Appendix 1: Programming Notes
The purpose of this appendix is to "review" certain features of C++ (and several other languages) that are used throughout the text, yet may be unfamiliar to readers. These notes are not comprehensive. Readers should consult on-line documentation, [STR], or any reasonably up-to-date reference for details.
Note A.1: Packages
A package is a named collection of declarations that may span several files (see chapter 1). A package defines the scope of the declarations it contains and may be separated into an interface package and an implementation package.
Note A.1.1: Packages in Modula-2
Modula-2 was developed by Nicolas Wirth in the late 1970s as the successor to Pascal. One of the main goals of Modula-2 was to support large software projects that could be quickly assembled out of reusable packages with well-defined interfaces. Wirth's formalization of packages, which he called modules, is lucid and well thought out, which is why we briefly look at them here. See [COOP] for more details.
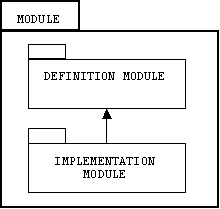
A Modula-2 module (i.e., package) consists of a definition module and an implementation module. A definition module contains declarations of procedures, variables, constants, and types. An implementation module contains the definitions of the components declared in a corresponding definition module:
All modules must explicitly declare the definition modules they depend on using an import statement. Here's the general form of a definition module declaration. (Warning: all Modula-2 keywords use upper case letters only!)
DEFINITION MODULE NAME;
IMPORT needed modules
CONST definitions
TYPE definitions
VAR declarations
PROCEDURE headers
END NAME.
The form of an implementation module is similar. A statement block at the end provides a place to initialize variables:
IMPLEMENTATION MODULE NAME
IMPORT needed modules
CONST definitions
TYPE definitions
VAR definitions
PROCEDURE definitions
BEGIN
initialize variables here
END NAME.
Here is an example of a definition module adapted from [COOP]. It groups functions and constants for computing areas of geometric figures:
DEFINITION MODULE AREA;
PROCEDURE Triangle(Base, Height: REAL): REAL;
PROCEDURE Rectangle(Base, Height: REAL): REAL;
PROCEDURE Circle(Radius: REAL): REAL;
CONST PI = 3.1416;
END AREA.
The definitions of these functions are declared in the corresponding implementation module. Supporting functions, such as Square(), may also be defined in the implementation module. Of course only the functions declared in the definition module can be imported into other packages, so the scope of Square() will be limited to the implementation module:
IMPLEMENTATION MODULE AREA;
PROCEDURE Square(X: REAL): REAL;
BEGIN
RETURN X * X
END Square;
PROCEDURE Triangle(Base, Height: REAL): REAL;
BEGIN
RETURN (Base * Height)/2.0
END Triangle
PROCEDURE Rectangle(Base, Height: REAL): REAL;
BEGIN
RETURN Base * Height
END Rectangle
PROCEDURE Circle(Radius: REAL): REAL;
BEGIN
RETURN PI * Square(Radius)
END Circle
BEGIN
(* nothing to initialize! *)
END AREA.
Here is an example of a definition module that groups functions for computing volumes of surfaces:
DEFINITION MODULE VOLUME;
PROCEDURE Cylinder(Radius, Height: REAL): REAL;
PROCEDURE Box(Base, Height, Width: REAL): REAL;
PROCEDURE Sphere(Radius: REAL): REAL;
END VOLUME.
In this case the corresponding implementation module imports the AREA module. This means that we can use the constant and functions declared in the AREA definition module, but their names must be qualified by "AREA", the name of their module.
IMPLEMENTATION MODULE VOLUME;
IMPORT AREA;
CONST FourThirdsPi = Area.PI * 4.0/3.0;
PROCEDURE Cube(X: REAL): REAL;
BEGIN
RETURN X * X * X
END Cube;
PROCEDURE Cylinder(Radius, Height: REAL): REAL;
BEGIN
RETURN AREA.Circle(Radius) * Height
END Cylinder;
PROCEDURE Box(Base, Height, Width: REAL): REAL;
BEGIN
RETURN AREA.Rectangle(Base, Height) * Width
END Box;
PROCEDURE Sphere(Radius: REAL): REAL;
BEGIN
RETURN FourThirdsPi * Cube(Radius)
END Sphere;
BEGIN
(* nothing to initialize! *)
END VOLUME.
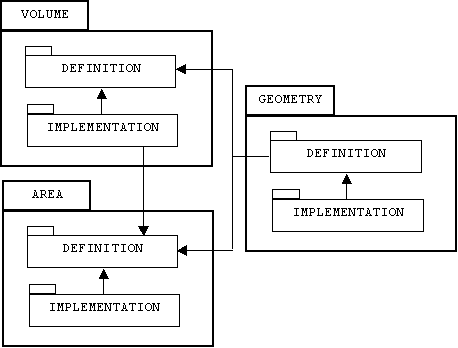
Definition modules can also be formed by composing existing modules:
DEFINITION MODULE GEOMETRY;
IMPORT AREA;
IMPORT VOLUME;
END GEOMETRY.
The corresponding implementation module is still required, although it is empty:
IMPLEMENTATION MODULE GEOMETRY;
BEGIN
END GEOMETRY.
Here is the corresponding dependency graph:
Note A.1.2: Packages in Java
The Java Development Kit (JDK) includes:
1. A compiler that translates Java programs contained in .java files into byte code programs contained in .class files,
2. a byte code interpreter called the Java virtual machine, and
3. a library of pre-defined classes.
