0
Introduction
Soon after the first commercial computers appeared in the early 1950s people began seeing analogies between computers and brains, and wondered if computers could exhibit human-like intelligent behavior. Could computers be programmed to reason, learn, and plan? Could computers solve problems they weren't explicitly programmed to solve?
Anthony Newel and Herbert Simon attempted to answer this question by studying the techniques people use to solve problems, then incorporated these techniques into general problem solving programs. They discovered humans are "symbol pushers." People tend to solve problems by producing and manipulating symbolic expressions representing pieces of solutions. They formalized this finding as the Physical Symbol System Hypothesis:
A physical symbol system (i.e. any device or agent that produces an evolving collection of symbols and expressions) has the necessary and sufficient means for general intelligent action.
Unfortunately, computers are "number crunchers." They solve problems by translating them into massive arithmetic problems, then grind them down by performing millions of blinding fast computations. Theoretically, the difference between "number crunching" and "symbol pushing" is more a matter of style than substance, but in practice translating a "symbol pushing" procedure into a "number crunching" procedure is difficult, dirty, dull work. Even the appearance of the first high-level (i.e. machine independent) languages in the late 1950s and early 1960s- FORTRAN, COBOL, Algol60, APL, and BASIC- didn't help much since these languages tended to reflect rather than disguise the "number crunching" character of the underlying computer.
0.1. LISP
In 1960 John McCarthy introduced a high-level language called LISP. (Actually, LISP is the second oldest high-level language. Only FORTRAN predates it.) Unlike FORTRAN, BASIC, and the other languages mentioned above, LISP could treat symbols and expressions like ordinary data. This made LISP a natural language for expressing symbol processing, and it quickly gained a loyal following among Artificial Intelligence researchers. Today LISP is still the language of choice for most Artificial Intelligence applications.
0.1.1. LISP Dialects
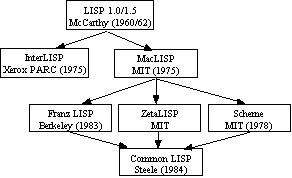
A language is stable if there is wide spread agreement among its users about what features are part of the language. Stability is achieved through an official or semi-official description of the language. Unfortunately, major differences between LISP dialects developed soon after it was introduced. Eventually programs written in one dialect wouldn't run using an interpreter for another. Some of the most popular dialects are shown in the diagram below. Arrows indicate which dialects influenced others.
Figure 0.1
In 1980 work began on a standard dialect called Common LISP. In 1984 Guy Steele described this language in his book, Common LISP: The Language. Common LISP is now widely accepted by industry, and an ANSI standard is about to appear.
0.2. Scheme
I like the Scheme programming language because it is small. It packs a large number of ideas into a small number of features.
Guy Steele Jr.
The dialect of LISP used in this text is called Scheme. Scheme was introduced in 1978 by Guy Steele and Gerald Sussman. Like LISP, Scheme is an interpreted, expression-oriented language. Scheme is a simple language in the sense that there are only a small number data and program constructors (about twenty-five). Furthermore, these constructors are uniform in the sense that there are no seemingly unnecessary restrictions on their use.
Normally expressiveness is sacrificed for simplicity, but Scheme is an exception. Scheme allows programmers to define recursive, polymorphic, overloaded, and higher-order procedures. All of the major programming paradigms can be expressed in Scheme. Scheme also features macros, continuations, promises, streams, and excellent support for number, string, symbol, and list processing. (Don't worry, all of these things will be defined soon.)
