










Learning From Examples
CS156
Chris Pollett
Nov 29, 2017
CS156
Chris Pollett
Nov 29, 2017
Given a training set of `N` example input-output pairs
`(x_1, y_1), ..., (x_n, y_n)`,
where each `y_j` was generated by an unknown function `y=f(x)`, discover a function `h` that approximates the true function `f`.
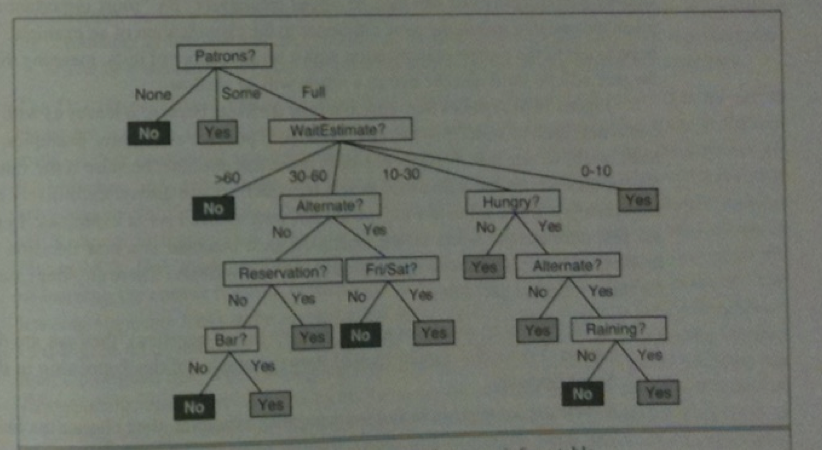
Here is an algorithm for coming up with a decision for a set of examples.
function Decision-Tree-Learning(examples, attributes, parent_examples) returns a tree
if examples is empty then return Plurality-Value(parent_examples)
else if all examples have the same classification then return the classification
else if attributes is empty then return Plurality-Value(examples)
else
A := argmax_(a in attributes)Importance(a, examples)
tree := a new decision tree with root test A
for each value v_k of A do
exs := {e : e in examples and e.A = v_k}
subtree := Decision-Tree-Learning(exs, attributes - A, examples)
add a branch to tree with label (A=v_k) and subtree subtree
return tree