Chris Pollett >
Old Classes
>
CS157b
( Print
View )
Grades:
[Sec1] [Sec2]
Submit:
[Sec1] [Sec2]
Course Info:
[Texts & Links]
[Topics]
[Grading]
[HW Info]
[Exam Info]
[Regrades]
[Honesty]
[Announcements]
HW Assignments:
[Hw1]
[Hw2]
[Hw3]
[Hw4]
[Hw5]
Practice Exams:
[Mid1]
[Mid2]
[Final]
HW2 Solutions Page
1. Answers to this question will vary depending on what your three separate ER Diagrams looks like. In any case, though, as this problem is supposed to be illustrating view integration each of your diagrams should probably have at least three entities and there should be some overlap so I can see how you handled doing the merge. Below are the diagrams that I came up with:
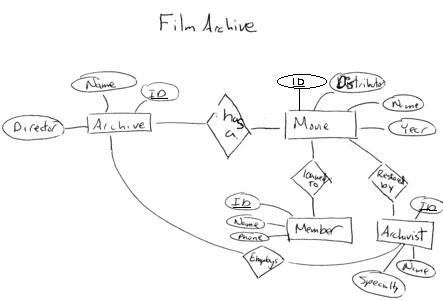
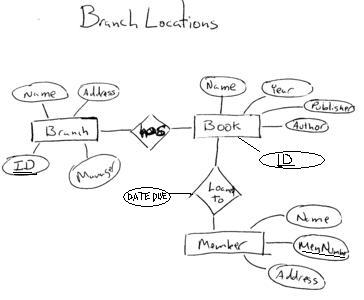
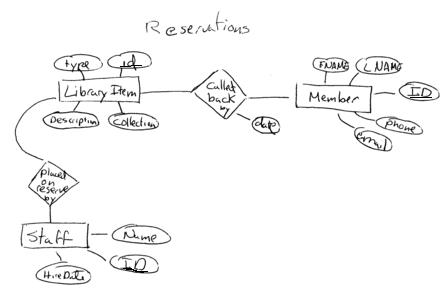
Given these diagrams I came up with the following integrated diagram:
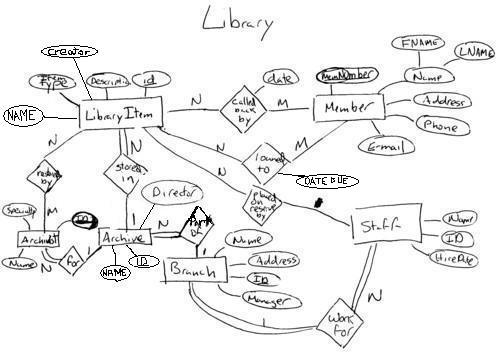
Some points on my preliminary and final diagram. In the preliminary diagrams I didn't put constraints on relationships so as to avoid conflicts among constraints when I did the integration. In the final diagram both Movie and Book have just been modeled as the LibraryItem which has a type attribute. If we had been allowed to use EER diagrams I might have used subtyping here. On the other hand, I had two distinct entities Archivist and Staff rather than one entity with a role attribute. This was because I envisioned the roles of these two entities to be fairly distinct. Lastly, notice how the merging of Member's name attribute was handled so that it is now a composite attribute in the merged diagram. Elsewhere in the diagram as well, I had to make names match between the different original diagrams. Also, since the left-right flow of the diagram is different in the merged result, I renamed some of the relationships to make it clearer what they meant even though they didn't cause any of the book listed problems with the old names. 2. To convert the above diagram to tables. We first make each entity a table, adding the attributes from the orginal diagram. Then we add attributes to these tables for the 1:N relationships. Finally, we map the N:M relationships to their own tables. This gives: LIBRARY_ITEM ID(K1) Description ArchiveID(F_K3) Name Creator StaffID (F_K3) MEMBER MemNumber(K2) FName LName Address Phone E-mail ARCHIVE ID(K3) Name Director ArchivistID (F_K6) BranchID (F_K4) BRANCH ID(K4) Name Address Manager STAFF ID(K5) Name HireDate BranchID (F_K4) ARCHIVIST ID(K6) Name Specialty RESTORED_BY ArchiveID(F_K5) ItemID(F_K1)(K7) CALLED_BACK_BY MemberNum(F_K2) ItemID(F_K1)(K8) Date LOANED_TO MemberNum(F_K2) ItemID(F_K1)(K9) DateDue The numbers Ki and F_Ki next to some attributes indicates key i and foreign key that depends on key i. It makes sense to have hash indexes on K1-K6 as they are the primary keys of their corresponding tables. As they are IDs their value does not contain any info so we would probably not order these tables by their value. On the other hand, it would make sense to order tables 1, 3-6 by their Name attributes. So we could add a clustering index on name for these tables. For the multiple attribute keys of the last three tables we might use either partitioned hashing or grid files for their key attributes. We might also use this for the first name last name combination in table 2. We might also add secondary indexes or use B+-tree based indexes on attributes frequently joined with other tables such as StaffID and ArchiveID in LIBRARY_ITEM, ArchivistID and BranchID in ARCHIVE, and BranchID in STAFF. 