The JDK classes are partitioned into packages, sub-packages, and sub-sub-packages:
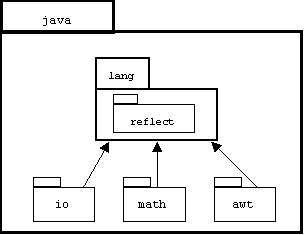
For example, clicking a button on a Java control panel creates and "fires" an action event object. Along with all of the other event classes, the ActionEvent class is declared in the AWTEvent package, which is declared inside the abstract windows toolkit package, awt. This package is declared inside java, the package of all pre-defined classes. Here is the syntax for the declaration of a reference to an action event object using the fully qualified name of the ActionEvent class:
java.awt.AWTEvent.ActionEvent e;
We can avoid the need for fully qualified names by explicitly importing one package into another. For example, the import declaration:
import java.awt.AWTEvent.*;
placed at the top of a .java file tells the Java compiler to look in the java.awt.AWTEvent package for classes that are used but not defined in the file. We may now simply declare e by:
ActionEvent e;
Of course Java programmers can create their own packages. For example, if a programmer wants to create a package called MyClasses, he simply declares:
package MyClasses;
at the top of each .java file containing declarations of classes belonging to the MyClasses package. Typically, all such files would be placed in the same directory.
If we forget to explicitly declare a class or member public, protected, or private, then by default, it has package scope.
Note A.1.2: Packages in C++: Namespaces
C++ provides several types of scopes: global, file, class, and block. We can also create a package scope using a namespace declaration:
namespace NAME { DECLARATION ... }
References to names outside of their namespace must be qualified using the scope resolution operator. For example, assume a function named jupiter() is declared in a namespace called Planet:
namespace Planet
{
void jupiter() { ... }
// etc.
}
Clients of the Planet namespace must qualify calls to jupiter():
Planet::jupiter();
All of the declarations in the standard C++ library are contained in a namespace called std. This means names defined in the <iostream> header file, such as ostream, istream, cout, and cin must be qualified by "std::" when they are used by clients (see Programming Note A.3). For example, here's the official version of the Hello world program:
#include <iostream>
int main()
{
std::cout << "Hello, world!\n";
return 0;
}
We will see how to avoid the std qualifier below.
Example 1: Namespace declarations can span multiple header files
In this example the Car namespace is declared in files ford.h and buick.h:
// ford.h
namespace Car
{
struct Ford
{
void start();
void drive();
void stop();
};
void test(Ford c);
}
// buick.h
namespace Car
{
struct Buick
{
void start();
void drive();
void stop();
};
void test(Buick c);
}
The linker isn't upset by what appears to be two separate declarations of the Car namespace. Instead, it regards the second "declaration" as a continuation of the first.
The implementations are in files ford.cpp and buick.cpp. Notice that the names of the member functions are qualified by the namespace name and the class name:
// buick.cpp
#include "buick.h"
#include <iostream>
void Car::Buick::start() { std::cout << "Starting a Buick\n"; }
void Car::Buick::drive() { std::cout << "Driving a Buick\n"; }
void Car::Buick::stop() { std::cout << "Stopping a Buick\n"; }
void Car::test(Buick c) { c.start(); c.drive(); c.stop(); }
// ford.cpp
#include "ford.h"
#include <iostream>
void Car::Ford::start() { std::cout << "Starting a Ford\n"; }
void Car::Ford::drive() { std::cout << "Driving a Ford\n"; }
void Car::Ford::stop() { std::cout << "Stopping a Ford\n"; }
void Car::test(Ford c) { c.start(); c.drive(); c.stop(); }
The test drivers are declared in file client.cpp:
// client.cpp
#include "ford.h"
#include "buick.h"
test1() uses the qualified names for all items declared in the Car namespace:
void test1()
{
Car::Buick b;
Car::Ford f;
Car::test(b);
Car::test(f);
}
test2() imports the name Car::test into its scope with a using declaration:
void test2()
{
using Car::test;
Car::Buick b;
Car::Ford f;
test(b);
test(f);
}
The using declaration is a bit like an import declaration, but it only allows the unqualified use of the test() functions from the point of the declaration to the end of the scope in which the declaration occurs. In this case the declaration occurs in a block scope. In other words, the test1() function must still qualify calls to test() with "Car::", even if it is declared after test2(). Also notice that we can't import one variant of the test() function but not the other.
test3() imports the entire Car namespace into its scope with the using directive:
void test3()
{
using namespace Car;
Buick b;
Ford f;
test(b);
test(f);
}
Like the using declaration, the using directive only allows unqualified references to namespace names within the scope in which it occurs.
It is common to import the entire std namespace into a file scope to avoid the need to qualify every reference to a library type or object. Here's our new implementation of the Hello world program:
#include <iostream>
using namespace std;
int main()
{
cout << "Hello, world!\n";
return 0;
}
This using directive has file scope, which means that standard library names can only be used without qualification within the file.
