Chris Pollett >
Old Classes
>
CS157b
( Print
View )
Student Corner:
[Grades Sec1]
[Grades Sec2]
[Submit Sec1]
[Submit Sec2]
[Email List Sec1]
[Email List Sec2]
[Lecture Notes]
Course Info:
[Texts & Links]
[Topics]
[Grading]
[HW Info]
[Exam Info]
[Regrades]
[Honesty]
[Announcements]
HW Assignments:
[Hw1]
[Hw2]
[Hw3]
[Hw4]
[Hw5]
Practice Exams:
[Mid1]
[Mid2]
[Final]
HW2 Solutions Page
Book Problems
3.3.10 Suppose that if we swizzle all pointers automatically, we can perform swizzling in half the time it would take to swizzle each one separately. If the probability that a pointer in main memory will be followed at least once is p, for what values of p is it more efficient to swizzle automatically that on demand?
Let t be the time to swizzle a pointer automatically, and let T be the time to swizzle on demand. So we are told T=2t. Let N be the total number of pointers. Then swizzling on demand, we need to swizzle N*p; whereas swizzling automatically we need to swizzle all N. In the first case, the total time spent swizzling is N*p*T = N*p*2*t. In the second case, the total time spent swizzling is N*t. So if the first is greater than the second, it makes sense to swizzle automatically. Now N*p*2*t > N*t implies p > 1/2.
3.5.1 (a) Compare methods (i) and (ii) for the average numbers of disk I/Os needed to retrieve the record, once the block (or first block in the chain with overflow blocks) that could have a record with a given sort key is found. Are there any disadvantages to the method with the fewer disk I/Os?
In method (i) the given block will always have the record so only one I/O would be needed to look up the record. In constrast, in method (ii) we have to search the chain of overflow blocks, which might involve more than one I/O. In terms of space efficiency, blocks in method (i) will tend to between half full (right after a split) to totally full; whereas, blocks in method (ii) can always be near capacity. Also, the index in method (i) will be larger usually.
(b) Compare methods (ii) and (iii) for their average numbers of disk I/Os per record retrieval, as a function of b, the total number of blocks in the chain. Assume that the offset table takes 10% of the space, and the records take the remaining 90%.
For method (ii) we can expect that we'd have to search through roughly half of the overflow blocks to find the record we want. So for method (ii) we'd have b/2 rounded up I/Os. For method (iii), the first b/10 blocks would be needed for the offset table. We'd expect to need to one I/O to get past this (following the first offset), and then need to search .9*b/2 =.45*b blocks to find the record. If we can't figure out record endpoints without the offset table we would need to look through half the offset table as well. In which case we'd also end up spending b/2 I/Os.
(c) Include methods (iv) and (v) in the comparison from part (b). Assume the sort key is 1/9th of the record. Note that we do not have to repeat the sort key in the record if it is in the offset table. Thus, in effect, the offset table uses 20% of the space and the remainders of the records use 80% of the space.
Method (iv) and method (ii) still take the same amount of time so b/2 rounded up. b won't change in method (iv) because we are only storing the sort key once. Now, however, it is in the offset table. With method (v) we can search half of the offset table, 1/2*.2*b = .1*b blocks, and then with one more I/O find the record.
4.1.1 Suppose blocks hold either three records, or ten key-pointer pairs. As a function of n, the number of records, how many blocks do we need to hold a data files and: (a) A dense index? (b) A sparse index?
In a dense index we'd need one index entry for every record, so we'd need n index entries and n records. It would take n/10 blocks to store the index and n/3 blocks, for a total of (13/30)*n blocks. In the case of a sparse index, we'd need one index entry for each block of the main file, so n/3 index entries. These could be held in n/30 blocks. Thus, the total size would be (11/30)*n blocks.
Execute the following operations on Fig 4.23. Describe the changes for operations that modify the tree.
(a) Lookup the record with key 41.
This would involve looking at the node [13| |], following the right pointer to [23|31|43]. Then the pointer to the right of 31 would be followed to the node [31|37|41], and from their the pointer to the left of 41 would be followed to the record for this key.
(b) Lookup the record with key 40.
This would be the same as (a) except the last step, where we'd realize 40 was not in the tree.
(c) Lookup all the records in the range 20 to 30.
We first look through the sequence of nodes [13| | ], [23|31|43], and [13|17|19], the last being a leaf node. We then scan this leaf node for a value bigger than 20. We don't find such a value, so we follow the leaf node's right pointer to [23|29| ]. Both of these key values are in the range, so we look up the corresponding records and output them. Then we follow this nodes right pointer to [31|37|41]. Since 31 is greater than 30 we stop.