3. Answers on this question will vary. You should get at least two tables and all attributes must be assigned to some table in your partitioning. This means that cost and movieName should be in different tables as they are in distinct queries that we are supposed to use to split the original table. Beyond this your answer should be backed up with an explanation. My suggested partitioning is: M1(movieID, cost) and M2(movieID, movieName, year, distributor, year, mediaType, acquireDate). My reasoning is as follows: The first query is likely to be the most common. People rent a tape, it gets scanned, and the query is run. So it is advantageous to keep this table as simple as possible. The reason why I put so many attributes in the second table and not have a third table is that to find out the release date based on movieName alone is likely to return several dates. The user of this query would probably want to know the attribute such as year, distributor, and mediaType to be able to determine which acquireDate was the relevant one. We leave movieID in M2 so that the tables can easily be joined into the original one. 4. Answers for this question should come with explanations. (a) The orginal query was: SELECT DISTINCT Container.TrackNo FROM Container, Ship WHERE Container.shipID=Ship.ID AND (Container.value > 100000 OR Container.value < 500000) Note the second condition in the where clause evaluates to true so can be eliminated. Container.shipID is presumably a foreign key from Ship. Since we use the keyword DISTINCT and don't project any columns from Ship, the Ship Table in the FROM clause is not used. So an improved query would be SELECT TrackNo FROM Container; As TrackNo is presumably a key from Container we do not need the DISTINCT keyword, and not having it would potentially avoid a sort. (b) The original query was: SELECT TrackNo FROM Ship_Container WHERE 0.5*value > SELECT AVG(value) FROM Ship_Container; We note a couple things: (1) Ship_Container is a view and the attributes value and TrackNo come only from Container. (2) Since there is no where clause AVG(value) over Ship_container is the same as AVG(value) over just Container. The nested query does not depend on the outer query, i.e., it is uncorrelated on an aggregate, so would not present any problems to an optimizer. This suggests the following improved query: SELECT TrackNo From Container WHERE value > SELECT 2*AVG(value) FROM Container; Note: we moved the .5 to the subselect so as to help the query optimizer decide to use the index on value for the other side of the where expression. (c) The original query was: SELECT TrackNo FROM Container WHERE NOT ( value = SELECT MAX(Container.value) FROM Container); We note: (1) not equal to a maxmimum value is the same as less than the maximum. (2) again the subselect is uncorrelated. This suggest the improvement: SELECT TrackNo FROM Container WHERE value < SELECT MAX(Container.value) FROM Container; (d) The original query was: SELECT Ship.name FROM Ship, Container WHERE Ship.ID = Container.shipID AND Ship.name LIKE 'Sea%' AND Container.value =1234; For this problem, it is quite likely that the query optimizer would do the right thing as is. However: we note: (1) To calculate the result we do use both Ship and Container so can't get rid of either. (2) If order of tables matters for query optimizer, we probably want Ship before Container in FROM clause. (3) If the query optimizer is not clever the WHERE clause will be evaluated from left to right when converted to a query tree so want things that narrow search space earlier. (4) Ship has a lot fewer rows (1000) than Container (10,000,000) and it quite likely that ship names that begin with Sea are rarer than Container with value 1234. However, the Container does have a cluster index on value. If we assume both kinds of rows have about the same blocking factor, say 100 rows ber block, then Ship would be 10 blocks long and Container would be 100,000 blocks long. Binary searching for 1234 using the clustering inder would probably take at least log_2 100,000 or approx. 17 block accesses, which is more than searching all the blocks of Ship. This suggests the following revised query: SELECT Ship.name FROM Ship, Container WHERE Ship.name LIKE 'Sea%' AND Container.value=1234 AND Ship.ID = Container.shipID; 5. Below is the script I used to create the tables from part 2: // hw2.sql -- a script to create the tables for hw2 problem 5 Fall 2002. DROP TABLE MOVIE; CREATE TABLE MOVIE ( movieID NUMBER(9), movieName VARCHAR2(100), distributor VARCHAR2(100), year NUMBER(4), mediaType INTEGER, acquireDate DATE, cost NUMBER(8,2) ); DROP TABLE M1; CREATE TABLE M1 ( movieID NUMBER(9), cost NUMBER(8,2) ); DROP TABLE M2; CREATE TABLE M2 ( movieID NUMBER(9), movieName VARCHAR2(100), distributor VARCHAR2(100), year NUMBER(4), mediaType INTEGER, acquireDate DATE); Next we have the program Generate.java used to generate the thousand rows of random data. // Generate.java -- program used to generate movie data for CS157b Hw2 Problem 5. import java.util.