Example 2: Composition and Selection
Assume FarmJobs and OfficeJobs are namespaces:
namespace FarmJobs
{
void plant() { cout << "planting corn\n"; }
void grow() { cout << "growing corn\n"; }
void pick() { cout << "picking corn\n"; }
}
namespace OfficeJobs
{
void file() { cout << "filing reports\n"; }
void type() { cout << "typing reports\n"; }
void shred() { cout << "shredding reports\n"; }
}
We can create new namespaces from these using composition and selection. Composition creates a namespace by joining several existing namespaces:
namespace Jobs
{
using namespace FarmJobs;
using namespace OfficeJobs;
}
Selection creates a new namespace by selecting items from existing namespaces:
namespace EasyJobs
{
using FarmJobs::grow;
using OfficeJobs::file;
using OfficeJobs::shred;
}
A client can use Jobs and EasyJobs without knowledge of FarmJobs or OfficeJobs:
void test5()
{
Jobs::plant();
Jobs::grow();
Jobs::pick();
Jobs::type();
Jobs::file();
Jobs::shred();
EasyJobs::grow();
EasyJobs::shred();
}
Example 3: Namespaces as Interfaces
Like a header file, a namespace specifies an interface to clients and implementers. The implementer's interface contains all of the declarations:
// register.h
namespace Register // cash register functions
{
void recordItem();
void computeTotal();
void makeReceipt();
void reset();
void lock();
void unlock();
}
As usual, we separate the implementation from the interface:
// register.cpp
#include "register.h"
void Register::recordItem() { ... }
void Register::computeTotal() { ... }
void Register::makeReceipt() { ... }
void Register::reset() { ... }
void Register::lock() { ... }
void Register::unlock() { ... }
Assume we anticipate two types of clients: clerks and managers. Using selection, we can create client interfaces for each one:
// clerk.h
#include "register.h"
namespace ClerkInterface
{
using Register::recordItem;
using Register::computeTotal;
using Register::makeReceipt;
using Register::reset;
}
// manager.h
#include "register.h"
namespace ManagerInterface
{
using Register::unlock;
using Register::lock;
using Register::reset;
}
Example 4: Delegation between Namespaces
We can eliminate the dependency of the manager interface, for example, on the register interface by providing implementations of the manager interface functions that delegate to the corresponding register functions:
// manager.h
namespace ManagerInterface
{
void unlock();
void lock();
void reset();
}
Of course the implementation of the manager interface still depends on the register interface:
// manager.cpp
#include "manager.h"
#include "register.h"
void ManagerInterface::unlock() { Register::unlock(); }
void ManagerInterface::reset() { Register::reset(); }
void ManagerInterface::lock() { Register::lock(); }
Note A.2: Separate Compilation
Keeping a large program (say more than 250 lines) in a single source file (e.g. a .cpp file) has several disadvantages:
1. A minor change requires recompilation of the entire program.
2. Reusing part of the program, a class for example, in another program requires a risky copy and paste operation. The class declaration, all member function implementations, and all other dependencies must be located, copied (don't press the cut button!), and pasted into another file.
3. Several programmers can't work on the program simultaneously.
For these reasons most programs are divided into several source files, each containing logically related declarations. Each source file is compiled separately, producing a file of machine language instructions called an object file (e.g., a .obj file in Windows and DOS):
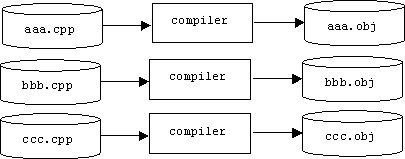
It's the job of a program called a linker to link a project's object files together into a single executable file. The linker is responsible for associating all references to a name in one object file to the definition of the name, which might be in another object file. This process is called address resolution. Sometimes the definition of a name isn't in any of the project's object files. In this case the linker searches the standard C++ library (libcp.lib), the standard C library (libc.lib), and any special libraries specified by the programmer for the name's definition. (Only the definitions needed by the program are extracted from a library and linked into the program.)
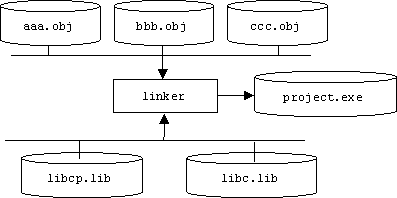
If the name's definition still can't be found, the linker generates an unfriendly error message:
Linking...
main.obj : error LNK2001: unresolved external symbol "int __cdecl sine(int)" (?sine@@YAHH@Z)
Debug/Lab5b.exe : fatal error LNK1120: 1 unresolved externals
Error executing link.exe.
Lab5b.exe - 2 error(s), 0 warning(s)
Note A.2.1: What are header files for?
Multiple source file programs sound great, but there is a problem. While the compiler is willing to accept that a name can be used in a source file without being defined there (after all, its the linker's job to find the definition), the compiler must at least know the type of the name in order to perform type checking, variant selections, and offset calculations. But the compiler only compiles one file at a time. It knows nothing of the project's other source files; it can't be expected to go searching for a name's type the same way the linker searches for a name's definition. Regrettably, it is the programmer's duty to put type declarations of all names used but not defined in the file.
This job would be worse than it already is if it wasn't for the #include directive. A preprocessor directive is a command beginning with a # symbol that can appear in a source or header file. When a file is compiled, it is first submitted to the C/C++ preprocessor, which executes all directives. (Consult online help for a list of all directives.) Preprocessor directives usually alter the source file in some way:
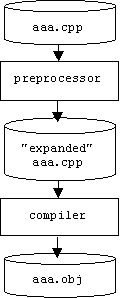
For example, the #include directive takes a file name for its argument. When executed by the preprocessor, it replaces itself with the entire contents of the file. (Be careful, if the same directive is in the file, then an infinite loop can occur.)
How do we use #include to solve our problem? If a programmer creates a source file called util.cpp containing definitions that may be useful in other source files, the programmer also creates a header file called util.h containing the corresponding type declarations . A second source file, say main.cpp, that uses the definitions contained in util.cpp only needs to include the directive in order to be compiled:
#include "util.h"
Normally, util.h would also include type declarations needed by util.cpp, so util.cpp also includes util.h. Of course util.obj will still need to be available to the linker to create an executable.
Note A.2.2: What goes into a header file?
C++ makes a distinction between definitions and declarations. Technically, a definition associates a name with a particular item such as a variable, function, or class, while a declaration merely associates a name with a type. We call items that can be named bindables, and an association between a name and a bindable a binding. Declarations are important to the compiler, while definitions are important to the linker. Here are some examples of definitions and declarations:
1. The definition:
int x;
associates the name x with an integer variable, while the declaration:
extern int x;
tells the compiler that x is the name of an integer variable, but not which one.
2. The definition:
double square(double x) { return x * x; }
associates the name square with a function that is parameterized by a double and that returns a double, while the declaration:
double square(double x); // a.k.a. prototype or header
tells the compiler that square is the name of a function that is parameterized by a double and that returns a double, but not which one.
3. The definition:
struct Date { int month, day, year; };
associates the name Date with a class of objects, each containing three integer member variables named month, day, and year, while the declaration:
struct Date; // forward reference
tells the compiler that Date is the name of a class, but not which one.
