Minimization, Closure Proofs, Regular Expressions
CS154
Chris Pollett
Feb. 13, 2013
CS154
Chris Pollett
Feb. 13, 2013
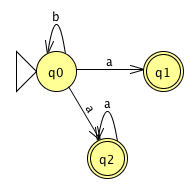
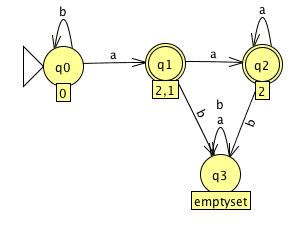
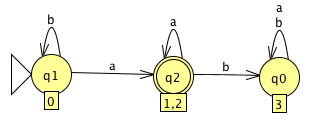
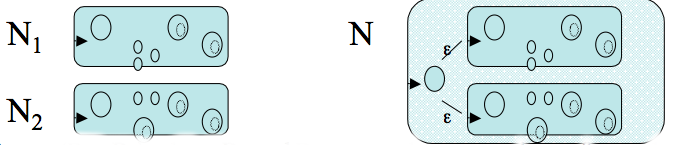
Problem 3. Apply the Cartesian product construction to (i) and (j) of exercise 1.6 to obtain an automata recognizing the union of their languages.
Answer. The following is an automaton which recognizes strings every odd position is a 1 (solving i):
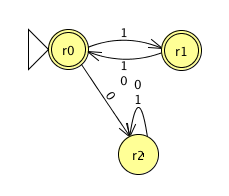
And the following is an automaton which recognizes those string which have at least two 0's and at most one 1 (solving j):
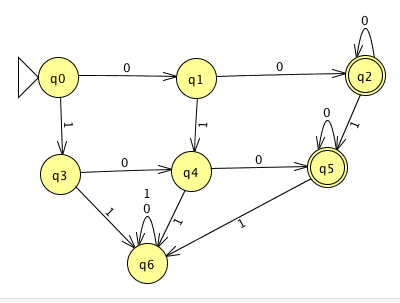
The machine coming from the Cartesian product construction where we consider only those states which are reachable from the start state is:
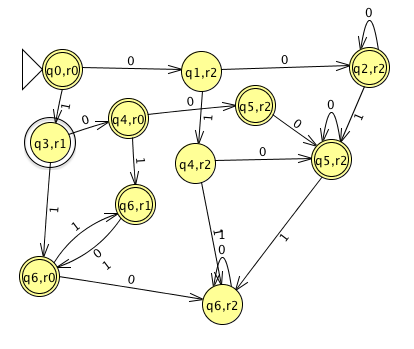
Problem 4. Consider the variant of Exercise 1.38 where rather than being in the language occurs if every possible state that M could be in after reading input x is accepting, we instead only require more than half of the states be accepting. Prove that the resulting class also recognizes exactly the regular languages.
Answer. Let PReg (probabilistic regular) denote the class of languages recognized by machines of the above kind. There are two parts to this problem: We need to show Reg `subseteq` PReg and PReg `subseteq` Reg.
The fact that we used the word "exactly" requires us to prove both directions. To see Reg `subseteq` PReg, let
`L` be a regular language. By definition, `L=L(M)` for some DFA `M = (Q, Sigma, delta, q_0, F)`. Consider the
machine `N = (Q \cup {q'}, Sigma, delta', q_0, F)` where `delta'` and `F'` are defined as follows. For any `q in Q` and `a in Sigma` define `delta'(q, a) = {delta(q,a)}` this is a well-defined mapping from `Q times Sigma -> P(Q \cup {q'})`.
For we define `delta'(q, epsilon) = {q'}` for some new state `q'` not in `Q`. Define `delta'(q', x) = {q'}` for `x in Sigma cup {epsilon}`. Observe by induction that `delta'^\star(q, w) = E(delta^\star(q,w)) ={delta^\star(q,w), q'}` and so consists of at most one accepting state. Now notice
`w in L` iff `delta^\star(q_0,w) = f` for some `f in F` iff `delta'^\star(q_0,w) = {f,q'}` for some `f in F`.
If less than half the states in `delta'^\star(q_0, v) = {s,q'}` are accepting then none of them must be accepting. Hence `s !in F` so `v !in L`. Similarly,
if at least half of the states in `delta'^\star(q_0, v)` then `s in F`, so `v in L`. Therefore `N` shows `L` is in PReg. On the other hand, suppose `L` is a language in Preg via some machine `N`. Apply the Power set construction to `N = (Q, Sigma, delta, q_0, F)` to get a machine `M = (P(Q), Sigma, delta', {q_0}, F')`. Rather than define `F'` as in the original construction define
`F' = {X | X \subset P(Q) mbox( at least half of X elements are accepting)}`.
The resulting machine is a DFA recognizing the same language as `N`.
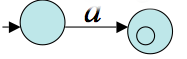
Assume now the result holds for languages for which the total number of uses of union, `*`, or concatenation is at most `n`. Consider `R` a regular language of complexity `n+1`. There are three cases to consider: