Chris Pollett >
Old Classes
>
CS157b
( Print
View )
Grades:
[Sec1] [Sec2]
Submit:
[Sec1] [Sec2]
Course Info:
[Texts & Links]
[Topics]
[Grading]
[HW Info]
[Exam Info]
[Regrades]
[Honesty]
[Announcements]
HW Assignments:
[Hw1]
[Hw2]
[Hw3]
[Hw4]
[Hw5]
Practice Exams:
[Mid1]
[Mid2]
[Final]
HW3 Solutions Page
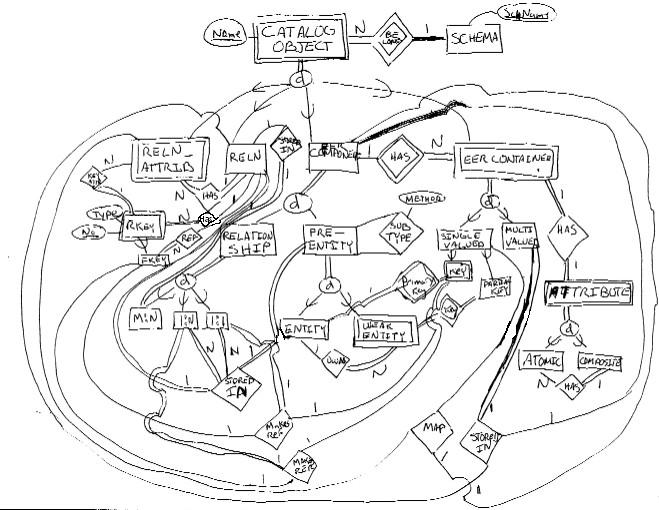
17.14 For this problem one could really go wild trying to model all aspects of EER diagrams and all aspects of the mapping of diagrams to relations. You should at least model the most common things in EER: Entities, Relationships, Attributes, Subtyping; and the most common things in the relational model: Relations, Attributes, Keys and Foreign keys; and have a couple of relationships indicating the mapping between these two things. One might provide more detail than my solution below. I got a little bit lazy and used n-way relationships for the mapping. These relationships could be split into several two-way relationships.
18.13 For each of the following queries give:
(a) Two distinct query trees representing the query and where one might
use which
(b) The initial query tree that would be made for the heuristic
query optimization algorithm. Show how the tree would be optimized.
(c) For each query, compare your own query trees with those of (b).
Q1
SELECT FNAME, LNAME, ADDRESS
FROM EMPLOYEE, DEPARTMENT
WHERE DNAME='Research' AND DNUMBER= DNO;
(a)
π_FNAME, LNAME, ADDRESS
|
σ_DNAME='Research'
|
|X|_DNUMBER=DNO
/ \
EMPLOYEE DEPARTMENT
and
π_FNAME, LNAME, ADDRESS
|
|X|_DNUMBER=DNO
/ \--------------σ_DNAME='Research'-----------DEPARTMENT
π_FNAME, LNAME, ADDRESS
|
EMPLOYEE
I would probably always use the second query since it probably always produces
smaller join results. The first query tree might be used if the
query processor wasn't capable of doing big trees. I am assuming
that the processor computes joins so as to make
the table with the smaller number of rows the one used in the outer loop.
(b) An initial tree might look like:
π_FNAME, LNAME, ADDRESS
|
σ_DNAME='Research' AND DNUMBER=DNO
|
X
/ \
EMPLOYEE DEPARTMENT
To optimize we first break up selects and push them as far down the
tree as possible. The would give:
π_FNAME, LNAME, ADDRESS
|
σ_DNUMBER=DNO
|
X
/ \--------------σ_DNAME='Research'-----------DEPARTMENT
EMPLOYEE
Then we'd combine select's and cartesian products as joins
π_FNAME, LNAME, ADDRESS
|
|X|_DNUMBER=DNO
/ \--------------σ_DNAME='Research'-----------DEPARTMENT
EMPLOYEE
Finally, we move projections as far down tree as possible and then group
like operations. This gives
π_FNAME, LNAME, ADDRESS
|
|X|_DNUMBER=DNO
/ \--------------σ_DNAME='Research'-----------DEPARTMENT
π_FNAME, LNAME, ADDRESS
|
EMPLOYEE
(c)
This is the same as the second query I had in part (b), so it looks like
I did an okay job of guessing the answer. Compared to the initial, the
join will be much smaller and so faster.