The terminology is a little confusing because associating a name to a bindable implicitly associates the name to a type, and therefore a definition is also a declaration. In other words, the definition:
int x;
is also a declaration, because it also tells the compiler that x is the name of an integer variable. However, the declaration:
extern int x;
is not a definition, because it doesn't bind the name x to any particular variable. In short, all definitions are declarations, but not vice versa. Let's call declarations that aren't definitions pure declarations.

The One Definition Rule
The One-Definition Rule (ODR) states that a definition may only occur once in a C++ program, but a pure declaration can occur multiple times as long as the occurrences don't contradict each other. Therefore, pure declarations are often placed in header files, which may then be included multiple times in a program, but definitions should not be placed in header files.
Exceptions to the One Definition Rule
However, some types of definitions are important to the compiler, too, and so, like pure declarations, these must be placed in header files that get included in every source file where they are needed. To accommodate these types of definitions, there are three exceptions to the One Definition Rule: types, templates, and inline functions may be multiply defined in a C++ program, provided three conditions are met:
1. They don't occur multiple times in the same source file.
2. Their occurances are token-for-token identical.
3. The meanings of their tokens remain the same in each occurance.
Here are three ways of violating these conditions. (The example is borrowed from [STR].) See if you can spot them:
Example 1:
// file1.cpp
struct Date { int d, m, y; };
struct Date { int d, m, y; };
Example 2:
// file1.cpp
struct Date { int d, m, y; };
// file2.cpp
struct Date { int d, m, year; };
Example 3:
// file1.cpp
typedef int INT;
struct Date { INT d, m, y; };
// file2.cpp
typedef char INT;
struct Date { INT d, m, y; };
Preventing Multiple Declarations in a Single File
The second and third conditions are easy to live with, but insuring that a type definition will not occur multiple times in the same source file can be tricky. Suppose the definition of Date is contained in date.h, which is included in util.h:
// date.h
struct Data { int d, m, y; };
// etc.
// util.h
#include "date.h"
// etc.
Not knowing that util.h already includes date.h, the unwary author of main.cpp includes both files:
// main.cpp
#include "date.h"
#include "util.h"
// etc.
Unfortunately, this places two occurrences of the definition of Date in main.cpp, thus violating the condition that two type definitions can't occur in the same file.
To prevent this problem, header files can be conditionally included in a file. The usual condition is that a particular identifier hasn't been defined by the preprocessor, yet. The #ifndef /#endif directives are used to bracket the declarations that are conditionally included in this way. The identifier is usually defined immediately after the #ifndef directive using the #define directive. Thus the declarations are included exactly once. To prevent naming conflicts, the name of the identifier is formed from the name of the header file, replacing the period by an underscore and replacing lower case letters by upper case letters. Here's the new, safe version of date.h:
// date.h
#ifndef DATE_H
#define DATE_H
struct Data { int d, m, y; };
// etc.
#endif
Since conditional inclusion is possible, why not ignore the One Definition Rule and place all definitions in header files? Well, conditional inclusion only prevents a header file from being included multiple times in a single source file. If our program has multiple source files, then it's still possible that a definition placed in a header file will occur multiple times within the program, which will cause a linker error.
We could restrict ourselves to a single source file, but a clever linker only extracts and links those definitions that are actually used into the executable file. If we include all definitions into a single source file, then they will appear in the executable whether they are used or not.
Note A.3: The C++ Standard Library
C++ comes with two standard libraries: the old C library (libc.lib), and the new C++ library (libcp.lib), which is logically divided into the stream library, and STL, the standard template library. Many implementations also include a pre-standard stream library for backward compatibility.
Standard library header files and the std namespace
The declarations of the functions, variables, and types in the standard libraries are distributed among some 51 header files. We must include these header files where we use the items they declare. For example, if we will be using lists, strings, and streams, we must include:
#include <list>
#include <string>
#include <iostream>
The angle brackets tell the pre-processor to look in the "usual directory" for the header file. In theory, specifying the .h extension is optional for C++ library header files (i.e., for header files containing declarations of C++ library items). We can also drop the .h for C library header files, but in this case we add the letter "c" to the beginning of the file name to indicate that it is a C library header file. For example, the C library mathematical functions (sin(), pow(), fabs(), etc.) are declared in <math.h>, so we can either write:
#include <math.h>
or
#include <cmath>
See your online documentation or [STR] for a list of all 51 header files.
Namespaces were discussed in Programming Note A.1.3, where it was stated that the entire standard C++ library exists in a namespace called std, and therefore standard library names should be qualified by users:
std::cout << "Hello, world!\n";
Namespaces are useful for large programs, but for small programs they get a little tedious, so lazy programmers, like us, often join the entire std namespace to each file scope with a using directive:
#include <list>
#include <string>
#include <iostream>
using namespace std;
Now we can refer to library items without the std qualification:
cout << "Hello, world!\n";
Namespaces are a relatively recent addition to C++, so of course they don't appear in the pre-standard stream libraries or the C library.
Note A.3.1: STL: The Standard Template Library
A container is actually a handle that manages a potentially complicated C-style data structure such as an AVL tree, hash table, or doubly linked list (see the Handle-Body idiom discussed in chapter 4). Fortunately, implementing these data structures is largely an academic exercise these days (but a good one). This is because the standard C++ library now comes with a collection of container templates called the Standard Template Library:
Sequences
vector<Storable> (random access store)
string (derived from vector<char>)
list<Storable> (sequential access store)
deque<Storable> (base class store for stacks and queues)
Sequence Adaptors (temporal access stores)
stack<Storable> (LIFO store)
queue<Storable> (FIFO store)
priority_queue<Storable> (uses Storable::operator<())
Associative Containers
map<Key, Storable> (associative access store)
multimap<Key, Storable>
set<Storable>
multiset<Key>
Here are some of the header files you need to include if you want to use STL containers:
#include <string>
#include <vector>
#include <list>
#include <deque>
#include <stack>
#include <queue>
#include <map>
#include <algorithm>
#include <functional>
using namespace std;
Note A.3.1.1: C++ Strings
A C string is simply a static or dynamic array of characters:
typedef char String80[80]; // static arrays
typedef char* String; // pointers to dynamic arrays
A C string literal is a sequence of characters bracketed by double quotes (backslash is the escape character):
String path = "c:\\data\\info.doc";
String80 prompt = "Type \"q\" to quit\n";
C strings are always terminated by the NUL character (i.e., ASCII code 0). The standard C library provides functions for manipulating C strings. These are declared in <cstring>:
int strcmp( const char* string1, vonst char* string2 );
size_t strlen( const char* string );
char* strcpy( char* dest, char* source );
char* strcat( char* dest, char* source );
// etc.