(d) Lookup all the records with keys less than 30.
We first find the left hand leaf of the tree by going through the nodes [13| | ], [7| | ], and [2|3|5]. This latter is a leaf node. We output all of its corresponding records as 2,3,5 are each less than 30. Then this node's right pointer would be followed to [7|11| ] and again each of its records would be output. Continuing this way, we output the records for [13|17|19] and [23|29| ], before stopping when we read [31|37|41].
(e) Lookup all the records with keys greater than 30.
We look through [13| | ], [23|31|43], [23|29| ], which is a leaf node. We don't see a value greater than 30 so we follow this last nodes right pointer to [31|37|41]. These values are all greater than 30 we output the corresponding records. Then we continue and output the records for [43|47|], which is the last leaf node.
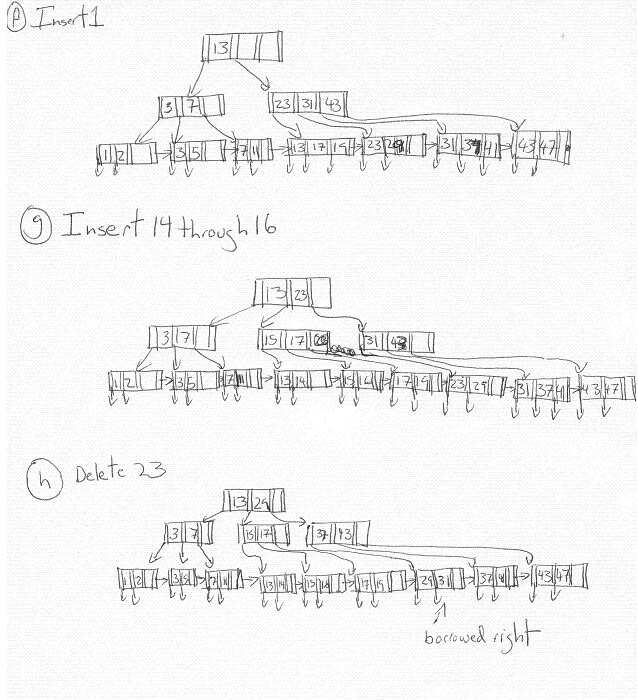
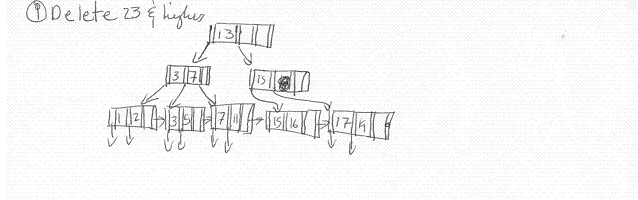
4.4.1 Show what happens to the buckets in Fig. 4.30 if the following insertions and deletions occur:
(i) Records g through j are inserted into buckets 0 through 3, respectively.
======== 0 d | g | ======== ========= 1 e |--+| h | c | | | ======== ========= 2 b | i | ======== ========= 3 a |--+| j | f | | | ======== =========
(ii) Records a and b are deleted.
========
0 d |
g |
======== =========
1 e |--+| h |
c | | |
======== =========
2 i |
|
========
3 j |
f |
========
(iii) Records k through n are inserted into buckets 0 through 3, respectively.
I am assuming block consolidation on deletion. ======== ========= 0 d |--+| k | g | | | ======== ========= 1 e |--+| h | c | | l | ======== ========= 2 i | m | ======== ========= 3 j |--+| n | f | | | ======== =========
(iv) Records c and d are deleted.
======== 0 k | g | ======== ========= 1 e |--+| l | h | | | ======== ========= 2 i | m | ======== ========= 3 j |--+| n | f | | | ======== =========
DataGenerator.java
//DataGenerator.java -file used to generate test data for CS157B Hw2 Spring 2005
import java.util.*;
import java.io.*;
/**
This class consists of a bunch of public static methods used to generate
random row data for the CS157B HW2.
Typically one would run this program from the command line with a line like:
java DataGenerator tmp.DAT 1000
here tmp.DAT is the file to write the random data to and 1000 is the number of
rows of random data to generate.
@author Chris Pollett
@version 3.4.2005
*/
public class DataGenerator
{
/**
Creates numRows rows of random Movie Table data and save it in a file named
by String movie.