For the remaining problems I won't go through part (b) in as much detail.
Also, the answer to part (c) will roughly always be the heuristic seems
to produce decent results compared to the initial tree and probably
as good as my guestimated optimization.
Q8
SELECT E.FNAME, E.LNAME, S.FNAME, S.LNAME
FROM EMPLOYEE AS E, EMPLOYEE AS S
WHERE E.SUPERSSN=S.SSN
(a)
π_E.FNAME, E.LNAME, S.FNAME, S.LNAME
|
|X|_E.SUPERSSN=S.SSN
/ \
E S
Another better possibility is:
π_E.FNAME, E.LNAME, S.FNAME, S.LNAME
|
|X|_E.SUPERSSN=S.SSN
/ \_______________
π_E.FNAME, E.LNAME π_S.FNAME, S.LNAME
| |
E S
(b) This initial query tree looks like:
π_FNAME, LNAME, S.FNAME, S.LNAME
|
σ_E.SUPERSSN=S.SSN
|
X
/ \
E S
The optimized tree would like the second one I gave above.
Q1B
SELECT E.FNAME, E.LNAME, E.ADDRESS
FROM EMPLOYEE E, DEPARTMENT D
WHERE D.NAME='Research' AND D.DNUMBER = E.DNUMBER;
(a)
π_E.FNAME, E.LNAME, E.ADDRESS
|
|X|_E.DNUMBER=D.DNUMBER
/ \
E σ_D.NAME='Research'
|
D
and slightly more efficient
π_E.FNAME, E.LNAME, E.ADDRESS
|
|X|_E.DNUMBER=D.DNUMBER
/ \__________________________
π_E.FNAME, E.LNAME, E.ADDRESS σ_D.NAME='Research'
| |
E D
(b) An initial query tree would look like:
π_E.FNAME, E.LNAME, E.ADDRESS
|
σ_E.DNUMBER=D.DNUMBER AND D.NAME='Research'
|
X
/ \
E D
The second tree in (a) is also the optimized tree from the algorithm.
Q4
(
SELECT DISTINCT PNUMBER
FROM PROJECT, DEPARTMENT, EMPLOYEE
WHERE DNUM=DNUMBER AND
MGRSSN = SSN AND LNAME = 'Smith'
)
UNION
(
SELECT DISTINCT PNUMBER
FROM PROJECT, WORKS_ON, EMPLOYEE
WHERE PNUMBER = PNO AND ESSN = SSN AND LNAME='Smith'
)
(a)
Here are two possible query trees the second being more optimized:
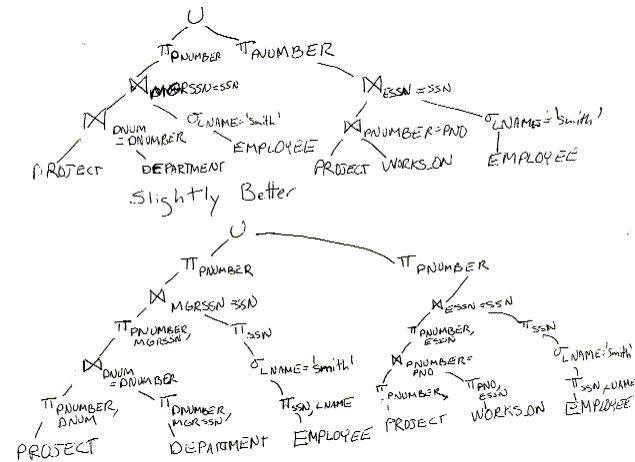
(b) The initial tree for this query would look like
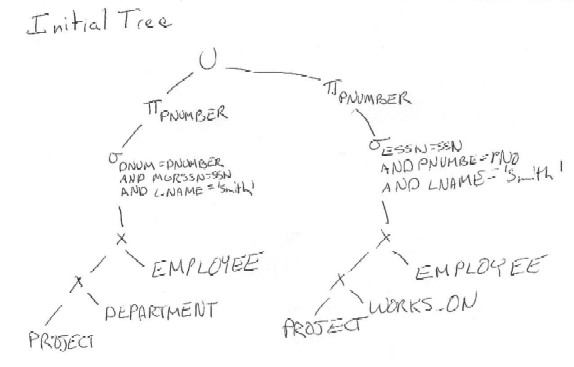
The optimized tree would actually be the second tree from part (a)
Q28
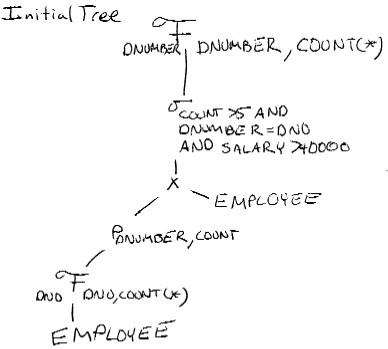
SELECT DNUMBER, COUNT(*)
FROM DEPARTMENT, EMPLOYEE
WHERE DNUMBER = DNO AND SALARY>40000
AND DNO IN (SELECT DNO
FROM EMPLOYEE
GROUP BY DNO
HAVING COUNT(*) > 5)
GROUP BY DNUMBER;
(a)
Here are two possible query trees the second being more optimized:
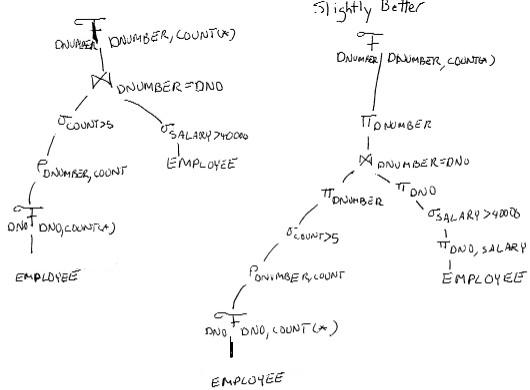
(b) The initial tree for this query would look like
18.14 How many merge passes does it take to sort a 4096 block file with a 64
block buffer using the external merge sort algorithm?
ANS.
After the sort phase the file will be sorted into runs of 64 blocks in length.
After the first merge phase the file will be sorted into runs of
