We now look at algorithms that enable routers and switches to acquire the information that is in their forwarding tables.
Forwarding is the process of looking at a packets destination address in a table, and sending a packet in a direction determined by that table.
Routing is the process by which forwarding tables are built.
A forwarding table is used when a packet is being forwarded and so must contain enough information to accomplish this function.
A routing table is the table that is built-up by the routing algorithm as a precursor to building the forwarding table.
The two are often kept separate so that the forwarding table can be as fast as possible.
The first algorithms we will consider scale to networks of moderate size.
They are used for intradomain routing protocols (aka interior gateway protocols (IGPs)).
Here a domain is an internetwork in which all the routers are under the same administrative control. For instance, a university campus network or a network of a single ISP.
Network as a Graph
We view a domain as a graph where the nodes are either hosts, switches, routers, or networks and the edges are
network links.
Each edge has an associated cost, which indicates how desirable it is to send data over that link.
The basic problem with routing is to find the lowest-cost path between any two nodes in such a graph.
For a simple network, you could imagine statically computing this and then hard-coding the information into each node.
This approach is not taken in practice because:
It does not deal with node or link failures
It does not consider the addition of new nodes or links
It implies that the edge costs cannot change, even though we might reasonably wish to temporarily assign a high cost to
congested links.
For these reasons, routing is typically achieved by running routing protocols among the nodes.
These protocols provide a distributed, dynamic way to solve the problem of finding the lowest-cost path.
Quiz
Which of the following is true?
Datagrams are never dropped at the IP level.
Virtual Private Networks often use IP tunnels as their building blocks.
A + event descriptor in ns2 means the packet was received.
Distance Vector (RIP)
The distance-vector (aka Bellman-Ford) algorithm is one such distributed routing algorithm.
The starting assumption is that each node knows the costs of its directly connected neighbors.
The routing table has entries of the form (Destination, Cost, Next Hop) and is initialized to just these
connected neighbors.
Each router then sends its routing table to each of its directly connected neighbors.
Using this information, the receiving router updates its own table. Here are a couple of cases where a receiving router might have to update its table:
The sending router sends information for a host that the receiving router has never heard of before
The path to some host through the sending router might be cheaper than some existing path.
This process is then repeated until hopefully the routing table converges to a table with routing information for the whole domain.
Routers following distance vector send periodic updates to make sure the routing information is current.
They also send triggered updates whenever a node receives information that causes the nodes tables to be updated.
Problems with Distance Vector
Although distance vector routing does converge to the correct answer, it tends
to do it slowly.
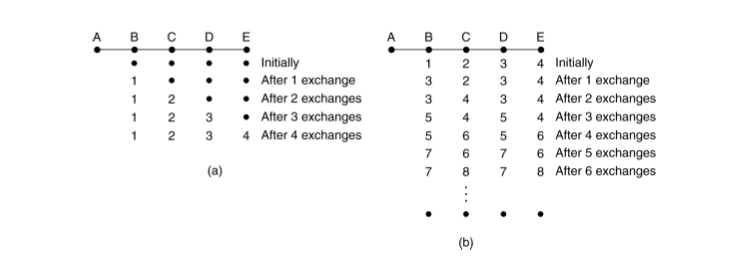
As an example, consider the situations below in a linear network where on the
left A comes alive at some time t and on right where it fails at some later time.
On the left it takes a significant amount of time for all machines to get the
correct distance to A. On the right the machines keep incrementing the
distance to A forever (count to infinity problem):
One approach to solve this is to use a split horizon: You don't send routes you learned from neighbors back to them.
Another problem with Distance Vector routing is that it does not take line
bandwidth into account.
More on RIP
Distance Vector routing is an idealized algorithm to compute forwarding tables.
One of its chief implementations is the Routing Information Protocol (RIP) which became popular because
of its inclusion in BSD Unix.
In our model of distance vector, we tell our neighbor routers our cost to reach them.
In the RIP model what we tell our neighbors is the cost to reach various networks to which we know of.
Otherwise, RIP is a fairly straightforward implementation of distance vector.
Routers running RIP send their advertisements every 30 seconds.
RIP supports multiple types of addresses not just IP.