Chris Pollett >
Old Classes
>
CS157b
( Print
View )
Student Corner:
[Grades Sec1]
[Grades Sec2]
[Submit Sec1]
[Submit Sec2]
[Email List Sec1]
[Email List Sec2]
[Lecture Notes]
Course Info:
[Texts & Links]
[Topics]
[Grading]
[HW Info]
[Exam Info]
[Regrades]
[Honesty]
[Announcements]
HW Assignments:
[Hw1]
[Hw2]
[Hw3]
[Hw4]
[Hw5]
Practice Exams:
[Mid1]
[Mid2]
[Final]
HW1 Solutions Page
Book Problems
2.2.1
(a) What is the capacity of the disk?
There are 10,000 tracks on a surface and 10 surfaces in the drive giving 100,000 tracks. Each track holds 1000 sectors of 512 bytes, so 512,000 bytes total. Thus, the disk can hold 5.12* 1010bytes
(b) If all the tracks hold the same number of sectors, what is the density of bits in the sectors of a tracks?
For this problem I am assumming the actual disk is the same size as the Megatron 747. If you state your assumptions in this regard you should receive full credit. So as in the 747 only the outer inch of each 3.5 inch diameter surface is occupied. So as there are 10,000 cylinders this gives 1/10000 bits per inch radially. Around a track the density is higher... Each track holds 512*1000=5.12 x 105 bytes = 4.07 x 106 bits. Assuming 20% gaps, we have .8 * π x d =2.51 x d inches holds 4.07 x106 bits where d is the diameter of the track. This give bit density = 1.62 x 106/d bits per inch. When d is 3.5 this gives 5.41 x 105 bits per inch and when d is 1.5 it gives 1.08 x 106 bits per inch
(c) What is the maximum seek time?
This is the time to move across all 10,0000 tracks. We are given the time to move n tracks is: 1 + .001n msec. Plugging 10,000 in for n gives 11 msec
(d) What is the maximum rotational latency?
In the worst case, we would have to wait one revolution. At 10,000 rpms, this takes our drive 1/10000 rpm * 60 min/sec = 6msec.
(e) If a block is 16,384 bytes, what is the transfer time of a block?
First, we compute what fraction in degrees of a disk track 16K bytes = 32 blocks would occupy. Between the 32 block are 31 gaps. As a track is 20% gaps and there 1000 sectors, and hence 1000 gaps, all the gaps occupy 72 degrees of arc and so 31 gaps occupy 72 x 31/1000 = 2.23 degrees of arc. Similarly, the sectors in total occupy 288 degrees of arc and so 32 sectors occupy 288 x 32/1000 = 9.21 degrees. Thus, the data occupies 11.4/360 th of a revolutions and it takes 6 msec to do one revolution. So the transfer time is .19 msec.
(f) What is the average seek time?
First, we calculate the average number of tracks we move starting from track x. This is, 1/n [sum^{x-1}_{y=1}(x-y) + sum^{n}_{y=x+1} y-x]. Here n =10,000 is the number of tracks. The first term is from those track which are below x and the second term is from those tracks larger than x. Rewriting this we have: 1/n[sum^{x-1}_{y=1}x - sum^{x-1}_{y=1}y + sum^{n-x}_{y=1} y] = 1/n[x(x-1) - (x-1)x/2 + (n-x)(n-x+1)/2] = 1/(2n)[x(x-1) + (n-x)(n-x+1)] = 1/(2n)[2x^2 - (2n+2)x +n(n+1)]. If we integrate this function from 1 to n and divide by n we get an estimate of the average number of tracks. Integrating give 1/(2n)[2/3x^3 - (n+1)x^2 +n(n+1)x] evaluate as n and 1. This is 1/(2n^2)[[2/3n^3 - (n+1)n^2 + n^2(n+1)] - [2/3 - n+1 + n(n+1) ]]. Subsituting n = 10,000 gives roughly 3, 330 tracks (Throughout I am only keeping 3 significant digits). So to move this distance takes 1 + .001*3330 = 4.33 msec.
(g) What is the average rotational latency?
This is about one half the maximum rotational latency. In this case, the average rotational latency is 6/2 = 3 msec.
Adding the above components together, the average latency = 4.33 + 3 + .19 = 7.53 msec
2.3.1
Using Two-Phase, Multiway Merge_sort, how long would it take to sort the relation of Example 2.5 if the Megatron 747 disk were replaced by the Megatron 777 disk described in Exercise 2.2.1, and all other characteristics of the machine and data remained the same?
As block size has changed to 16K (part of e 2.2.1), 163 records fit in a block with 84 bytes left over. The relation of 10,000,000 tuples now fits in 61,350 blocks. As main memory also hasn't changed, we still have 50M/16k= 3200 blocks of main memory. So in phase one we read in 3200 blocks from the file 19 times sort and write them out. Finally there are 550 blocks left over that we read in and sort and then write out. In this phase, we have to read and write each block once. As the average latency from the previous problem is 7.33 msec, this takes 899,000 msec = 899 s. Roughly, 15 minutes. For phase 2, as we can hold 20 blocks in main memory, we could read a block from sorted list and merge these in one go. So we again read and write each block once for this phase. So it takes another 899s. The total time is thus 1,800s or 30 min.