length 64*63=4032 (remember one block of buffer used to store the output).
This is still less than the original file size so one more merge pass is
neccessary to sort the file. So the answer is 2. Alternatively, we could
have calculated log_63(4096/64) = 2 (rounded up).
18.22 Compare the cost of two different query plans for the following query:
σ_SALARY>40000(EMPLOYEE|X|_DNO=DNUMBER DEPARTMENT)
ANS:
There was a typo in the original problem SALARY > 40000 was
written as SALARY. 40000. If you assumed it was SALARY=40000 and did things
consistently it should be okay. As the question only says do it for
two query plans and makes no mention of optimization I will consider
the orginal query expressed as a tree and a slightly more optimized
variant:
σ_SALARY > 40000 (**)
|
|X|_DNO=DNUMBER
/ \
EMPLOYEE DEPARTMENT
and
|X|_DNO=DNUMBER (***)
/ \_________
σ_SALARY > 40000 |
| |
EMPLOYEE DEPARTMENT
To make these into query plans we have to say how the individual operations
are performed. Answers will vary on this but you should be very precise
about the algorithm and what assumptions you are making. Figure
18.8 indicates there is an index on SALARY but for range queries
not worth it to use. There is nothing top indicate that there is an
index on DEPARTMENT DNUMBER.
So I'll assume that the join in both (**) and (***) is a nested
loop join and we choose DEPARTMENT for the outer loop.
Further I'll assume that about half the records satisfy the given range condition.
Given this let's analyze the cost of (**)
The cost to perform the join will be:
C = b_D +(b_D*b_E +((js *|D|*|E|/bfr_DE)
= 5 + 5*2000 + (1/50)*50*10000/(5/50 + 2000/10000)
= 10005 +10000*(1/10 + 2/10) = 10005 + 3000 = 13005
The join selectivety is 1/50 as DNUMBER is a key of DEPARTMENT
We also note 1/bfr_DE = 1/bfr_D + 1/bfr_E.
We note the above step returns about 3000 blocks worth of data.
Note we can no longer assume the output is sorted by SALARY.
So to do the select we need to brute force search through all the records.
Thus, the total cost of the first plan is thus 16005.
For (***) we first do the select using brute force. The cost of this
will be 2000 and about 1000 blocks of data and 5000
records will be returned. Let's pretend it is materialized into a
temp table S. Thus, the cost of the join will be
C = b_D +(b_D*b_S +((js *|D|*|S|/bfr_DS)
= 5 + 5*1000 + (1/50)*50*5000/(5/50 + 1000/5000)
= 5005 + 5000*(3/10) = 6505.
So the total cost of this plan is 8505.