*; import java.io.*; /** This class consists of a bunch of public static methods used to generate random row data for the CS157B HW2 Problem 5. Typically one would run this program from the command line with a line like: java Generate Movie.DAT 1000 here Movie.DAT is the file to write the random data to and 1000 is the number of rows of random data to generate. @author Chris Pollett @version 1.0.2002 */ public class Generate { /** Creates numRows rows of random Movie Table data and save it in a file named by String movie. @param movie -- filename to store random row data in @param numRows -- number of rows of data to create */ public static void createData(String movie, int numRows) { try { PrintStream outMovie = new PrintStream( new FileOutputStream(movie)); for(int i = 0; i < numRows; i++) { StringBuffer bMovie = new StringBuffer(BUFLEN); createRow(i, bMovie); outMovie.println(bMovie.toString()); } outMovie.close(); } catch(IOException ie) { ie.printStackTrace(); } } /** Creates one row of random Movie table data given the parameters supplied. @param num -- movieID od row to create @param bMovie -- presumed empty StringBuffer in which to append random row. */ public static void createRow (int num, StringBuffer bMovie) { int i, preDigit; String digit, id = (new Integer(num)).toString()+"\t"; // Keep format of ID 9 digits. for(i=0; i < IDLEN - id.length(); i++) { bMovie.append("0"); } bMovie.append(id); for(i=0; i < ENDRSTRINGLEN; i++) { switch(i) { case ENDMOVIE: case ENDDISTRIB: case ENDYEAR: case ENDMEDIA: case ENDDATE: bMovie.append("\t"); break; case ENDDAY: bMovie.append("-"); break; case ENDMONTH: bMovie.append("-20"); break; case PERIOD: bMovie.append("."); break; case DAY: preDigit = (int)(Math.random()*28)+1; //Assume all months 28 days if(preDigit <10) // Keep format of day two digits bMovie.append("0"); digit = (new Integer(preDigit) ).toString(); bMovie.append(digit); break; case MONTH: preDigit = (int)(Math.random()*12)+1; if(preDigit <10) // Keep format of month two digits bMovie.append("0"); digit = (new Integer(preDigit) ).toString(); bMovie.append(digit); break; default: preDigit = (int)(Math.random()*9); digit = (new Integer(preDigit) ).toString(); bMovie.append(digit); break; } } } /** Calls createData witht the command line arguments to generate the random data @param args - array of command line arguments. */ public static void main (String [] args) { if(args.length < 2) { System.out.println("To use:"); System.out.println("java Generate M0 numRows"); System.out.println("where M0 is the file you'd like data written to"); System.out.println("and numRows is how many rows you'd like generated."); } else createData(args[0], Integer.parseInt(args[1])); } public static final int IDLEN = 9; //length of a movieID public static final int BUFLEN = 150; /* approximate length of one row of buffered data, so StringBuffer does not need to be resized. */ /* The next constants are used to define column positions of various things in a row of random data */ public static final int ENDMOVIE = 50; public static final int ENDDISTRIB = 100; public static final int ENDYEAR = 105; public static final int ENDMEDIA = 108; public static final int DAY = 109; public static final int ENDDAY=110; public static final int MONTH = 111; public static final int ENDMONTH=112; public static final int ENDDATE=115; public static final int PERIOD=117; public static final int ENDRSTRINGLEN=120; } Before we can actually do our test we need to bulk load the data generated by the above into the three tables. Below are the control files I used with the sqlldr: /* hw2.ctl Control file to load data into table Movie for CS157B Fall 2002 HW2 Problem 5 Notice how we spcify the format for DATE */ LOAD DATA INFILE Movie.DAT INTO TABLE MOVIE FIELDS TERMINATED BY '\t' (movieID, movieName, distributor, year, mediaType, acquireDate DATE 'dd-mm-yyyy', cost) /* hw2m1.ctl Control file to