










Subset-Sum, Start Approximation Algorithms
CS255
Chris Pollett
Apr 27, 2015
CS255
Chris Pollett
Apr 27, 2015
Theorem. SUBSET-SUM is `NP`-complete.
Proof. To see SUBSET-SUM is in `NP` notice if we are given an instance `langle S, t rangle` of subset sum and a particular encoding of set of integers `langle S' rangle`, by linear scan for each element of `S'` we can check if it is in `S`. Further, by another scan of `S'` we can compute the sum of the elements in `S'` and then check if they are equal to `t`. This whole procedure would take at most` O(|langle S, t rangle +langle S' rangle|^2)` and so is a polynomial time verification procedure for SUBSET-SUM.
To show SUBSET-SUM is `NP`-hard, i.e., any language in `NP` reduces to it, it suffices to reduce 3SAT to SUBSET-SUM, as we already showed 3SAT is `NP`-complete. Suppose `phi(x_1, ..., x_n)` is an instance of 3SAT with clauses `C_1, ..., C_k`. WLOG, we can assume each clause has exactly three distinct literal, no clause has both a literal and its negation, and each variable appears in at least one clause.
The reduction creates two numbers in set `S` for each `x_i` and two numbers in `S` for each `C_j`. Numbers will be created in base 10, where each number contains `n + k` digits and each digit corresponds to either one variable or one clause. Proof continues next slide...
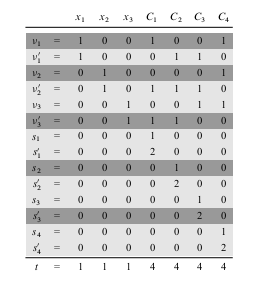
As we can see from the above picture we construct `S` and `t` by labeling each digit position by either a variable or a clause. The least significant `k` digits are labeled by clauses, and the most significant `n` digits are labeled by variables. In the picture above `phi = C_1 ^^ C_2 ^^ C_3 ^^ C_4`, where `C_1 = (x_1 vv neg x_2 vv neg x_3)`, `C_2 = (neg x_1 vv neg x_2 vv neg x_3)`, `C_3 = (neg x_1 vv neg x_2 vv x_3)`, and `C_4 = (x_1 vv x_2 vv x_3)`.
The maximum sum of digits in any digit position is at most `6`, so we don't have to worry above carries when we add numbers in `S`. `S` contains `2n + 2k` values each with `n +k` digits, where the time to produce a digit is polynomial in `n+k`, each digit of the target can be computed in constant time, so the whole reduction from `phi` to the `S` described above is `p`-time.
Suppose `phi` is satisfiable. If `x_i = 1` in this assignment include `v_i` in `S'`; otherwise include `v'_i` in `S'`. The sum of the `x_i` digit positions in `S'` will be `1` as we are only including one of the two `v_i`'s and all other `v_j`'s have `0` in the `x_i` digit position.
If we sum a `C_j` digit position from the elements so far added to `S'` we would get either `1`, `2`, or `3` depending on how many variables in the assignment satisfy this clauses. We can then add either `s_j` or `s'_j` or both to `S'` to ensure we get a sum of `4`. Hence, we have shown there exists an `S'` which achieves the target.
Suppose we have have constructed `S` and `t` as above, and there is an `S'` that achieves the target sum. Then to satisfy the `x_i` digit columns we must have exactly one of `v_i` or `v'_i` in `S'`. From which we can get an assignment for `phi`. The fact that the `C_j` column sum targets were achieved will ensure this is a satisfying assignment.
Which of the following is true?
APPROX-VERTEX-COVER(G)
1 C=∅
2 E'= E[G]
3 while E' ≠ ∅
4 let {u, v} be an arbitrary edge of E'
5 C = C ∪ {u, v}
6 Remove from E' every edge incident with either u or v
7 return C.
Theorem. APPROX-VERTEX-COVER is a p-time 2-approximation algorithm.
Proof. First, the algorithm runs in time `O(|V| +|E|)`, as we delete two vertices and at least one edge each time through the loop.
The set `C` returned by the algorithm is a vertex cover, since each edge that is removed is covered by some vertex in `C`. And the loop continues till no edges left.
To see that the cover returned is at most twice the optimal, let `A` denote the set of edges which were picked in line 4. In order to cover the edges in `A`, any vertex cover (including the optimal `C^star`) must include at least one endpoint of each edge in `A`. No two edges in `A` share an endpoint, so no two edge from `A` are covered by the same vertex from `C^star`. So `|C^star | ge |A|`. On the other hand `|C| = 2|A|`.
APPROX-TSP-TOUR(G, c) 1. Select a vertex r to be a root vertex 2. Compute the minimal spanning tree for G from root r using Prim's algorithm 3. Let L be the list of vertices visited in a pre-order tree walk of T 4. return the Hamiltonian cycle H that visits the vertices in order L.
MST-PRIM(G, w, r) // r is a starting node to grow the tree from 01 for each u in G.V 02 u.key = infty 03 u.pi = NIL 04 r.key = 0 05 r.pi = 0; 06 Q = MAKE-QUEUE(G.V) //will have all vertices 07 while Q != 0 08 u = EXTRACT-MIN(Q) 09 for each v in G.adj[u] 10 if v in Q and u.key + w(u, v) < v.key 11 v.pi = u 12 v.key = u.key + w(u,v) //call appropriate DECREASE-KEY
Theorem. APPROX-TSP-TOUR is a p-time 2-approximation algorithm for TSP with triangle-inequality holding on the cost function.
Proof. The minimal spanning tree algorithm runs in time `O(|V|^2)`. The remaining step take at most `O(|G|)` time.
Let `H^star` denote the optimal tour of the vertices. Since we can obtain a spanning tree from any tour by deleting an edge, we have `c(T) le c(H^star)` where `T` is our minimal spanning tree. A full walk `F` of `T` lists the vertices when they are first visited and also whenever they are returned to after a visit to a subtree. So `c(F) = 2c(T) le 2c(H^star)`. A full walk is typically not a tour since it lists some vertices twice.
On the other, the `H` returned by the algorithm is a tour and satisfies `c(H) le c(F)`, since it is obtained by deleting vertices from the full walk and since the triangle inequality holds. We are using the triangle inequality as if we have a sequence `a b c` in the full walk and delete `b`, our tour we want that the cost does not rise.