The code for the last homework problem can be found below:
// sortmerge.java -- implements n-way sortmerge for CS157b Hw3 Problem 5.
import java.util.*;
import java.io.*;
/**
This class consists of a bunch of public static methods used to implement
n-way sort merge for CS157B HW3 Problem 5. This code handles spanned
records.
Typically one would run this program from the command line with a line like:
java sortmerge num_blocks_buffer block_size_byte in_file out_file
where in_file is the file you'd like sorted
out_file is the output file of sorted data
num_blocks_buffer (>=3) is the number of buffer block of RAM you will allow
block_size_byte is the number of bytes in each buffer (disk block size)
Note tried to make sort method work even if invoked on several files
concurrently before one
sort had finished.
@author Chris Pollett
@version 1.0.2002
*/
public class sortmerge
{
/**
Main static method used to sort a file to a target file
@param numBlocks -- number of blocks in buffer
@param blockSize -- size of a block in byutes
@param inFile -- input file to be sorted
@param outFile -- output file to sort to
*/
public static void sort(int numBlocks, int blockSize, String inFile, String outFile)
{
NWayMergeSorter sorter =
new NWayMergeSorter(numBlocks, blockSize, inFile, outFile);
double startTime = (double)System.currentTimeMillis();
sorter.sort();
double endTime = (double)System.currentTimeMillis();
System.out.println("Total elapsed time (s):"+
(endTime/1000-startTime/1000));
}
/**
Calls sort with the command line arguments to sort the given file
@param args - array of command line arguments
*/
public static void main (String [] args)
{
if(args.length < 4 || Integer.parseInt(args[0]) < 3 )
{
System.out.println("To use:");
System.out.println(
"java sortmerge num_blocks_buffer block_size_byte in_file out_file");
System.out.println("where in_file is the file you'd like sorted");
System.out.println("out_file is the output file of sorted data");
System.out.println(
"num_blocks_buffer (>=3) is the number of buffer block of RAM you will"+ "allow");
System.out.println(
"block_size_byte is the number of bytes in each buffer (disk block size)");
}
else
sort(Integer.parseInt(args[0]), Integer.parseInt(args[1]), args[2],
args[3]);
}
}
/**
This is an auxiliary class that actually does
n-way sort merge for CS157B HW3 Problem 5.
@author Chris Pollett
@version 1.0.2002
*/
class NWayMergeSorter
{
/**
Constructor for a sorting object. We create instance of the
NWayMergeSorter class so that the sortmerge class could be used
by many other classes concurrently to sort files.
@param nBlks -- number of blocks in the buffer to create
@param size -- size in bytes of the buffer
@param inF -- input file
@param outF -- output file
*/
public NWayMergeSorter(int nBlks, int size, String inF, String outF)
{
numBlocks = nBlks;
numTemps = numBlocks - 1;
totalBlocks = 0;
blockSize = size;
inFile = inF;
outFile = outF;
evenPhase = true;
inArray = new FileInputStream[numTemps]; //array of input temp files
outArray = new FileOutputStream[numTemps]; // array of outptu temp files
blocksTemp = new int[2*numTemps];
for(int i = 0; i < 2*numTemps; i++)
blocksTemp[i] = 0;
recordSize = determineRecordSize();
recordsPerBlock = blockSize/recordSize;
System.out.println("Record Size: "+recordSize);
System.out.println("Records per Block: "+ recordsPerBlock);
memBuffers = new SortingBuffers(recordSize,
recordsPerBlock + 1, nBlks, PAD_BLOCK_CHAR);
}
/**
sorts the given file to output.
@return -- true if sort successful
*/
public boolean sort()
{
if(recordSize == 0 || memBuffers == null) return false;
if(sortPhase() && mergePhase() && generateOutputFile())
return true;
return false;
}
/**
Does the sort phase of the n-way merge sort algorithm
Uses heapsort.