load data into table M1 for CS157B Fall 2002 HW2 Problem 5 Notice we skip the field we don't want using FILLER */ LOAD DATA INFILE Movie.DAT INTO TABLE M1 FIELDS TERMINATED BY '\t' (movieID, movieName FILLER, distributor FILLER, year FILLER, mediaType FILLER, acquireDate FILLER, cost) /* hw2m2.ctl Control file to load data into table M2 for CS157B Fall 2002 HW2 Problem 5 Notice we skip the field we don't want using FILLER */ LOAD DATA INFILE Movie.DAT INTO TABLE M2 FIELDS TERMINATED BY '\t' (movieID, movieName, distributor, year, mediaType, acquireDate DATE 'dd-mm-yyyy', cost FILLER) Below is my code to generate statistics about the two kinds of queries: //partition.java -- program to generate statistics for CS157b Fall 2002 Hw2 problem 5 import java.util.*; import java.io.*; import java.sql.*; /** This class has a collection of public static methods useful for generating the two kinds of queries from CS157B HW2 Fall 2002 Should be run from the command line like: java partition numTrials where numTrial is an integer number of trials used in calculating the average query time. @author C. Pollett @version 1.0.2002 */ public class partition { /** Calculate the average time over numTimes trials to perform select cost from tableName where movieID= random ID @param tableName -- name of table to perform query on @param numTimes -- number of trial for query @return -- average time to perform query over numTimes trials. */ public static double testCostMovieID(int numTimes, String tableName) throws SQLException { double totalTime =0; long startTime; // set up the connection to the database Connection conn = DriverManager.getConnection(connectString,login, password); // set up a statement int numRows = getCount(conn, tableName); for(int i = 0 ; i < numTimes; i++) { String randID = (new Integer((int)(Math.random()*numRows))).toString(); while (randID.length() < IDLEN) //slow but works make sure ID is IDLEN long randID = "0"+ randID; String query = "select cost from "+tableName+" where movieId='" + randID +"'"; Statement stmt = conn.createStatement(); startTime = System.currentTimeMillis(); ResultSet rset = stmt.executeQuery(query); rset.next(); double cost = rset.getDouble(1); totalTime += System.currentTimeMillis() - startTime; stmt.close(); } conn.close(); return totalTime/numTimes; } /** Calculate the average time over numTimes trials to perform select movieName, distributor, year, mediaType, acquireDate from tableName where movieName= random name in table @param tableName -- name of table to perform query on @param numTimes -- number of trial for query @return -- average time to perform query over numTimes trials. */ public static double testMovieName(int numTimes, String tableName) throws SQLException { double totalTime =0; long startTime; // set up the connection to the database Connection conn = DriverManager.getConnection(connectString, login, password); // set up a statement int numRows = getCount(conn, tableName); for(int i = 0 ; i < numTimes; i++) { String randMovieName = getRandMovieName(conn, tableName, numRows); //select a random movie in table String query = "select movieName, distributor, year, mediaType, acquireDate"+ " from "+tableName+" where movieName='" + randMovieName +"'"; Statement stmt = conn.createStatement(); startTime = System.currentTimeMillis(); ResultSet rset = stmt.executeQuery(query); while(rset.next()) //get data on all movie's with that name { String movieName = rset.getString(1); String distributor = rset.getString(2); int year = rset.getInt(3); int mediaType = rset.getInt(4); java.sql.Date acquireDate = rset.getDate(5); } totalTime += System.currentTimeMillis() - startTime; stmt.close(); } conn.close(); return totalTime/numTimes; } /** This functions returns the number of rows tableName has. @param conn -- current database connection @param tableName -- name of table to count rows of @return -- number of rows in the table tableName */ public static int getCount(Connection conn, String tableName) throws SQLException { String query = "select count(*) from "+tableName; Statement stmt = conn.createStatement(); ResultSet rset = stmt.executeQuery(query); rset.next(); int numRows= rset.getInt(1); stmt.close(); return