Because C strings don't check for out-of-range indices, and because they don't allocate and deallocate memory for themselves, programmers should use C++ strings instead. C++ strings are instances of the string class declared in <string>, which is part of the std namespace:
#include <string>
using namespace std;
We can use C strings to initialize C++ strings:
string s1("California"), s2, s3;
s2 = "Nevada";
The third C++ string, s3, is currently empty:
cout << boolalpha << s3.empty() << endl; // prints "true"
C++ strings can be read from an input stream using the extraction operator and written to an output stream using the insertion operator.
cout << "Enter 3 strings separated by white space: ";
cin >> s1 >> s2 >> s3;
cout << "You entered: " << s1 << ' ' << s2 << ' ' << s3 << endl;
The size() and length() member functions both return the number of characters in a C++ string:
cout << s1.length() + s2.size() << endl; // prints 16
There are several ways to access the characters in a C++ string. One way is to use the subscript operator:
for(int i = 0; i < s1.size(); i++) cout << s1[i] << ' ';
Unfortunately, the subscript operator doesn't check for index range errors. For this we must use the at() member function, which throws an out_of_range exception when the index is too large:
try
{
cout << s1.at(500) << endl; // oops, index too big!
}
catch(out_of_range e)
{
cerr << e.what() << endl; // prints "invalid string position"
}
Assigning s2 to s3:
s3 = s2;
automatically copies s2 to s3. We can verify this by modifying the first character of s3:
s3[0] = 'n'; // change 'N' to 'n'
then printing s2 and noticing that it is unchanged:
cout << s2 << endl; // prints "Nevada"
One of the best features of C++ strings is that they automatically grow to accommodate extra characters:
s3 = "Nevada is in the USA";
We don't need to bother with the awkward C library string manipulation functions. C++ strings can be compared and concatenated using infix operators:
s1 == s2; // = false
s1 != s2; // = true
s1 <= s2; // = true
s3 = s1 + ' ' + "is next to" + ' ' + s2;
// etc.
There are also many member functions that can be used to find, extract, erase, and replace substrings:
int pos = s1.find("for"); // pos = 4
s3 = s1.substr(pos, 3); // s3 = "for"
s3 = s1.substr(pos, string::npos); // s3 = "fornia"
s1.replace(pos, 3, "XX"); // s1 = "CaliXXnia"
s1.erase(pos, 2); // s1 = "Calinia"
The c_str() member function returns an equivalent C string which can be used by C library functions:
printf("%s\n", s1.c_str());
There are many more C++ string member functions. The reader should consult online documentation or [STR] for a complete list.
Note A.3.1.2: Iterators
Iterators are similar to the smart pointers discussed in Chapter 4, only an iterator is an object that "points" to an element in a container, string, or stream. Like pointers, iterators can be incremented, decremented, compared, or dereferenced.
For example, we can traverse an array using index numbers:
char msg[] = "Hello World";
for (int i = 0; i < strlen(msg); i++)
cout << msg[i] << ' ';
but we could just as easily use a pointer to traverse the array:
for(char* p = msg; p != msg + strlen(msg); p++)
cout << *p << ' ';
We can traverse a C++ string using index numbers, too:
string msg = "Hello World";
for (int i = 0; i < msg.length(); i++)
cout << msg[i] << ' ';
But we can't traverse a C++ string using an ordinary pointer, because a string is only a handle that encapsulates a C string. Instead, we must use an iterator to "point" at elements inside of a string.
for(string::iterator p = msg.begin(); p != msg.end(); p++)
cout << *p << ' ';
Iterator declarations must be qualified by the appropriate container class:
string::iterator p;
This is because the iterator class for a container class is declared inside the container class declaration. For example:
class string
{
public:
class iterator { ... };
class const_iterator { ... };
iterator begin();
iterator end();
// etc.
};
This is done because iterators for strings might be quite different for iterators for lists, maps, and deques.
All container classes provide begin() and end() functions. The begin() function returns an iterator that points to the first element in the container. The end() function returns an iterator that points to a location just beyond the last element of the container.
C++ iterators can be regarded as an instantiation of the more general iterator design pattern:
Iterator
[Go4]Other Names
Cursor
Problem
Sharing a data structure such as a linked list or file is difficult, because apparently non destructive operations, such as printing the list, can actually be destructive if they move the list's internal cursor (i.e., the list's pointer to its current element).
Solution
An iterator is an external cursor owned by a client. Modifying an iterator has no effect on iterators owned by other clients.
Basic Container Operations
Assume c is an STL container, x is a potential container element, and p is an iterator. Here are some of the most common operations:
c.begin() = iterator "pointing" to first element of c
c.end() = iterator "pointing" to one past last element
c.front() = first element of c
c.back() = last element of c
c.size() = number of elements in c
c.empty() = true if container is empty
c.push_back(x) inserts x at end of c
c.push_front(x) inserts x at beginning of c
c.insert(p, x) inserts x in c before *p
c.pop_front() removes first element of c
c.pop_back() removes last element of c
c.erase(p) removes *p
Note A.3.1.3: Vectors
STL vectors encapsulate dynamic arrays (see chapter 4). They automatically grow to accommodate any number of elements. The elements in a vector can be accessed and modified using iterators or indices.