@param file -- filename to store random row data in
@param numRows -- number of rows of data to create
*/
public static void createData(String file, int numRows)
{
try
{
PrintStream outFile = new PrintStream(
new FileOutputStream(file));
for(int i = 1; i <= numRows; i++)
{
StringBuffer row = new StringBuffer(BUFLEN);
createRow(i, row);
outFile.println(row.toString());
}
outFile.close();
}
catch(IOException ie)
{
ie.printStackTrace();
}
}
/**
Creates one row of random Movie table data given the parameters supplied.
@param num -- movieID od row to create
@param row -- presumed empty StringBuffer in which to append random row.
*/
public static void createRow (int num, StringBuffer row)
{
row.append((new Integer(num)).toString()+"\t");
for(int i=0; i < COLBSTRINGLEN; i++)
{
char preLetter;
String letter;
preLetter = (char)('A' + Math.random()*26);
letter = (new Character(preLetter) ).toString();
row.append(letter);
}
}
/**
Calls createData with the command line arguments to generate the random
data
@param args - array of command line arguments.
*/
public static void main (String [] args)
{
if(args.length < 2)
{
System.out.println("To use:");
System.out.println("java DataGenerator filename numRows");
System.out.println("where filename is the file you'd like data written to");
System.out.println("and numRows is how many rows you'd like generated.");
}
else
createData(args[0], Integer.parseInt(args[1]));
}
/*
The next constants are used to specify the lengths of the columns and a row
*/
public static final int COLBSTRINGLEN = 100;
public static final int BUFLEN = 120;
}
DataLoader.ctl
LOAD DATA INFILE tmp.DAT INTO TABLE MyTable FIELDS TERMINATED BY '\t' ( A, B)
SelectTest.java
//SelectTest.java -- program to generate statistics for CS157b Spring 2005 Hw2
import java.util.*;
import java.io.*;
import java.sql.*;
/**
This class has a collection of public static methods useful for generating
timing statistics for the select query from CS157B HW2 Spring 2005
Should be run from the command line like:
java SelectTest datafile rownum
where datafile contains the that was bulkloaded into Oracle
rownum is the row to look up in the datafile for the hundred character string that we'll
do a select test on Oracle.
@author C. Pollett
@version 4.4.2005
*/
public class SelectTest
{
public static String getStringRowNum(String fileName, int num)
/**
Reads num many rows from fileName, expects to find a tab then a hundred
character String. This string is returned.
@param fileName - name of the file with the bulk loaded data
@param num -- number of the row to look up column B of 100 hcracters from
@return -- hundred character string for that row
*/
{
String result="No Value Yet";
try
{
BufferedReader buf= new BufferedReader(
new FileReader(fileName)
);
//open a Reader for the file fileName
for(int i = 0; i< num-1; i++)
{
buf.readLine();
}
result = buf.readLine();
result = result.substring(result.indexOf("\t")+1);
buf.close();
}
catch(FileNotFoundException fe)
{
System.err.println("File not found");
System.exit(1);
}
catch(IOException ie)
{
System.err.println("An I/O Exception occurred:"+ie.toString());
System.exit(1);
}
catch(Exception ee)
{
ee.printStackTrace();
System.exit(1);
}
return result;
}
/**
Calculate the average time over NUM_TRIALS trials to perform
select * from MyTable where B= supplied hundred character string
@param rowString - hundred character string
@return -- average time to perform query over NUM_TRIALS trials.
*/
public static double testSelect(String rowString) throws SQLException
{
double totalTime = 0;
long startTime;
// set up the connection to the database
Connection conn =
DriverManager.getConnection(connectString,login, password);
for(int i = 0 ; i < NUM_TRIALS; i++)
{
String query = "select * from MyTable where B='" + rowString +"'";
Statement stmt = conn.createStatement();
startTime = System.currentTimeMillis();
ResultSet rset = stmt.executeQuery(query);
rset.next(); //we're assuming result exists
int columnA = rset.getInt(1);
totalTime += System.currentTimeMillis() - startTime;
stmt.close();
}
conn.close();
return totalTime/NUM_TRIALS;
}
/**
Main driver method for this class.