numRows; } /** This method return a random movieName that is in the table with ID less than numRows. @param conn -- current database connection @param tableName -- name of table to slect a movieName from @param numRows -- select a movieName with ID less than this value @return -- a random movieName that exists in the table */ public static String getRandMovieName(Connection conn, String tableName, int numRows ) throws SQLException { String randID = (new Integer((int)(Math.random()*numRows))).toString(); while (randID.length() < IDLEN) //slow but works make sure ID is IDLEN long randID = "0"+ randID; String query = "select movieName from "+tableName+" where movieId='" + randID +"'"; Statement stmt = conn.createStatement(); ResultSet rset = stmt.executeQuery(query); rset.next(); String movieName = rset.getString(1); stmt.close(); return movieName; } /** Main driver method for this class. Generate the statistics based on the supplied number of trials from the command line @args -- command line argument qith number of trials */ public static void main (String [] args) { if(args.length < 1) { System.out.println("To use:"); System.out.println("java partition numTests"); System.out.println("where numTests is the number of query trials"); System.out.println("to the database used to figure out average times"); System.exit(1); } try { DriverManager.registerDriver( new oracle.jdbc.OracleDriver()); System.out.println("Generating statistics about how long it to took to process:\n\n"); System.out.println("select cost from MOVIE where movieID= randomRow"); System.out.println("Number of trials: " + args[0]); System.out.println("Average time in millisecond: " + testCostMovieID(Integer.parseInt(args[0]), " MOVIE ")+"\n\n"); System.out.println("select cost from M1 where movieID= randomRow"); System.out.println("Number of trials: " + args[0]); System.out.println("Average time in millisecond: " + testCostMovieID(Integer.parseInt(args[0]), " M1 ")+"\n\n"); System.out.println("select movieName, distributor, year, mediaType, acquireDate from MOVIE"+ " where movieName= randomName in table"); System.out.println("Number of trials: " + args[0]); System.out.println("Average time in millisecond: " + testMovieName(Integer.parseInt(args[0]), " MOVIE ")+"\n\n"); System.out.println("select movieName, distributor, year, mediaType, acquireDate from M2"+ " where movieName= randomName in table"); System.out.println("Number of trials: " + args[0]); System.out.println("Average time in millisecond: " + testMovieName(Integer.parseInt(args[0]), " M2 ")+"\n\n"); } catch (SQLException se) { System.out.println("SQL Exception:"); se.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } public static final int IDLEN = 9; //length of a movie ID public static final String connectString = "jdbc:oracle:thin:@sigma.mathcs.sjsu.edu:1521:cs157b"; //string to connect to a database public static final String login = "login"; // login to connect to database public static final String password = "pass"; // password to connect to database } The output I got when I ran java partition 100 was: Generating statistics about how long it to took to process: select cost from MOVIE where movieID= randomRow Number of trials: 100 Average time in millisecond: 151.11 select cost from M1 where movieID= randomRow Number of trials: 100 Average time in millisecond: 145.5 select movieName, distributor, year, mediaType, acquireDate from MOVIE where movieName= randomName in table Number of trials: 100 Average time in millisecond: 248.19 select movieName, distributor, year, mediaType, acquireDate from M2 where movieName= randomName in table Number of trials: 100 Average time in millisecond: 249.57 The size of M1 was roughly 1/10 the size of Movie and as the above results indicate there was some savings in time when the 1st kind of query was run on M1. On the other hand the average for the second query on M2 was actually slightly worse than that for Movie. This probably has to do with me movie the mouse around more during this query. The two tables in this case were of almost identical size so it is not too surprising there there wasn't a noticeable difference in this case.