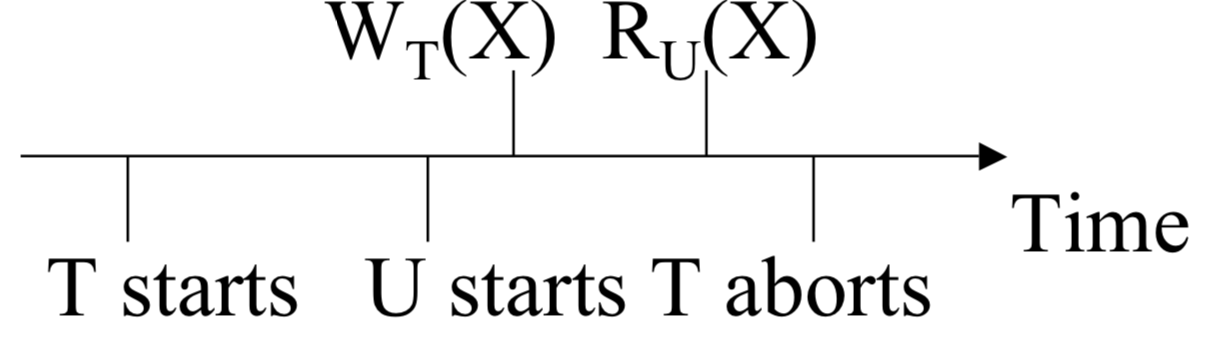Last week, we began looking at concurrency control in databases.
The idea is we have a database scheduler that receives operations from various transactions and tries to determine the order in which to execute them.
We assume that each transaction by itself (if no other transactions running) would map the database from a consistent state to a consistent state.
If we imagine that we fix some order on the transactions, then executed each transaction in turn from start to completion before executing the next, we would
then map the database from a consistent state to a consistent state. This kind of schedule for the operations we said was a serial schedule.
Typically, to maximize the use of time on our DB we want to allow our transaction operations to interleave, but we would like to have their effect on the database be as if a serial schedule had been done.
We defined various notions of serializability to achieve this.
We then showed that by using two phase locking (2PL), we could achieve conflict serializable schedules.
We looked at different variations on lock types to try to increase the allowed interleaving of DB operations, but still give conflict serializable schedules.
We said it was the job of the lock scheduler in the DBMS to handle who gets locks for what and when (not the transaction programmer).
Today, we start by looking at the lock table this scheduler might use.
A Lock Table Entry
Group mode is used as a quick test on what locks are currently held.
`S` - indicates only shared.
`U` - some shared, one update.
`X` - only one exclusive lock.
Waiting indicates if some transaction is waiting for a lock on A.
Handling Locking
For `T` to lock `A`:
The DBMS first checks, "Does there exists an entry for `A`?"
If no, the DBMS creates it, adds the transaction to the entry, and grants the lock.
If yes, the DBMS checks the group mode:
if the mode is `S` or `U` and the request is a shared lock, the DBMS grants it, and adds the transaction to the list.
If the mode is `S` and the request is `U`, the DBMS grants the lock request, and adds the transaction to the list. The mode is switched to `U`.
If the mode is `X` or `U` and the request is `S`, `X`, or `U`, the DBMS denies the request, and adds the
transaction to the list, but with Wait? having value "yes".
Handling Unlocking
For `T` to unlock `A`:
`T`'s entry in the list for A is deleted.
If `T` had a `U` lock then the DBMS changes the group mode to `S` if there are any transaction still in the list.
If `T` had value `U` or `X` and Waiting is "yes", then the DBMS can grant the lock to one of the waiting transactions.
This grant can be based on one of the following strategies:
First come first serve.
Priority to shared locks -- First come first serve to shared lock, then updates, then exclusive locks.
Priority to upgrading -- if `T` has `U` and is waiting for an `X`lock, grant `T` first. Otherwise, follow one of the previous strategies.
Quiz
Which of the following statements is true?
To make an archive dump we have to shutdown the database so that it can't receive transactions.
A serial schedule might not be conflict serializable.
Using 2PL guarantees conflict serializable schedules.