Generate the statistics based on the supplied number of trials from the command line
@args -- command line argument qith number of trials
*/
public static void main (String [] args)
{
if(args.length < 2)
{
System.out.println("To use:");
System.out.println("java SelectTest datafile rownum");
System.out.println("where datafile is the file originally used to bulk load the table");
System.out.println("and rownum is the row number you want out of the file.");
System.exit(1);
}
String rowString=getStringRowNum(args[0], Integer.parseInt(args[1]));
try
{
DriverManager.registerDriver(
new oracle.jdbc.OracleDriver());
System.out.println("Generating statistics about how long it to took to process:\n\n");
System.out.println("select * from MyTable where B= some hundred character string");
System.out.println("Row number of string: " + args[1]);
System.out.println("Row string: " + rowString);
System.out.println("Average time in millisecond: " +
testSelect(rowString));
}
catch (SQLException se)
{
System.out.println("SQL Exception:");
se.printStackTrace();
}
catch (Exception e)
{
e.printStackTrace();
}
}
public static final String connectString = "jdbc:oracle:oci8:@";
//string to connect to a database
public static final String login = "login"; // login to connect to database
public static final String password = "password"; // password to connect to database
public static final int NUM_TRIALS = 1; // number of times to perform test
}
Experiments.txt
I carried out a couple of experiments with my data generator program. First, I tried generating just a 1000 rows and seeing how long my program took. Below is the log file from bulk loading sqlldr:
SQL*Loader: Release 8.1.7.0.0 - Production on Mon Apr 4 00:29:55 2005 (c) Copyright 2000 Oracle Corporation. All rights reserved. Control File: DataLoader.ctl Data File: tmp.DAT Bad File: tmp.bad Discard File: none specified (Allow all discards) Number to load: ALL Number to skip: 0 Errors allowed: 50 Bind array: 64 rows, maximum of 65536 bytes Continuation: none specified Path used: Conventional Table MYTABLE, loaded from every logical record. Insert option in effect for this table: INSERT Column Name Position Len Term Encl Datatype ------------------------------ ---------- ----- ---- ---- --------------------- A FIRST * WHT CHARACTER B NEXT * WHT CHARACTER Table MYTABLE: 1000 Rows successfully loaded. 0 Rows not loaded due to data errors. 0 Rows not loaded because all WHEN clauses were failed. 0 Rows not loaded because all fields were null. Space allocated for bind array: 33024 bytes(64 rows) Space allocated for memory besides bind array: 0 bytes Total logical records skipped: 0 Total logical records read: 1000 Total logical records rejected: 0 Total logical records discarded: 0 Run began on Mon Apr 04 00:29:55 2005 Run ended on Mon Apr 04 00:30:00 2005 Elapsed time was: 00:00:04.24 CPU time was: 00:00:00.12
I then ran SelectTest using this data a few times to see how fast it would find say the 500 or so row's 100 character string. The file is 1000 rows of around 100 bytes per record so roughly 100k. It seemed to take about 50 milliseconds on average to find the string. My program has a NUM_TRIALS constant which repeats the look-up that many times before disconnecting. After the first look-up subsequent look-ups seemed to be almost instantanaeous. For instance, when I set the NUM_TRIALS to 10, the average look-up time was 5 milliseconds. So essentially, after the first lookup subsequent ones took no-time. Probably, this was because the relevant block was being cached.
The next experiment I tried was to vary the size of tmp.DAT. So I next did:
java DataGenerator tmp.DAT 10000
I did some experiments looking up the 5001st element. These seemed to average out at 70 milliseconds or so. The size of the table is now roughly 100*10000 or 1MB. So as expected it was slower. Now if table scan is a linear time operation, than it seems it would roughly follow the equation 50 + (20/9000)x, as it took us 20 milliseconds longer to do almost 9000 rows more. So if we were to do 100,000 row table we'd expect the time to be about 272 milliseconds. So I tried 100,000 rows to see what happened. Here is an example output from SelectTest when I did the experiment:
|sigma:pollett:80>java SelectTest tmp.DAT 50001 Generating statistics about how long it to took to process: select * from MyTable where B= some hundred character string Row number of string: 50001 Row string: eflvdogoxvidlqfgwhaygakxuaaxkuaronuoligtfohhoevehefvwhpmypdzhybgltdtyjnuvycfakxgjtjidgbmfxoodjnnftlw Average time in millisecond: 254.0
The size of the 100,000 row table is around 10 MB. The average time was around 250 milliseconds. This is reasonably close to the predicted value. Maybe once we've found the track with the data, some latency factors were minimized and explain the slightly smaller than expected number.
The fact that all these results are so slow in these experiments shows that even though the table would completely fit within the 2GB main memory of sigma, it is not typically cached there.
Notice we can also probably get an estimate of the time to read a block on sigma's drive. If a record is about 100 bytes long and the block size were 4096. Then maybe 40 records would fit in a block. So if it takes 20 milliseconds to read about 9000 records, that means one block takes about (20/9000)*40 = .09 milliseconds to read block. Usually hard drive transfer rates are in terms of MB/sec. Our value works out to 45MB/sec, this seems close to the ballpark value for a three or four year old SCSI drive.