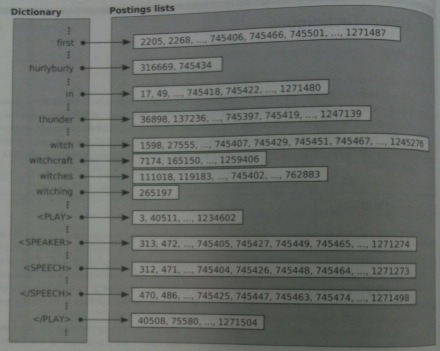
This could be implemented using our ADT with the following pseudo-code:
nextPhrase(t[1],t[2], .., t[n], position)
{
v:=position
for i = 1 to n do
v:= next(t[i], v)
if v == infty then // infty represents after the end of the posting list
return [infty, infty]
u := v
for i := n-1 downto 1 do
u := prev(t[i],u)
if(v-u == n - 1) then
return [u, v]
else
return nextPhrase(t[1],t[2], .., t[n], u)
}