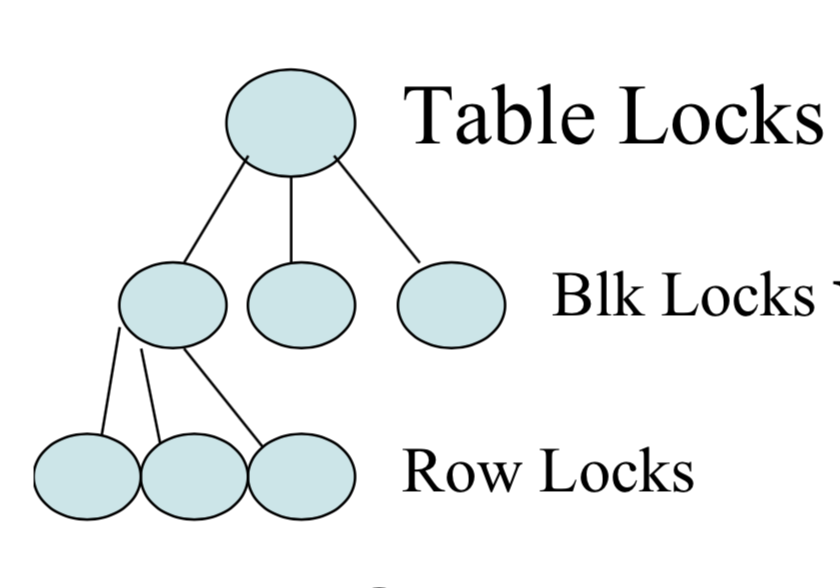
Lock Granularity
We want to be able to have hierarchies of possible locks --
from locks on only one element to a single lock for many elements.
These hierarchies will typically come in the form of trees.
For instance, a table lock would be higher in such a
tree structure than a block level lock, which is turn higher than a row lock.
As another example, we might want to be able to lock single index
entries or whole subtrees of a B-tree.
An example of the advantage of having big locks is if a transaction
is frequently accessing a table it is faster to only do one lock than one for each access.
Usually if the DBMS sees you doing multiple reads on a table, it tries to increase
the granularity of the shared lock you have.
Table Locks
One way to manage such hierarchies is to introduce new kinds of lock called warning locks (Gray, Putzolo, Traiger 1976),
`IS` and `IX`, in addition to `S` and `X`. The `I` indicates intention to acquire a lock. (The idea is similar to update locks)
Let's assume we have three levels of locks: table, block, row.
Let `T` be the tree of all locks currently held on table `S`.
Start at root of hierarchy. If we are at the element we want request either an `S` or `X` lock.
If not traverse down the tree until we get to the element we want. For each node on this path, we request an `IS` or `IX` lock.
The idea is if we want to get the lock exclusive for a row `A`, we first get an `IX` lock for the table `A` so no one can get a shared lock for
the whole table which we might want to modify. Similarly, we get the `IX` lock for the block `A` belongs to prevent someone else getting a shared lock on
the whole block.
Warning Lock Compatibility Matrix
Here's what the compatibility matrix looks like:
Lock Requested
IS
IX
S
X
Lock Held in Mode
IS
Y
Y
Y
N
IX
Y
Y
N
N
S
Y
N
Y
N
X
N
N
N
N
Phantoms and Handling Insertions Correctly
Notice in our locking scheme we can only lock items that already exist.
Consider the query where we sum the lengths of all movies made by Disney.
While we are performing this query someone might insert a row with a Disney movie.
If we repeat our query in the same transaction we might see a different sum.
This problem tuple is called a phantom tuple.
The solution to the problem is to require locking the whole table for reads or writes,
but this come with a heavy performance hit.
The Tree Protocol (Silberschatz Kedem 1980)
Standard locking protocols make it very hard to do concurrency when doing locking with B-trees.
The problem is we would typically need to lock a whole path down the tree in case
the tree changes during an update. This prevents other people from looking at the tree.
Instead, to get concurrency for B-trees, we don't use two phase locking and:
a transaction's first lock in the tree may be at any node of the tree
(typically lock first node that could be changed by your transaction.)
subsequent locks can be obtained iff the transaction has the parent lock.
nodes can be unlocked at any time
a transaction may not relock a node it has released.
It turns out if we use this protocol for our tree structures, then transaction operations will be serializable
(you can prove this by induction on the number of nodes in the tree).
Other Concurrency Control Techniques
Besides locking there are two other common methods for doing concurrency control:
timestamping -- give each transaction and database element a timestamp and compare these
to determine if the schedule is equivalent to the serial schedule given by the transactions' timestamps. (This
idea originated in Bernstein Goodman 1980)
validation -- also uses timestamps but will yield schedules equivalent to the serial schedule
give by transaction commit times. (This idea is due to Kung and Robinson 1981)
We'll focus on the first technique.