To begin, let's provide a template for printing vectors, this will make a nice addition to our utility library. We use a constant iterator:
template <typename Storable>
ostream& operator<<(ostream& os, const vector<Storable>& v)
{
os << "( ";
vector<Storable>::const_iterator p;
for( p = v.begin(); p != v.end(); p++)
os << *p << ' ';
os << ')';
return os;
}
Here's how we declare an integer vector:
vector<int> vec;
It's easy to add elements to the back of a vector:
vec.push_back(7);
vec.push_back(42);
vec.push_back(19);
vec.push_back(100);
vec.push_back(-13);
cout << vec << endl; // prints (7 42 19 100 –13)
It's also easy to remove elements from the back of a vector:
vec.pop_back(); // removes -13
Of course we can use the subscript operator to access and modify vector elements:
for(int i = 0; i < vec.size(); i++)
vec[i] = 2 * vec[i]; // double each element
The subscript operator is unsafe. It doesn't check for out of range indices. As with strings, we must us the vec.at(i) member function for safe access.
To insert or remove an item from any position in a vector other than the last, we must first obtain an iterator that will point to the insertion or removal position:
vector<int>::iterator p = vec.begin();
Next, we position p:
p = p + 2;
Finally, we insert the item using the insert() member function:
vec.insert(p, 777);
cout << vec << endl; // prints (14 84 77 38 200)
We follow the same procedure to remove an element:
p = vec.begin() + 1;
vec.erase(p);
cout << vec << endl; // prints (14 77 38 200)
Note A.3.1.4: Lists
STL lists encapsulate and manage linked lists. As before, we begin with a useful list writer. Only two changes are needed from the vector writer:
template <typename Storable>
ostream& operator<<(ostream& os, const list<Storable>& v)
{
os << "( ";
list<Storable>::const_iterator p;
for( p = v.begin(); p != v.end(); p++)
os << *p << ' ';
os << ")";
return os;
}
Here is how we declare two lists of strings:
list<string> vals1, vals2;
We can add items to the front or rear of a list:
vals1.push_back("golf");
vals1.push_back("judo");
vals1.push_back("pool");
vals1.push_back("boxing");
cout << vals1 << endl; // prints (golf judo pool boxing)
vals2.push_front("car");
vals2.push_front("boat");
vals2.push_front("plane");
vals2.push_front("horse");
cout << vals2 << endl; // prints (horse plane boat car)
As with vectors, to insert an item into a list we first need an iterator pointing to the point of insertion:
list<string>::iterator p = vals1.begin();
p++; p++; // p + 2 not allowed!
vals1.insert(p, "yoga");
cout << vals1 << endl; // prints (golf judo yoga pool boxing)
Inserting an item into a list is more efficient than inserting an item into a vector. This is because logically consecutive elements of a dynamic array are also physically consecutive, while linked lists decouple logical and physical order. Therefore, inserting an item into a vector involves moving all elements above the insertion point to make space, while inserting an item into a list merely involves adjusting a few links.
On the other hand, pointing a vector iterator at an insertion point can be done by a single operation:
p = vals.begin() + n;
While pointing a list iterator at an insertion point involves multiple operations:
for(int i = 0, p = vals1.begin(); i < n; i++) p++;
In general, C++ iterators belong to categories. While not classes, iterator categories are organized into a specialization hierarchy that can be described by the following class diagram:
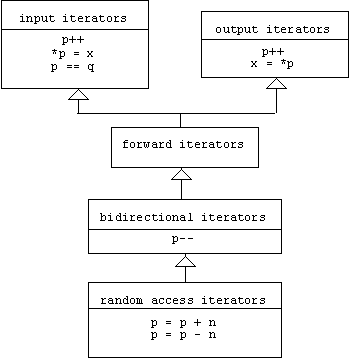
List iterators are bidirectional. They inherit the ability to be incremented (by 1), compared, and dereferenced. In addition, they can be decremented (by 1). Vector iterators are random access. They inherit all of the functionality of bidirectional iterators, but they can be incremented or decremented by arbitrary amounts.
Removing an item from a linked list can also be done by pointing an iterator at the item to be removed:
p = vals2.begin();
p++;
vals2.erase(p);
cout << vals2 << endl; // prints (horse boat car)
But we can also remove the first occurrence of an item in the list by simply specifying the item to be removed:
vals1.remove("golf");
The list<> template provides member functions for various useful list operations:
vals2.reverse();
vals1.sort();
vals1.merge(vals2);
cout << vals1 << endl;
// prints (boxing car boat horse judo pool yoga)
Consult your online documentation or [STR] for a complete list.
Deques, Stacks, and Queues
By themselves, deques (rhymes with "wrecks") are relatively useless. They are optimized for inserting and removing elements at either end, hence are ideal adaptees for stacks and queues. See the discussion on adapters in chapter 4 for details.
Note A.3.1.5: Maps
One of the most common and useful data structures is a table. For example, we used save and load tables in our persistence framework, and we used a prototype table in our implementation of the Prototype pattern. (See chapter 5 for details.)
A table is simply a list of pairs (i.e., the rows of the table) of the form:
(KEY, VALUE)
KEY and VALUE can be any type, but no two pairs in a table have the same key. This requirement allows us to associatively search tables for a pair with a given key.
For example, a concordance is a table that alphabetically lists every word that appears in a document, together with the number of occurrences of that word. For example, The Harvard Concordance to Shakespeare lists every word ever written by the Bard. It is 2.5 inches thick and lists about 29,000 different words! (The King James Bible only uses 6000 different words.) About 1/12 of the words only occur once, and, contrary to popular belief, the word "gadzooks" never occurs!