As Scheme became popular its local dialects began to diverge and it too became unstable. In 1984 representatives of the major Scheme user communities met and agreed on a standard description of Scheme. Their report has undergone four revisions over the years, popularly known as the Revised, Revised Revised (Revised
2), Revised Revised Revised (Revised3), and Revised Revised Revised Revised (Revised4) Reports on the Algorithmic Language Scheme. (Several attempts at a Revised5 Report have been made.) Readers should refer to this as the most authoritative description of Scheme. The Revised4 Report served as the basis for the IEEE (P1178) specification of Scheme, which became the ANSI specification of Scheme.In this text we refer to the version of Scheme described in the Revised
4 Report as IEEE/ANSI Scheme, and the features described in the report as essential features. Warning: an implementations of Scheme should include all essential features, but this is often not the case.0.2.1. Scheme on the Web
There are many commercially available implementations of Scheme, but there are just as many, if not more, free implementations of Scheme available on the Internet. In addition, there are Scheme news groups, documentation, FAQs, and tools available on the Internet. The best starting place is the Scheme Home Page at MIT:
http://www-swiss.ai.mit.edu/scheme-home.html
0.3. Structure of the Text
Eight chapters follow. Each is divided into three sections: core, appendices, and problems. It is assumed students will read the appendices and solve most of the problems on their own. (Nearly all of the problems require students to write short Scheme procedures.) More essential topics are covered in the core sections. Some skipping around is possible. For example, list and tree recursion got pushed back to Chapter Six, but could be covered immediately after Chapter Three.
The text introduces Scheme in four fragments:
IS = imperative Scheme = IEEE/ANSI Scheme
FS = functional Scheme = IS - variables & commands
AS = application Scheme = FS - control & block structures
NS = necessary Scheme = AS - all redundant features
The first two chapters are restricted to applicative Scheme. (Necessary Scheme surfaces from time to time in various problem sections.) The idea is to wean readers away from command sequencing, the principle program-building tool provided by languages like Pascal and C. Readers will be surprised (and challenged) to see how much can be accomplished in this tiny fragment of Scheme.
Except for a few minor lapses, functional Scheme is the language of Chapters Three through Six. As such, the book could be used as an introduction to functional programming. The pedagogical advantage is that students master the power of functional programming before the picture is complicated by commands and variables. Stores, variables, commands, hence imperative Scheme, are introduced in Chapter Seven.
The last chapter formalizes the semantics of three languages: Alpha (FS - some features), Beta (IS - some features), and Lambda (NS) in the form of three interpreters written in Scheme and following the style of semantic prototyping.
0.3.1. Themes
Although the primary goal of this text is to teach students to program in Scheme, several subplots deserve special mention. First is the emphasis on programming paradigms, starting with the functional paradigm, then building up to the imperative paradigm with side trips into the signal processing, data driven, and object oriented paradigms.
Second is the use of general concepts, models, and terminology from my Programming Language Principles course. Readers should have no trouble adapting the concepts introduced in this text to other programming languages.
Third is the notion of meta programming. Theoretical Computer Science, Software Engineering, and Systems Programming are all based on a critical idea that separates them from routine data processing: that programs can be treated like ordinary data, and therefore, like ordinary data, they can be derived, analyzed, and modified algorithmically. We appropriate the term "meta programming" to refer to this idea.
"Meta programming" is derived from the term "meta language," which is used by Philosophers, Linguists, and Mathematicians to refer to any language used to describe or analyze another language. In this context the language being described or analyzed is referred to as the object language. For example, the meta language used in this book is English, while the object language is Scheme. The "meta" prefix ultimately traces back to Aristotle's term, "metaphysics," which meant "beyond Physics." Meta programming can also mean "beyond programming" in the sense that some topics in this book evolve from or into subjects beyond programming, such as Logic, Cognitive Science, Physics, Mathematics, and Linguistics.
Why emphasize meta programming in a Scheme text? Most programming languages make a sharp distinction between programs and data. Data refers to passive, dumb entities like numbers, lists, tables, and text; while programs are active, intelligent entities that manipulate data. Scheme doesn't have such prejudices, and this makes Scheme an excellent meta language. Writing meta procedures that process expressions, procedures, symbols, or other program elements is natural, easy, and- dare I say it?- fun.