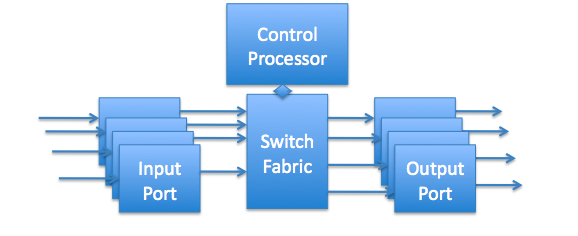
Finish Cell Switching; Switch Implementation
CS158a
Chris Pollett
Mar. 9, 2011
CS158a
Chris Pollett
Mar. 9, 2011
| < 64KB | 0-47 bytes | 16 bits | 16 bits | 32 |
| Data | Pad | Reserved | Len | CRC-32 |
Throughput = pps × (BitsPerPacket)
= 1 × 10^6 × 64 × 8
= 512 × 10^6
So 512 Mbps, a lot less than the earlier upper bound.