Timestamps
We'll write `TS(T)` to denote a number(timestamp) assigned by the scheduler to transaction.
This number must be such that later transactions receive a higher number.
Such numbers could be based on the system clock or based on using a counter.
For each database element `X`, the scheduler also maintains the following numbers:
`RT(X)` -- timestamp of last `T` to read `X`,
`WT(X)` -- timestamp of last `T` to write `X`,
`C(X)` -- a boolean value saying whether the last transaction to write `X` has committed or not.
Physically Unrealizable Behaviors
Suppose each operation in a schedule executed at the time of the timestamp
assigned by the scheduler to the DB items.
Two problems could occur:
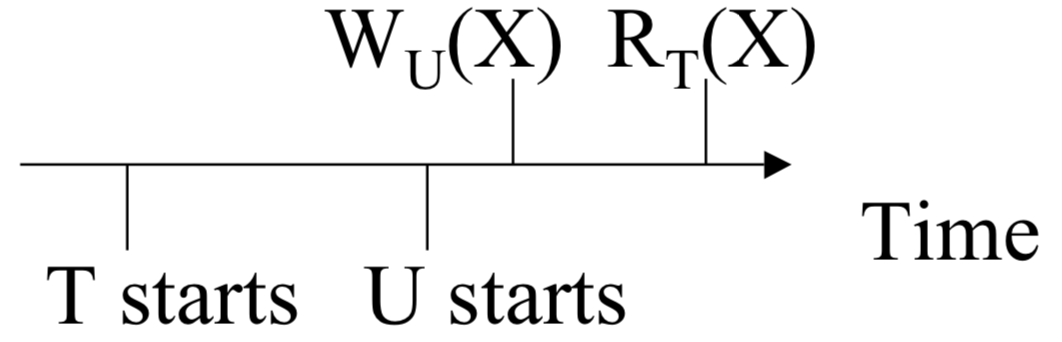
Read too late: (abort `T`)
Since `T` has an earlier timestamp than `U`, when it tries to read `X`, it should get a value written by a transaction
with an earlier timestamp then it. The scheduler in this case can look at `WT(X)` and notice that it is after `T` (as is `U`'s timestamp),
then force `T` to abort.
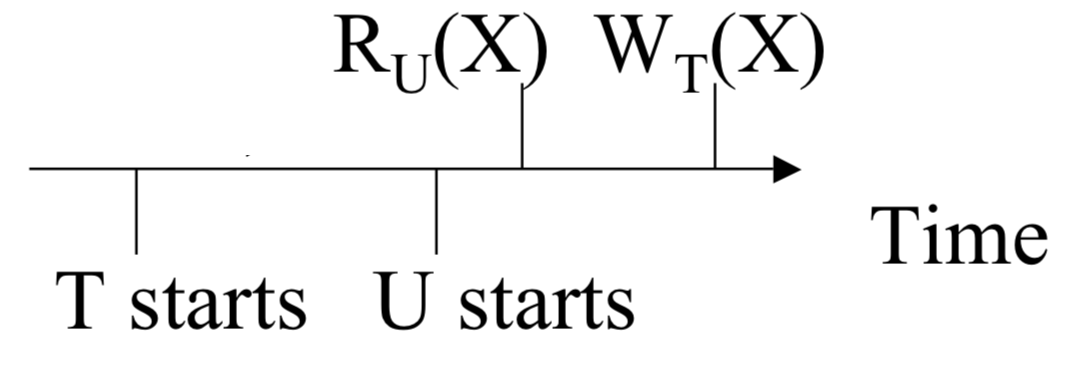
Write too late: (abort `T`)
Since `T` has an earlier timestamp than `U`, when it tries to write `X`, no transaction (namely `U`) with a higher timestamp should have read a value
for `X` from an earlier transaction than `T`. The scheduler in this case can look at `RT(X)` and notice that it is after `T` (as is set to `U`'s timestamp),
then force `T` to abort.
Problems with Dirty Data
The two problems of the last slide could be resolved by comparing `TS(T)` and `WT(X)` or `RT(X)`.
What is the `C(X)` used for? Consider the following sequence:
The value read by `U` is bogus since `T` aborted. This is called a dirty read.
We can check to make sure `C(X) = true`.
The scheduler maintains `C(X)` so works. The scheduler can delay `U`'s read until after `T` commits or aborts
to make a valid schedule.