2.4.1
Suppose we are scheduling I/O requests for a Megatron 747 disk, and the requests in Fig 2.15 are made, with the head initially at track 4000. At what time is each request serviced fully if:
(a) We use the elevator algorithm.
Let's assume we were initially moving outward. Since at time 0 there are no requests for cylinders beyond 4000 we'd swap directions and service the request for 1000. The seek time to do this is 1 + 3000/500 = 7 msec. Since we are doing a six block reads, as it says in the caption of figure 2.15, and the minimum latency of the 747 according to Example 2.3 is .5 msec, to transfer these blocks takes 3 msec. Further, we expect to wait half a revolution or 15.6/2 = 7.8 msec before we can transfer. So this first request takes 7+ 7.8 + 3 = 17.8 msec. By time 17.8 the request for cylinder 6000 and 500 have arrived. So we service the request for 500 next. This take 10.8 + 500/500 = 11.8 msec so is done by time 29.6. As there are no further requests in this direction we next service the request for cylinder 5000 which will have come in by this point. This will take 10.8+4500/500 =19.8 msec and will be done by time 29.6+19.8= 49.4 msec. Finally we service the request for cylinder 6000. This takes 10.8+1000/500 =12.8 msec and is done by time 62.2 msec.
(b) We use first come, first serve scheduling.
We first satisfy the request for cylinder 1000, which will take 17.8 msec as above. Then we'd service cylinder 6000. This would take 10.8 + 5000/500 = 20.8 msec and would be done by time 38.6. After this, we'd do the request for cylinder 500, taking another 10.8+5500/500 = 21.8 msec. We'd be done by 60.4 msec. Finally, the cylinder 5000 request would be handled taking another 10.8+4500/500 =19.8msec. So we'd be done by time 80.2 msec.
2.6.1
Suppose we use mirrored disks as in Example 2.16, the failure rate in 4% per year, and it takes 8 hours to replace a disk. What is the mean time to a disk failure involving loss of data
The probability that the mirror disk fails while we are copying, is the odds we fails in a given year x the fraction of the year to do the copying. That is, 1/25 x (8/24 x 1/365) = 3.65 x 10-5 or one in about 27,400. Assuming a linear failure model, if 4% of the disks fail in a given year, then 50% will have failed by year 12.5 years, so this the mean time to failure. That means we'd expect one of the two disks to have failed by 6.25 years. So the mean time to a failure resulting in data loss is 6.25 x 27,400 = 171,250 years.
ER Assignment
Here are the ER diagrams I came up with to model the different ERP Modules. In real life, these modules would be much more complicated. I was looking for three or four tables and relations which roughly modeled the given settings.
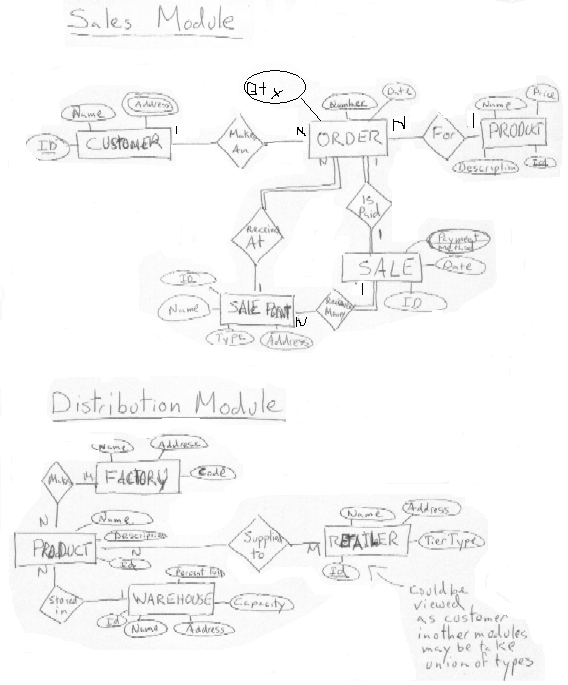
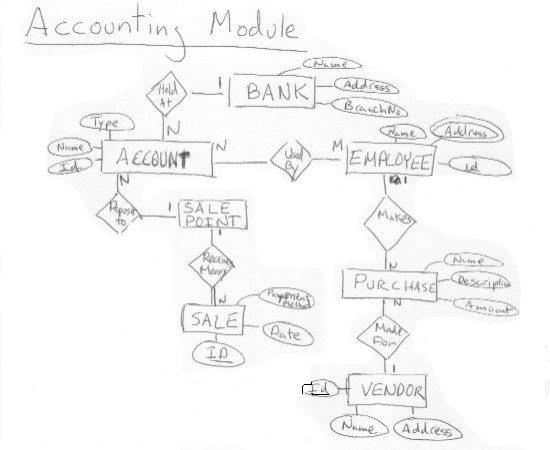
This is the Access Sales Database, I created from the Sales module. An example transaction might be to find all the names of products where the product tuple has a given set of keys words in its descriptions and the product is within a given price range. To carry out this kind of tansaction, we would look up where the Product table was stored in the Database catalog and read its schema. Once we had this information, we would scan through, the Product table record by record. For each record, we would look for the keywords as substrings of the Description column, if we found them we would check if the price in the Price column was in the given range and, if so, output the Name column of this tuple.