@return true -- if successful
*/
boolean sortPhase()
{
char[] tmp = new char[recordSize];
int runSize = numBlocks*blockSize;
int recordCnt = 0;
int byteCnt = 0;
int runCnt = 0;
memBuffers.setSortMode();
try
{
FileInputStream in = new FileInputStream(inFile);
for(int i = 0 ; i < numTemps; i++)
outArray[i] = new FileOutputStream("tmp"+i+inFile);
int data;
while((data=in.read()) != -1)
{
tmp[recordCnt] = (char)data;
recordCnt++;
if(recordCnt >= recordSize)
{
if((tmp=memBuffers.insert(tmp)) == null)
{
System.err.println("Heap insert error");
return false;
}
recordCnt = 0;
}
byteCnt++;
if(byteCnt >= runSize)
{
int blks = memBuffers.dumpOutputStreamUnspanned(blockSize,
outArray[runCnt]);
totalBlocks += blks;
blocksTemp[runCnt] += blks;
runCnt++;
if(runCnt >= numTemps) runCnt = 0;
byteCnt = 0;
}
}
int blks = memBuffers.dumpOutputStreamUnspanned(blockSize,
outArray[runCnt]);
totalBlocks += blks;
blocksTemp[runCnt] += blks;
in.close();
for(int i = 0 ; i < numTemps; i++)
outArray[i].close();
if(recordCnt != 0)
System.out.println("Last Record was incomplete so ignored.");
}
catch(Exception e)
{
e.printStackTrace();
return false;
}
return true;
}
/**
Does the merge phase of the n-way merge sort algorithm.
The priority queue from the heap sort phase is reused to say what is
should be the next smallest this to merge to the output.
This is probably only cost effective to do (if ever) if have a lot of
buffers. I just thought it was cool to do.
@return true -- if this phase successful
*/
boolean mergePhase()
{
boolean done = false;
memBuffers.setMergeMode();
int pass =0;
try
{
while(!done )
{
System.out.println("Pass number"+ pass);
if((done = initStreams())) continue;
totalBlocks = 0;
int emptyBuffer = -1;
int activeBuffers = runBuffers;
int undoneTemps = runBuffers;
int recordCnt = 0;
int runCnt = 0;
while( undoneTemps > 0 )
{
if((emptyBuffer=memBuffers.mergeRecord()) >= 0)
{
int tmpNum = emptyBuffer;
if(!evenPhase) tmpNum += numTemps;
if(blocksTemp[tmpNum] == 0 )
{
undoneTemps--;
activeBuffers--;
}
if(blocksTemp[tmpNum] > 0)
{
blocksTemp[tmpNum]--;
if(memBuffers.readUnspannedBlock(blockSize,
emptyBuffer,inArray[emptyBuffer]))
{
activeBuffers--;
}
else
memBuffers.addRecordHeap(emptyBuffer);
}
emptyBuffer = -1;
}
if(emptyBuffer == -2 )
{
System.out.println("An error occurred while merging");
System.out.println("recordCnt"+recordCnt);
System.out.println("ActiveBuffers"+activeBuffers);
System.out.println("Undone temps"+undoneTemps);
System.exit(1);
}
recordCnt++;
if(recordCnt == recordsPerBlock || activeBuffers == 0)
{
totalBlocks++;
memBuffers.writeUnspannedBlock(recordCnt, blockSize,
outArray[runCnt]);
recordCnt = 0;
int index = runCnt;
if(evenPhase) index += numTemps;
blocksTemp[index]++;
if(activeBuffers == 0)
{
for(int i =0; i < numTemps; i++)
{
if(memBuffers.addRecordHeap(i)) activeBuffers++;
}
runCnt++;
if(runCnt >= runBuffers) runCnt = 0;
if(activeBuffers == 0) undoneTemps = 0;
}
}
}
evenPhase = !evenPhase;
for(int i = 0; i < numTemps; i++)
{
inArray[i].close();
outArray[i].close();
}
pass++;
}
}
catch(IOException ie)
{
ie.printStackTrace();
return false;
}
return true;
}
/**
Used to set up the input and output files at the start of a merge pass
during the merge phase
@return true -- if file could be inited
*/
boolean initStreams() throws IOException
{
boolean done =false;
runBuffers = numTemps;
int offsetEven = 0;
int offsetOdd = 0;
if(evenPhase) offsetEven = numTemps;
else offsetOdd = numTemps;
memBuffers.resetLastBuffer();
try
{
for(int i = 0; i < numTemps; i++)
{
inArray[i] = new FileInputStream("tmp"+(i+offsetOdd)+inFile);
outArray[i] = new FileOutputStream("tmp"+(i+offsetEven)+inFile);
System.out.println("Input File:" + (i + offsetOdd) + "Blocks" +
blocksTemp[i+offsetOdd]+"Total Blocks"+totalBlocks);
if(totalBlocks <= blocksTemp[i + offsetOdd]) done = true;
if(blocksTemp[i + offsetOdd] == 0) runBuffers --;
else
{
memBuffers.readUnspannedBlock(blockSize, i, inArray[i]);
blocksTemp[i + offsetOdd]--;
memBuffers.addRecordHeap(i);
}
blocksTemp[i+offsetEven] = 0;
}
System.out.println("Number of run buffers:"+runBuffers);
}
catch(FileNotFoundException f)
{
System.err.println("Unable to find tmp file aborting");
return true;
}
return done;
}
/**
After the merge phase is over this method is called, to take the
temp file with the sorted data in it, convert the unspanned
records back into spanned records and write the result to the
desired output file.
