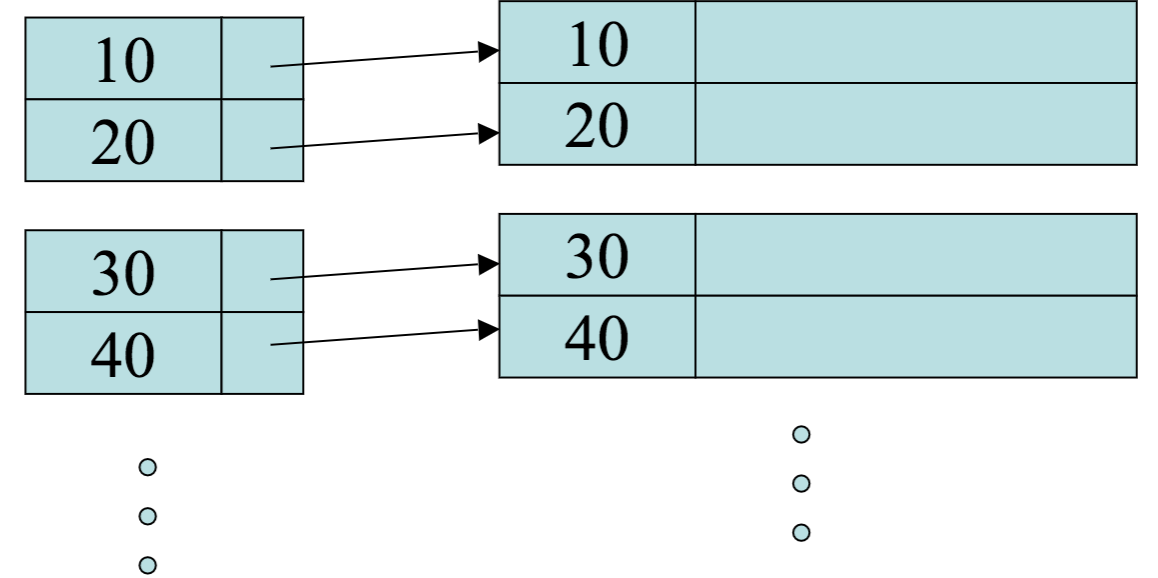
On Monday, we were talking about how blocks and records are identified by the DBMS using database addresses and in memory addresses.
We looked out how these addresses are converted to each other when a block is read into the DB buffer (in-memory) and when it is written
back to disk using swizzling/unswizzling.
We then considered the pros and cons of variable length record formats, what happens when records don't fit into a single block, and blobs.
We begin today by looking at how the basic record operations like insert, delete, update can be implemented.
Record Insertion
Suppose we want to insert a record into a DB table.
If the records in the table are not sorted, then we can:
Find a block `B` of table in question with space for the record.
If no such block exists, allocate a new block `B` and associate this new block with our table.
Add our record to block `B`.
The situation is harder if need to keep records sorted.
Record Insertion Sorted case
The idea is to find the block where we need insert.
If there is space there, then add the record.
We might need to slide records around within the relevant block and update its offset table.
If there is no space, then we could:
look at an adjacent block in the sorted order and try to find space there then redistribute records
create an overflow block.
Record Deletion
When we delete a record we may be able to reclaim its unused space.
We could try to slide records around so there is one big available space block.
We might also be able to get rid of any overflow blocks.
If this is not possible, then we should maintain an available space list in the block header.
That is, we designate one of the offsets in the block header as the available space offset.
This is null if there is no available space.
Otherwise, it gives the offset to an available record slot.
Available record slot header then have addresses to the next available record slot in the list, and so.
Once a record is deleted, we may need to place a tombstone on the record so that anything
pointing to the record knows it was deleted.
Record Update
For fixed length records, one can just overwrite the existing record.
For variable length records, one has all the problems associated with insert
and delete except that one doesn't have to have a tombstone.
If a variable length update record is shorter than the current record, we can:
overwrite the old record
add unused space to an available space list
If a variable length update record is longer than the current record, we can:
Try shifting records around in the block to free up space and write the new record.
If shifting doesn't work, we can try to create an overflow block.
Speeding Queries and Indexes
When we store records we need to store enough information so we can process queries like
SELECT *
FROM R
This kind of a query involves a whole scan of a table (so is often called a tablescan.)
It will run in time proportional to the number of rows in the table.
To do this, we need to store in the block header where in a block the records begin, and in the
record header of these records, which relation they belong to.
We might want to reserve whole cylinders for particular relations to speed things up.
A query like:
SELECT *
FROM EMP
WHERE name = 'John Smith';
only returns a small number of rows compared to the table.
Ideally, we want our queries to run in time proportional to the result set, not time time proportional to the
underlying tables.
To avoid doing table scans, for queries such as the above, we will use auxiliary data structures such as indexes.
In-Class Exercise
Come up with an example single table SQL query and conditions on the table in question so that the query
might take time longer than any constant times a tablescan.
We imagine our relations are stored in data structures within one or more files.
The data file (in some DBMSs like Mysql this is a real file, in sqlite all relations and their components and there stored in the same file)
is where the record data is stored.
An index file is a file containing (index key, pointer) pairs as records.
A index key usually consists of one or more column values that are found in the relation, and the pointer points to a record which has those column values.
A given relation might have several index files.
As index keys often let one find records quickly in the relation they are sometimes referred to as search keys.
Types of Indexes
Simple indexes on sorted file (no auxiliary index file needed)
Secondary indexes on unsorted files
B-trees
Hash tables
Sequential Files
In this kind of file we sort the file on the attributes of the index.
Particular values for the attributes of the index are called sort keys.