Tables can be represented in C++ programs by STL maps. A map is a sequence of pairs, where pair is an STL type that simply binds two elements together:
template <typename KEY, class VALUE>
struct pair
{
KEY first;
VALUE second;
};
For example, here is a concordance for a document containing the single phrase, "to be or not to be":
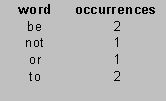
Here is one way we could build this concordance in C++:
map<string, int> concordance;
concordance["to"] = 2;
concordance["be"] = 2;
concordance["or"] = 1;
concordance["not"] = 1;
Notice that we can use the array subscript operator to insert entries. In a way, a map is like an array indexed by an arbitrary type. In fact, if the index isn't a key in the table, a new pair is created with this key associated to the default or null value of the corresponding value type, and the new pair is inserted into the table. Since the "null" value for the integer type is 0, we can use this fact to create our concordance in a different way:
map<string, int> concordance;
concordance["to"]++;
concordance["be"]++;
concordance["or"]++;
concordance["not"]++;
concordance["to"]++;
concordance["be"]++;
Here are useful template functions for writing pairs and maps:
template <typename Key, typename Value>
ostream& operator<<(ostream& os, const pair<Key, Value>& p)
{
os << '(' << p.first << ", " << p.second << ')';
return os;
}
template <typename Key, typename Value>
ostream& operator<<(ostream& os, const map<Key, Value>& m)
{
map<Key, Value>::const_iterator p;
for( p = m.begin(); p != m.end(); p++) os << *p << endl;
return os;
}
For example,
cout << concordance;
prints:
(be, 2)
(not, 1)
(or, 1)
(to, 2)
Putting this together, here's how we can implement a concordance generator that reads a document from standard input and writes the concordance to standard output (we can use file redirection to read and write to files):
int main()
{
string s;
map<string, int> concordance;
while (cin >> s) concordance[s]++;
cout << concordance;
return 0;
}
Unfortunately, searching a table is a little awkward using the map<> member functions. If m is a map and k is a key, then m.find(k) returns an iterator pointing to the first pair in m having key == k, otherwise m.end() is returned. We can make this job easier with the following template function that can be used to find the value associated with a particular key. The function returns false if the search fails:
template <typename Key, typename Value>
bool find(Key k, Value& v, const map<Key, Value>& m)
{
map<Key, Value>::iterator p;
p = m.find(k);
if (p == m.end())
return false;
else
{
v = (*p).second;
return true;
}
}
Here's how we could learn the word count for a string in our concordance:
int count = 0;
string word = "be";
if (find(word, count, concordance))
cout << word << " count = " << count << endl;
else
cout << word << " not found\n";
Note A.3.2: Streams
I/O is not built into the C++ language. Instead, it is provided in the standard library. To get the I/O facilities, you will need some of the following include directives in your program:
#include <iostream> // standard streams
#include <fstream> // file streams
#include <sstream> // string streams
#include <iomanip> // manipulators
using namespace std;
Input sources and output sinks— i.e., I/O devices, strings, and files—are represented in C++ programs by objects called streams. A stream can be thought of as a sequence of characters. An input stream is a sequence of characters coming from an input source. An output stream is a sequence of characters heading for an output sink. When a program needs input, it extracts characters from an input stream. When a program wants to perform output, it inserts characters into an output stream.
Note A.3.2.1: Output Streams
Output streams are instances of the class ostream, which is defined in <iostream>. There are several pre-defined output streams:
ostream cout; // standard output stream
ostream cerr, clog; // insert error messages here
Initially, all three of these streams are associated with the monitor, but file redirection and pipes can re-associate cout with a file or the standard input stream of another program, while cerr and clog (which only differ in their buffering strategies) cannot be redirected.
The most basic service provided by instances of the ostream class inserts a single character into an output stream:
cout.put('b');
cout.put('a');
cout.put('t');
cout.put('\n');
We can insert a whole string using the write() function:
cerr.write("bat\n", 4); // write 4 chars
Unfortunately, put() and write() only deal with characters. They do not perform translation from binary values to strings. The standard library provides translators that do this. All output translators are represented by the left shift operator. For example:
cout << 42; // translates 42 to "42", then inserts
cout << 3.1416; // translates 3.1416 to "3.1416", then inserts
Because of overloading, this doesn't cause confusion. The C++ compiler can tell by the left operand, cout, that translation, not left shift is to be performed. The right operand tells it what type of translation is to be performed: int to string, double to string, etc.
Of course we can also use translators to write ordinary strings and characters:
cout << "bat";
cout << '\n';
Translators return their left operand as a value, thus several output operations can be chained together on a single line:
cout << "result = " << 6 * 7 << '\n'; // prints "result = 42"
Because left shift is left-to-right associative, this is the same as:
(((cout << "result = ") << 6 * 7) << '\n');
Which is the same as:
cout << "result = ";
cout << 6 * 7;
cout << '\n';
We can even define our own translators. Assume rational numbers (i.e. fractions like 2/3, 1/8, and 7/5) are represented by two integers (the numerator and denominator) encapsulated in a struct:
struct Rational
{
int num, den; // = num/den
// etc.
};
Here are declarations of the rational numbers 3/8 and 2/1:
Rational q = {3, 8}, p = {2, 1};
By defining our own variant of the left shift operator:
ostream& operator<<(ostream& os, const Rational& rat)
{
os << rat.num;
if (rat.den != 1)
os << '/' << rat.den;
return os;
}
our rational numbers will be translated into strings and printed according to our desire:
cout << q << '\n'; // prints 3/8
cerr << p << '\n'; // prints 2
Note: we must pass os by reference, because it is modified by having the numerator and denominator inserted into it. To allow chaining, we must also return os. Also note that os << rat.num and os << rat.den are calling the integer variant of left shift. They are not recursively calling the variant being defined.
