Router Implementation is in many ways similar to switch implementation, which we've already discussed.
Routers must be able to handle variable length packets. So in this respect router implementation differs from ATM based switch implementation.
Often a router's fabric does switching based on cells.
To make this possible, the input and output ports need to be able to handle segmentation and reassembly.
Router's can usually forward a certain number of packets per second (pps).
So total throughput in bits per second depends on packet size.
The physical speed of a port in bits per second is called the line rate.
The largest packet size that can be handled at this rate is given by:
packetsize = linerate/pps.
More on Router Implementation
Two common router implementation approaches to the problem of forwarding IP packets are: centralized and distributed.
In the centralized model, the IP forwarding algorithm is done in a single processing engine that handles traffic from all ports.
In the distributed model, the IP forwarding algorithm uses several processing engines, either at each port or for a group of ports.
The distributed model should in theory be faster, however, it is more complicated as now several forwarding tables need to be maintained, etc.
Unlike bridge and ATM switch forwarding, the router needs to be able to determine if a particular IP address is directly reachable off an interface or whether the packet needs to be sent to another router. The number of bits of the IP address to use is thus variable depending on the network address of the router to which we want to send.
Quiz
Which of the following is true?
Link-state routing suffers from the count to infinity problem.
In the early internet, costs of links were estimated as 1/link_bandwidth.
The Routing Information Protocol is a particular implementation of the distance vector routing algorithm.
Global Internet
So far our discussion of internetworks has been somewhat "scalable".
Each router does not need to know each host on the internet, but it does need to know
each network.
Today's internet has ten or hundreds of thousands of networks connected to it, and the routing protocols
we've discussed so far don't scale to those kinds of sizes.
We next look at techniques which can scale to the needed sizes.
To discuss these techniques, we first recall from last day we described how using OSPF
we split our internetworks into autonomous systems (AS's), where an AS might be an ISP or
some other entity that is under one organizations administrative control.
Each router just needs to know how to route in its AS or AS's. (Might belong to backbone AS and
some other one)
Two issues we need to address with scaling: (1) minimizing the number of network numbers that get carried around in
the protocol, (2) making sure that the available IP addresss do not get consumed too quickly.
Subnetting
The original intent of IP addresses was that the network part would uniquely identify exactly one physical network.
The problem is a class C network can only have 255 nodes and it is very easy for a small company to exceed this.
On the other hand, there are far too few class B network addresses (only 214, about 16000 ).
If we assign many network numbers to an organization (i.e., make an organization up out of many Class C networks) then
router forwarding tables will start to grow too quickly and so the forwarding algorithms will tend to get slower.
To solve this problem, the idea of subnetting was introduced.
In subnetting, one takes a single IP network number and allocates the IP addresses with that number to several physical networks
referred to as subnets.
It should be the case that these subnets are physically close to each other.
All nodes on the same subnet must be configured with the same subnet mask. This mask indicates which bits
of the IP address will be kept when dealing with the subnet. So for instance, 255.255.255.0 could be bit-wise AND'd to the IP address of a
host on a Class C network to get the relevant subnet (i.e., its network address).
More on Subnetting
Subnetting effectively allows us to split up a large network like a Class B network into smaller subnets which are still bigger than a Class C network.
Class B Network
Network number
Host Number
Subnet Mask 255.255.192
111111111111111111
00000000000000
Subnetting the Class B Network
Network number
Subnet ID
Host Number
To send when subnetting is in use, a host ANDs the destination IP address with the host's own IP mask. If it results in the hosts
own subnet, then it knows it can deliver the packet over the subnet.
Otherwise, if the result is not equal, the packet needs to be sent to a router to be forwarded to another subnet.
To handle subnetting a router's forwarding table now has entries (subnet address, subnet mask, outgoing
line)
When a packet arrives at a router. Its destination IP address is
extracted, this is matched to a router entry, by first ANDing it with the
entry mask then comparing to the subnet address. If it matches the
corresponding line is used.
Classless Interdomain Routing (CIDR)
CIDR is a technique that address two scaling concerns in the internet: the growth of backbone routing tables
as more and more network numbers need to be stored in them, and the potential for the 32 bit IP address space to be exhausted well before the 4 billionth host is attached to the internet.
Rather than use classes, in CIDR, network addresses are often written as
Address/#lead on bits in the mask. Masks are 32 bits with the lead bits
on, the rest off. For example, we might write the IP address as:
194.24.0.0/21
This number can then be used to refer to a whole AS and gives us a finer control over the size of such networks than could be had using a classful approach.
Notice although similar to subnetting, in subnetting we wanted to share the same address for multiple different physical networks.
Wireshark
We pause for a moment on the problem of routing to look at another network tool.
Wireshark (http://www.wireshark.org/) is a free packet sniffer much like tcpdump but with a graphical front-end.
It has a nice interface to easily allow you to look at Ethernet frames, IP packets, as well as, Wireless, TCP and UDP, etc. traffic.