In the case of a sequential file, we don't need an auxiliary index file.
Keeping the file sorted means we can use binary search to quick find records which have a particular sort key.
Dense Indexes
Now that the records are sorted we can build on top of them a dense index.
That is, an index where we have one index entry per record.
More on Dense Indexes
Dense Indexes can be used for queries where we are searching by a particular value.
Given `K` we lookup `K` in the index using binary search
(`O(log n)` time where `n` is number of index entries) then follow the pointer there to the record.
Since the index only has (key,ptr) pairs rather than (key, lots of data), it will probably be much
smaller than original file and so possibly fit in memory. This can be used to save further I/Os.
Dense Index Example
Suppose `R` had 1,000,000 tuples and 10 fit into a block of 4096 bytes.
So R takes 100,000 blocks / 400 megabytes to store.
If the key is 30 bytes long and the record pointer 8 bytes then around 100 index entries can fit into a block.
So the index takes roughly 40 megabytes (10,000 blocks) to store.
This probably fits into main memory. If not, have only log (10000), roughly 13 or 14, accesses to look an entry.
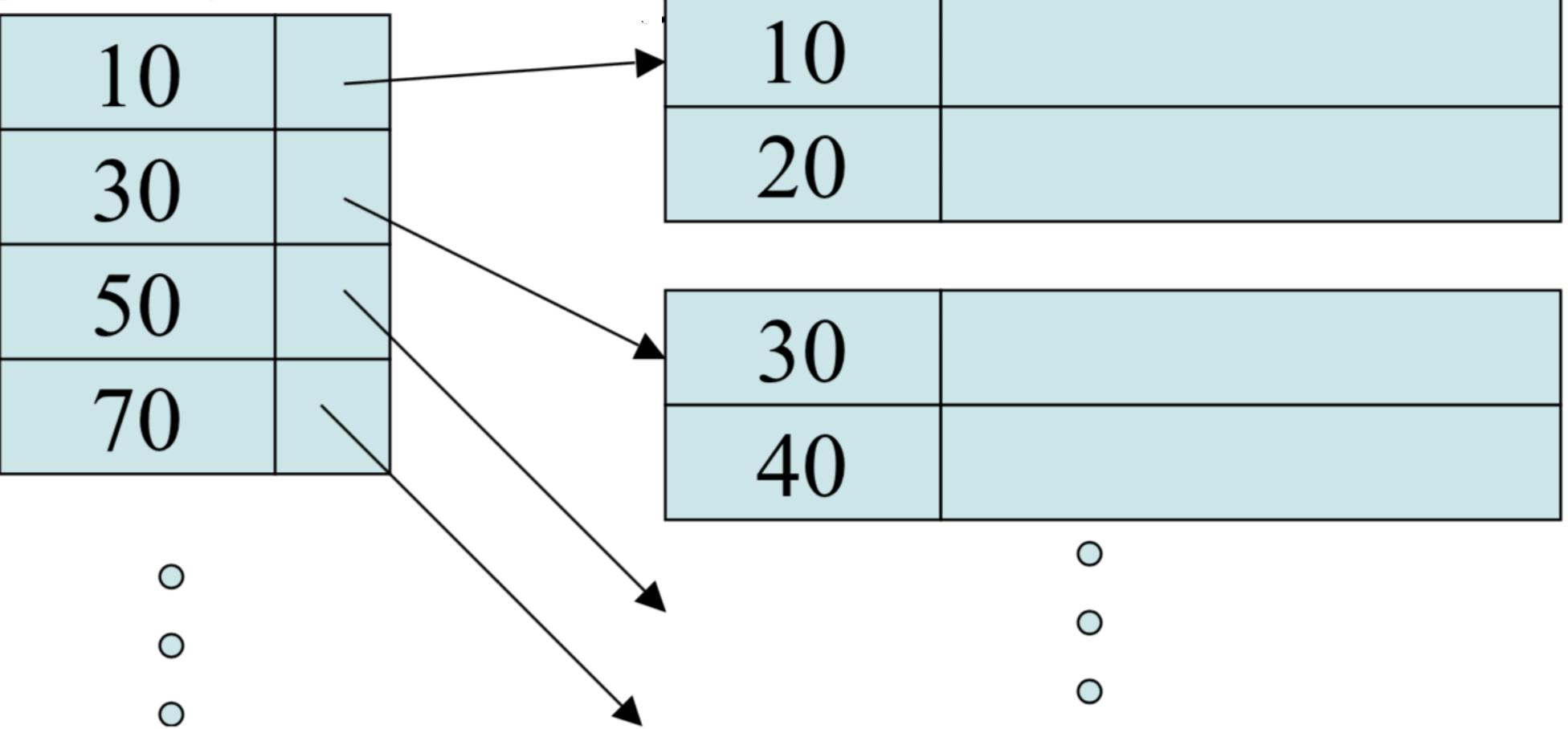
Sparse Indexes
These take less space but are a little slower than dense indexes.
Idea is we no longer have an index entry for every record, instead we have one entry per block of the original file:
Sparse Index Example
If `R` was 100,000 blocks, each storing 10 records as before, and again could store 100 index entries in a block,
then would only need 1000 blocks (4MB) to store this index.
On the other hand, with a dense index could answer questions of the form: "Is `K` in the file?" using only the index, without having to look up
the block containing `K` in the file itself.
Multi-Level Indexes
Since a sparse index itself can still take several blocks, one could imagine using a sparse index on a sparse index to look up the data.
In our previous example, the 1000 block index could have a 10 block sparse on it to help look up the correct block.
Multi-level indexes are fast, but can be a pain to update.