@return true -- if successful
*/
boolean generateOutputFile()
{
FileInputStream in;
int bufSize = numBlocks*blockSize;
try
{
if(evenPhase)
in = new FileInputStream("tmp0"+inFile);
else
in = new FileInputStream("tmp"+numTemps+inFile);
FileOutputStream out = new FileOutputStream(outFile);
int data;
int cnt = 0;
char c;
char oldc = '\0';
while((data = in.read()) !=-1)
{
c=(char)data;
if(c != PAD_BLOCK_CHAR || c != oldc)
{
memBuffers.add((char)data);
cnt++;
if(cnt == bufSize)
{
memBuffers.dumpOutputStreamSpanned(cnt,out);
cnt=0;
}
}
oldc = c;
}
memBuffers.dumpOutputStreamSpanned(cnt,out);
in.close();
out.close();
}
catch(Exception e)
{
e.printStackTrace();
return false;
}
return true;
}
/**
This function is called before any sorting is done to determine the
size of records in the input file. It is assumed all records have the
same size.
@return -- size of records in bytes.
*/
int determineRecordSize()
{
try
{
FileInputStream in = new FileInputStream(inFile);
recordSize=1;
while((char)in.read() != '\n')
recordSize++;
in.close();
}
catch(Exception e)
{
System.err.println("Error reading file named: " + inFile);
System.err.println("recordSize:" + recordSize);
e.printStackTrace();
return 0;
}
return recordSize;
}
/*
Field of NWayMergeSorter
*/
boolean evenPhase; //says whther in even or odd pass during merge phase
int numBlocks; // number of blocks in the buffer
int numTemps; // numBlocks-1 (so don't have to keep calculating)
int blockSize; //size of block in bytes
int recordSize; // size of record in bytes
int recordsPerBlock; // num records that can fit in one block unspanned
int[] blocksTemp; //number of blocks in a given temporary file
int totalBlocks; // number of blocks in all temporary files (unspanned)
int runBuffers; /*number of buffers that are still processing data for
a given run in a merge pass */
String inFile; // name of input file
String outFile; //name of output file
SortingBuffers memBuffers; // instance of class used as our buffer in sorting
FileInputStream[] inArray; //in temp files streams;
FileOutputStream[] outArray; //out temp file streams
static final char PAD_BLOCK_CHAR = '\n'; /*
character used to fill to end of
an unspanned block */
}
/**
This class is used to manage buffer storage memory during the execution of
the n-way merge sort algorithm. It also has methods to implement a priority
queue so that it is easy to both sort records using heapsort and merge
records during a merge pass. (Happy refactoring!)
*/
class SortingBuffers
{
/**
Create a buffer to hold nBlocks of aproximately bSize records
each of rSize byte and terminated by the padBlock char.
@param rSize -- record size bytes
@param bSize -- number of records in a block (actually allocate one more
than this)
@param nBlocks -- number of blocks in our buffer
@param padChar -- character used to terminate a record.
*/
SortingBuffers(int rSize, int bSize, int nBlocks, char padBlock)
{
array = new char[nBlocks*(bSize+1)][rSize];
mergeRecord = new int[nBlocks];
lastRecord = new int[nBlocks];
bufferSize = bSize;
recordSize = rSize;
numBlocks = nBlocks;
padBlockChar = padBlock;
currentSize = 0;
sortMode= true;
oldRow = 0;
newRow = 0;
oldCol = 0;
newCol = 0;
}
/**
Used during the sort phase of the n-way merge sort algorithm, when
we have used up our buffer space. We write the contents of our buffer
out to disk and keep track of how many blocks we wrote. Note records
written out in a sorted fashion as the buffer is a priority queue
and to write a record out we delete fromt his queue.
@param blockSize - size of a block
@param out - file to write our data to
@return - number of blocks we wrote.
