\d\e\l\e\te) + d_(\i\n\s\e\r\t))`
On the other hand, if we do REMERGE instead, the answer depends on the relative performance of indexing and merging in the search engine.
Based on experiments the book's authors carried out with the GOV2 collection, the final merge operation in merge-based index construction takes about 25% of the total time required to build a full-text index.
From this we could estimate the time to REMERGE as:
`c cdot d_(\i\n\s\e\r\t) + frac(c)(4) cdot(d_(old) + d_(\i\n\s\e\r\t))`.
The two methods then exhibit the same performance if:
`d_(\d\e\l\e\te) = frac(3)(4) cdot d_(old) - frac(1)(4) cdot d_(\i\n\s\e\r\t)`.
If there are more deletions than the above it makes sense to REBUILD rather than REMERGE.
Quiz
Which of the following is true?
One step in Huffman coding is to calculate the probability of a sequence as a subinterval of [0,1).
`omega`-codes are an example of a parametric code.
Simple-9 is an example of a word-aligned code.
Incremental Index Updates
For applications like Internet news search, file system search, e-business search, etc.; it is imperative that the search results always accurately reflect the text collection.
In these cases batch updates are no longer an appropriate strategy.
We next look at how to do incremental updates in the case, where we only add new data and don't perform deletes.
The backbone on the hash-based in-memory index that we discussed earlier this semester, is an in-memory hash-table that maps from term strings to the memory address of the corresponding postings lists
This might be used for both query processing, in addition to index processing.
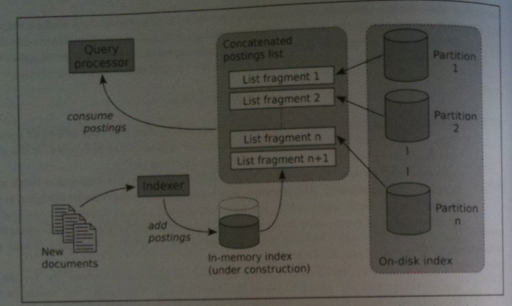
NO MERGE Index Updates
Suppose that, while the search engine is building an index, say after creating `n` on-disk index partitions, we want it to process a keyword query composed of `m` query terms.
We could repeat the following procedure for each of the query terms:
Fetch the terms postings list fragment from each of the `n` on disk index partitions
Use the in-memory hash table to fetch the term's in-memory list fragment.
Concatenate all n+1 fragments to form the terms postings list.
This strategy is called the NO MERGE index update strategy.
It tends not to be a very attractive strategy, due to the large number of disk seeks required to process a search query.
(one for every query term and index partition).
It is often used as a baseline to which other strategies are compared.
Contiguous Inverted Lists
The most drastic way to guarantee a low degree of fragmentation in the on-disk postings list is to not allow the creation of a new on-disk fragment for a term for which a list fragment already exists in the index.
There are two common ways to achieve this: using an in-place update; using a remerge update strategy.
REMERGE UPDATE
The batch remerge that we discussed earlier can be used not only for batch update operations in teh context of semi-static collections, but also as an update policy for incremental collections.
The search engine's indexing module processes incoming documents in the same way as in the static case.
However, whenever the indexer runs out of memory, a fresh on-disk index is created by merging the existing on-disk index with the data accumulated in-memory.
We call this strategy IMMEDIATE MERGE. Below is some pseudo-code:
In terms GOV2, if our partition size is 100k documents, then query response time according to the book is about 10 times faster than the NO MERGE case.
However, on the other hand, the total number of token transferred to/from disk with immediate merge is quadratic in the number of tokens in the collections, so is impractical for large indexes. To index GOV2 even with a partition size of 250K is about 6 times slower than NO MERGE.
In-place Index Updates
In-place index update strategies try to overcome IMMEDIATE MERGE's limitations by not requiring the search engine
read the entire index from disk every time it runs out of memory.
Instead, whenever a posting list is written to disk during an on-disk update, some free room is left at the end of the list.
When additional postings for the same term have to be transferred to disk at a later point in time, they can simply be appended to the existing list.
If the amount of free space available at the end of the list is too small, then the entire list is relocated to a new position on disk.
Different versions of in-place update, pre-allocate space differently. We will look at this more on Wednesday.