Last day, we defined an alphabet to be a finite set. For example `{0,1}` or the usual English alphabet.
The symbols of an alphabet are the members of this set. I.e., `0`, `1` for the first example above.
A string over an alphabet is just a sequence using elements of the alphabet. Ex: `(0,1,1,0)`. This is usually
written as `0110`.
The reverse of a string `w`, `w^R`, is the string consists of the symbols of `w` in reverse order: `001^R = 100`.
A string is `z` is a substring of `w` if `z` appear consecutively within `w`. So `011` is a substring `1001101`.
The concatenation of two strings `x` and `y`, `xy`, is the string consisting of the
symbols in `x` followed by the symbols of `y`.
In the string, `xy`, `x` would be called the prefix; `y` would be called the suffix.
We write `x^k` to denote `x` concatenated to itself `k` times.
A language is a set of string.
Example Languages
Suppose `Sigma={0,1}` is our alphabet.
Then `L= {1, 11, 101}` is an example language.
We write `Sigma^star` for the set of all strings over `Sigma`.
Given two languages `L`, `L'` we write `LL'` for the language consisting of the set of strings `wv` where `w` is in `L` and `v` is in `L'`.
Recall we use `epsilon` to denote the empty string. Some books (and JFLAP by default) use `lambda` to denote the empty string.
Given a language `L`, we define: `L^0 = {epsilon}`, `L^(n+1)={wv | w in L^n ^^ v in L}`. `L^star=cup_(n) L^n`. `L^+=L L^star`.
Given these definitions for the `L` above, we have `epsilon` is `L^star`, but not in `L^+` , we have `11101` is in `L^2`, we have `1110111` is in `L^3`, `L^star`, and `L^+`, but not `L^2`.
Quiz (Sec 1)
Which of the following is true?
A symmetric relation is always reflexive.
A surjective function can map to some element in its range more than once.
The algorithm to find simple paths from last day is `Omega(n^4)`.
Quiz (Sec 3)
Which of the following is true?
A function cannot be both one-to-one and onto.
`sum_(i=1)^n i^2 = Omega(n^4)`.
Less than on the natural numbers is a transitive relation.
Machines
We will now begin our study of how to build machines which can recognize languages.
As a prelude, I will demo JFLAP now.
To download JFLAP please use the link on the class page.
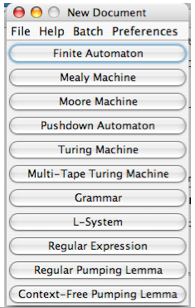
Running JFLAP
When you launch JFLAP you get a window like:
Under Preferences you can set the empty string character to epsilon from its default of lambda.
Next we will be using the Finite Automaton button.
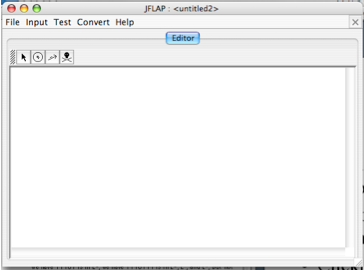
Clicking it will give a window like:
The four buttons across the top of the edit area allow one to: (1) select a state, (2) create a state, (3) create a transitions, (4) delete a state or transition
If you are not running JFLAP as an applet, you can save the automaton you make using the File menu.
Introductory Examples
Finite automata are computer models which are useful when one has very limited memory availability.
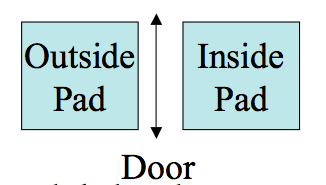
Consider an automatic door say at a grocerystore:
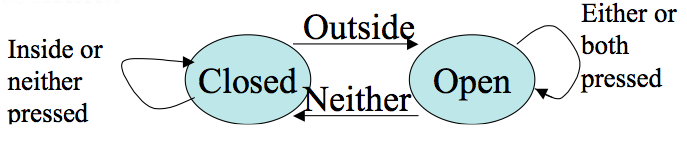
We can model the door state this using a finite automata:
More on Door Example
The controller might start in a CLOSED state and receive the signals: OUTSIDE, INSIDE, NEITHER, INSIDE, BOTH, OUTSIDE, INSIDE NEITHER.
It would then transition between the states CLOSED (start), OPEN, OPEN, CLOSED, CLOSED, CLOSED, OPEN, OPEN, CLOSED.
Notice only need 1-bit of memory to keep track of state.
It is also straightforward to represent transitions in a table:
Neither
Outside
Inside
Both
Closed
Closed
Open
Closed
Closed
Open
Closed
Open
Open
Open
Finite automata and the their probabilistic counterparts called Markov chains are also useful for pattern recognition. For example, recognizing keywords in programming languages. Or figuring out which word English is most likely in a given context based on the previously seen words.
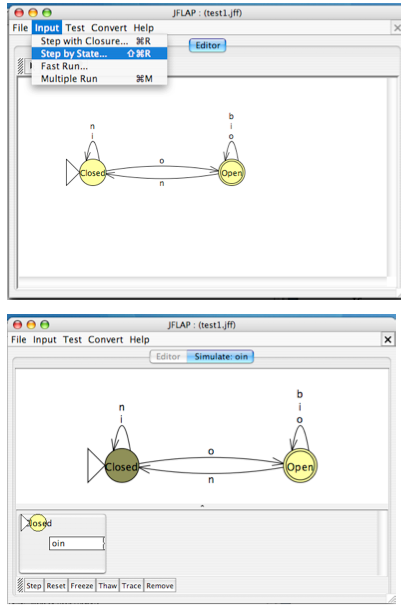
Running an Automaton in JFLAP on Different Inputs
We can build the automaton we just discussed in JFLAP.
We'll use `i` for inside, `o` for outside, `n` for neither, and `b` for both.
To test this automaton on some inputs we first need to say what state it starts in by right clicking on a state and setting it to be a start state.
If we want to say what final states should be viewed as good (aka accepting) we can also do this by right-clicking.
Then using the Input menu, we can select to run the automaton Step-by-State.
You will be prompted for an input to the automaton, at which point you then get a window that let's you step through its computation.
Names for things
The picture we drew of our automata a couple slides back is called a state
diagram.
We will usually use the variables `M`, `N`, ... for machines.
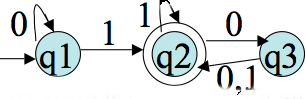
Here is another example machine `M_1`:
The start state is the state with an arrow going from nowhere into it.
If we are recognizing strings then we stop processing when we get to the end
of a string of inputs.
If we are in a double circled state at that point we accept the string otherwise
we reject it. So double circled states called accept states.
Arrows going from one state to another are called transitions.
You might want to see if you can figure out if the above automata accepts each of the following strings: `0001`, `01100`, `1101`.
Formal Definition
A finite automaton is a 5-tuple `(Q, Sigma, delta, q_0, F)`, where
`Q` is a finite set called the states.
`Sigma` is a finite set called the alphabet.
`delta:Q times Sigma rightarrow Q` is the transition function.
`q_0 \in Q` is the start state.
`F subseteq Q` is the set of accept states.
The transition function tells us if we are in a given state reading a given symbol what is the next state to go to.
The definition of finite automaton originates in a paper of McCulloch and Pitts (Biophysics Vol. 5, 1943); however, their paper
was concerned with neural nets.
A more modern looking definition can be found in Huffman (1954), Mealy (1955), and Moore (1956).