*/
int dumpOutputStreamUnspanned(int blockSize, FileOutputStream out)
throws IOException
{
char[] record;
int bytesLeft = blockSize;
int blkCnt = 0;
while((record=deleteMin()) != null)
{
if(bytesLeft < recordSize)
{
for(int i = 0; i < bytesLeft; i++)
out.write(padBlockChar);
bytesLeft = blockSize;
blkCnt ++ ;
}
for(int i=0; i < recordSize; i++)
{
out.write(record[i]);
}
bytesLeft -= recordSize;
}
blkCnt++;
for(int i = 0; i < bytesLeft; i++)
out.write(padBlockChar);
return blkCnt;
}
/**
Write out numbytes from the storage buffers to the given output stream.
Bytes are read starting from oldRow, oldCol in the array.
After the merge phase is over the SortingBuffers object is used as
essentially a 1D array of bytes to convert the final temp file we
got to the desired (potentially) spanned output file. This method
is used druing that conversion process.
@param numBytes -- number of bytes to write out in a spanned fashion
@param out -- stream to write to
*/
void dumpOutputStreamSpanned(int numBytes, FileOutputStream out)
throws IOException
{
for(int i=0; i < numBytes; i++)
{
out.write(array[oldRow][oldCol++]);
if(oldCol >= recordSize)
{
oldCol = 0;
oldRow++;
if(oldRow >= array.length)
oldRow = 0;
}
}
}
/**
Read an unspanned block into the given input stream
@param blockSize -- size of a block in bytes
@param bufNum -- number input buffer (block) to read block into
@param in -file to read block from
@return whether or not this record starts a new run
*/
boolean readUnspannedBlock(int blockSize, int bufNum, FileInputStream in)
throws IOException
{
if(blockSize > recordSize * bufferSize)
return false;
int j=bufNum*bufferSize+numBlocks;
mergeRecord[bufNum] = j;
int k=0;
char c;
try
{
for(int i = 0; i < blockSize; i++)
{
c = (char)in.read();
if(k > 0 || c != padBlockChar )
array[j][k++] = c;
if(k >= recordSize)
{
k=0;
j++;
}
}
}
catch(EOFException eof)
{
lastRecord[bufNum] = j;
return false;
}
lastRecord[bufNum] = j;
boolean oldMode = sortMode;
sortMode = true;
boolean b =
lessThan(array[mergeRecord[bufNum]], array[lastRecord[numBlocks-1]]);
sortMode =oldMode;
return b || mergeRecord[bufNum] == lastRecord[bufNum];
}
/**
Write the contents of the output block in an unspanned fashion.
Used during merge phase.
@param numRecords - number of records to write out in the block will write
@param blockSize - number of bytes in a block
@param out -stream to write data to
@return -true if successful
*/
boolean writeUnspannedBlock(int numRecords,
int blockSize, FileOutputStream out) throws IOException
{
if(blockSize < recordSize * numRecords)
return false;
int start=(numBlocks-1)*bufferSize+numBlocks;
int end = start + numRecords;
int byteCnt = 0;
for(int i = start; i < end; i++)
{
for(int j = 0; j < recordSize; j++)
{
out.write(array[i][j]);
byteCnt++;
}
}
while(byteCnt < blockSize)
{
out.write('\n');
byteCnt++;
}
lastRecord[numBlocks-1] = start-1;
return true;
}
/**
Used to read a character into buffer array at current offset into
buffer. Used in generating the final output file from n-way merge.
(i.e., converting unspanned temp file to spanned output file)
@param c - character to read into buffer.
*/
void add(char c)
{
array[newRow][newCol++] = c;
if(newCol == recordSize)
{
newCol = 0;
newRow++;
if(newRow == array.length)
newRow = 0;
}
}
/**
Adds the next record from the given supplied input buffer to the
priority queue of things to be merged (during merge phase).
@param bufNum -- which buffer to take the record from
@return true -- if record to add and add successful
*/
boolean addRecordHeap(int bufNum)
{
if(mergeRecord[bufNum]>=lastRecord[bufNum]) return false;
array[0][0] = (char)bufNum;
if((array[0] = insert(array[0])) == null) return false;
return true;
}
/**
Removes the smallest record from the merge priority queue and
and puts it in the output buffer.
@return - the index of which buffer the record we moved comes from
*/
int mergeRecord()
{
if(currentSize < 1 ) return -2;
char[] tmp = deleteMin();
int bufNum = (int)tmp[0];
int outIndex = ++(lastRecord[numBlocks-1]);
tmp = array[outIndex];
int mergeIndex = mergeRecord[bufNum]++;
array[outIndex] = array[mergeIndex];
array[mergeIndex] = tmp;
if(!addRecordHeap(bufNum))
return bufNum;
return -1;
}
/**
Turns sort mode on.