It used to be called Ethereal but the name was changed in 2006 because of trademark issues.
Using Wireshark
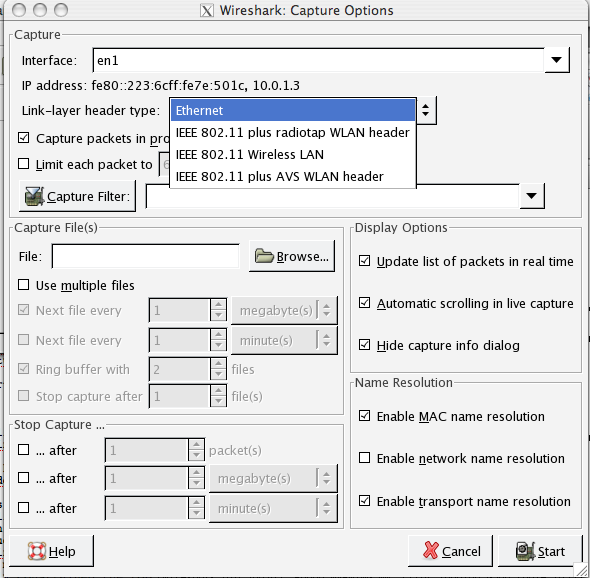
After starting Wireshark with sufficient privileges to access the interfaces you want to look at, you can click on Capture > Options to set up the kind of traffic capture you want to do.
Notice you can also set a Capture Filter if you want. This would allow you to say just capture TCP traffic, or even further restrict the traffic you are looking at. For instance, you might want to look at just HTTP traffic to some host.
Once you have set-up the options as you like, you can use Capture > Start and Capture > Stop to begin/end recording traffic.
You can then either look at this traffic manually, by clicking on the packets you would like to look at in more detail or you can use the Analyze and Statistics menus to automate analyzing what you are seeing.
Interdomain Routing
So far we have looked at routing within autonomous systems (AS's) (aka domains), that is, internetworks under a single administrative control.
The interdomain routing problem is the problem of having different AS's share reachability information -- the IP addresses that can be reached via a given AS.
Each AS is allowed and needs to be able to set its own routing policies.
Such a policy might be to always prefer to send traffic via AS X versus AS Y, perhaps because, your AS gets a cheaper rate for sending traffic
over AS X than over AS Y.
Other issues might be you can't send traffic through such and such country.
Whatever interdomain routing procedure is used, it needs to support such policies.
The first major interdomain routing protocol was the Exterior Gateway Protocol (EGP).
It severely constrained the topology of the AS's into a tree.
Its replacement is the Border Gateway Protocol (BGP) which we'll consider next.
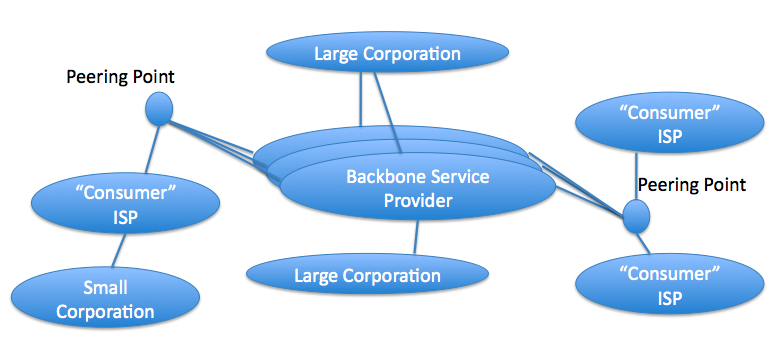
The Multi-backboned Internet
Unlike EGP, BGP supports multiple backbone networks. These are usually called service provider networks.
The topology of today's network might be abstracted as:
Given this view of the internet, we define local traffic as traffic that originates and terminates within an AS; and we define
transit traffic as traffic that passes through an AS.
We can classify AS's into three types:
Stub AS - an AS that has only one single connection to one other AS. For example, a small corporation in the above
Multi-homed AS - an AS that has connections to more than one other AS, but that refuses to carry transit traffic. A large corporation might be an example of this.
Transit AS - an AS that has connections to more than one other AS and that is designed to carry both transit and local traffic. An example of this might be a backbone provider.
Challenges of Interdomain Routing
Scale - a backbone router must be able to forward any packet destined anywhere on the internet. CIDR helps
control this, but still there are on the order of a couple hundred thousand of valid address prefixes.
Difficulty in Computing Path Costs - each AS might be using a different interior routing protocol,
each with their own path metrics. So it is hard to combine these into one cost. Instead, interdomain routing
advertises only path reachability.
Trust - Provider A might not believe certain advertisements from Provider B. For instance, B might be
misconfigured to say it supports routes to anywhere. This often means having policies of the form:
"use AS X to reach prefixes p and q, if and only if AS X advertised reachability to these prefixes."