Whether our priority queue uses indirect addressing is determined by
whether we are in the sort phase (no) or merge phase (yes).
*/
void setSortMode()
{
sortMode=true;
}
/**
Turns sort mode off. (i.e., merge mode on)
Whether our priority queue uses indirect addressing is determined by
whether we are in the sort phase (no) or merge phase (yes).
*/
void setMergeMode()
{
sortMode=false;
}
/**
After having written a block of data to disk from the output buffer,
this sets the index of the last record of unwritten data to the
the first record in the output buffer.
*/
void resetLastBuffer()
{
lastRecord[numBlocks-1] = (numBlocks-1)*(bufferSize+1);
}
/**
This function was used for debugging purposes to see what the
current contents of the buffer was by drwaing it out using
character graphics.
*/
void drawBuffers()
{
int k = numBlocks;
for(int i = 0 ; i <array.length; i++)
{
if(i<10)System.out.print(" ");
System.out.print(""+i+":");
for(int j = 0; j < array[0].length; j++)
{
if(array[i][j] < 'A')
System.out.print(""+((int)array[i][j])+" ");
else
System.out.print(""+array[i][j]+" ");
}
if(i == k)
{
System.out.print("*");
k += bufferSize;
}
System.out.println("");
}
}
/*
HEAP RELATED FUNCTIONS
*/
/**
Inserts a new record into a priority queue
@param x - record to be inserted
@return - a reference to a records worth of char's that have now been
replaced by x.
*/
char[] insert(char[] x)
{
if(currentSize >= array.length - 1)
return null;
int hole = ++currentSize;
char[] tmp = array[hole];
for( ; hole > 1 && lessThan(x, array[ hole/2 ]); hole /=2 )
array[ hole ] = array[ hole / 2];
array[hole]=x;
x=tmp;
return x;
}
/**
Used to restore the heap property of priority queue
after a node has been deleted.
@param hole - index to start percolating down from (might
use other than one in a build heap type setting)
*/
void percolateDown(int hole)
{
int child;
char[] tmp = array[ hole ];
for( ; hole * 2 <= currentSize; hole = child )
{
child = hole *2;
if( child != currentSize &&
lessThan(array[child + 1], array[child]) )
child++;
if(lessThan(array[ child ], tmp) )
array[ hole ] = array[ child ];
else
break;
}
array[ hole ] = tmp;
}
/**
Delete lowest priority entry from priority queue and
return a reference to it.
return -- reference to what had been smallest thing in queue
*/
char[] deleteMin()
{
if(currentSize < 1)
return null;
char[] tmp = array[0];
array[0] = array[1];
array[1] = array[currentSize];
array[currentSize] = tmp;
currentSize--;
percolateDown( 1 );
return array[0];
}
/*
USEFUL AUXILIARY FUNCTIONS
*/
/**
Check which record is lexicographically less than the other
This code assume equal length arrays. Also, uses indirect
addressing to get the record when not in sort mode.
@param arr1 - either an index to a record or an actual record
@param arr2 - either an index to a record or an actual record
*/
boolean lessThan(char[] arr1, char[] arr2)
{
if(!sortMode)
{
arr1 = array[mergeRecord[(int)(arr1[0])]];
arr2 = array[mergeRecord[(int)(arr2[0])]];
}
if(arr1.length != arr2.length) return false;
int i;
int length = arr1.length;
for(i = 0; i < length; i++)
{
if(arr1[ i ] != arr2[ i ]) break;
}
if(i != length && arr1[ i ] < arr2[ i ]) return true;
return false;
}
char[][] array; // used to hold buffer data
int currentSize; // current size of priority queue
int bufferSize; // number of records in block
int numBlocks; // number of blocks in the buffer
int recordSize; // number of bytes in a record
int[] mergeRecord; /*for each buffer during merge phase index of
record currently being merged */
int[] lastRecord; /*index of the last record that has been read into a
buffer */
/*
Next variables are used when writing spanned data from buffer after
merge phase over to keep track of our location in 2D-array
*/
int oldRow;
int oldCol;
int newRow;
int newCol;
char padBlockChar; //character to write out to fill a full unspanned block
boolean sortMode; /*used to turn on/off indirect addressing for our
priority queue depending on whether we are in sort
or merge phase */
}