Output File Streams
Writing to a file is easy. Simply declare an instance of the ofstream class. The constructor expects one input: the name of the file to open or create. The fstream class is derived from the ostream class, hence all of the operations discussed above, including left shift, can be used with file streams:
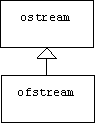
For example, the following code simply writes some strings and integers to a file called "data":
ofstream fs("data");
fs << "Here are some odd numbers:\n";
for(int i = 0; i < 20; i++)
fs << 2 * i + 1 << '\n';
fs << "Here are some even numbers:\n";
for(i = 0; i < 20; i++)
fs << 2 * i << '\n';
Of course the file created is simply a text file that can be inspected using an ordinary editor.
Output String Streams
Unfortunately, streams predated C++ strings; consequently, a large body of translators (i.e., insertion operators such as the one defined earlier for rationals) were developed that converted instances of programmer-defined types into strings that were immediately inserted into output streams. It would seem that these translators couldn't be used in situations where a value needed to be converted into a string that could be used for something other than output.
To remedy this situation, C++ allows strings to be output sinks. An output stream associated with a string is called an output string stream (ostringstream). Like output file streams, the class of output string streams is derived from ostream, hence inherits all of the functionality associated with that class:
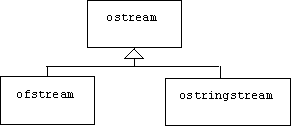
To convert a value to a string, we insert the value into an output string stream using the insertion operator inherited from output streams. The str() member function can then be used to extract the string created inside the string stream. The following function formalizes this idea and makes a valuable addition to our utility library:
template <typename Value>
string toString(const Value& val)
{
ostringstream os;
os << val; // I hope ostream << Value is defined!
return os.str();
}
Here is a sample segment of code that uses this template:
string s1 = "the answer";
string s2 = toString(6 * 7);
string s3 = s1 + " = " + s2;
cout << s3 << endl; // prints "the answer = 42"
Note A.3.2.2: Input Streams
Output is easy, but input is filled with pitfalls that await the unwary due to the gap between the actual and the expected types of incoming data.
Input streams are instances of the istream class. Analogous to output streams, the input file stream class (ifstream) and the input string stream class (istringstream) are derived from the istream class:
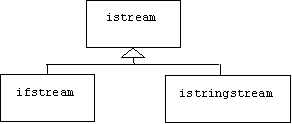
The standard input, mapped to the keyboard by default, is defined in <iostream>:
istream cin; // standard input
The basic service provided by an input stream extracts a single character:
char c = cin.get();
Another version takes a character reference as a parameter:
cin.get(c);
Of course passing a constant to get() doesn't make sense:
cin.get(6 * 7); // error, no place to put the character!
Most streams buffer their characters, so it's possible to put an extracted character back into the input stream:
cin.putback(c);
Or we can simply peek at the next character in the input stream without extracting it:
c = cin.peek();
This is equivalent to:
char temp = cin.get();
cin.putback(temp);
Peek is useful when we need to know if the input stream contains a number before we attempt to extract a number:
inline bool numberIsNext(istream& is = cin)
{
return isdigit(is.peek()); // isdigit() from <cctype>
}
It's also possible to extract C and C++ strings from an input stream:
char buffer[80];
cin.getline(buffer, 80);
string response;
getline(cin, response);
The first version extracts up to 79 characters from cin and places them in buffer, followed by a null character. For both functions the extraction stops if the end of file or a newline character is encountered. If a newline character is encountered, it is discarded.
Translators are available for input streams, too. For example:
double x;
cin >> x;
extracts characters up to the first character that cannot be construed as part of a double, translates these characters into the binary representation of a double, then assigns this double to x.
Of course if the extracted characters can't be construed as a double, for example, if the user types "nine" instead of "9", then the translator quietly fails. No error message is printed, no exception is thrown. Instead, a failure flag deep inside cin is set and subsequent read operations do nothing when executed.
A quick way to determine if the failure flag for a stream has been set is to compare the stream to 0, the null pointer. Since the extraction operator always returns its stream argument, we can extract characters and test for failure in a single operation:
while(!(stream >> x)) repair(stream);
process(x);
As with the insertion operator, several extraction operations can be chained on the same line.
double x, z;
int y;
cin >> x >> y >> z;
Right shift is right-to-left associative, so this is the same as:
(((cin >> x) >> y) >> z);
Of course we can read strings and characters using the right shift operator:
string s1, s2;
char c;
cin >> s1 >> s2 >> c;
Example: A Square Root Calculator
An important difference between the extraction operator and the get() and getline() is that by default, extraction terminates when the first white space is encountered. This can lead to obscure bugs. For example, assume a simple calculator perpetually prompts the user for a number, calculates and displays the square root of the number, then asks the user if he wants to quit:
void calc()
{
bool more = true;
double x = 0;
char response;
while(more)
{
cout << "Enter a non negative number: ";
cin >> x;
if (x < 0)
cout << "The number must be non negative\n";
else
{
cout << "square root = " << sqrt(x) << endl;
cout << "Press any key to continue or q to quit: ";
// response = cin.get(); this fails!
cin >> response;
more = (response != 'q');
}
}
}
Notice that response was initially read using cin.get(). This fails on most systems because characters are actually extracted from a buffer that contains the entire line that was typed. If the user entered the string "49\n" in response to the first prompt, then after "49" was extracted and converted to 49, the buffer still contains the newline character that terminated the numeric input. Because cin.get() doesn't skip white space, it reads this newline character as the response to the second prompt. The response is different from 'q', so the loop is reentered. The replacement:
cin >> response;
works because the right shift operator skips white space, including the newline character. However, the user can't type "any" key to continue, as the second prompt suggests. Pressing the space bar, tab key, Return key, or Enter key— the usual "any key" candidates —moves the cursor, but doesn't cause any character to be extracted.
To solve this problem, we can flush the input buffer after the number is read. This is done with the synchronize function:
while(more)
{
cout << "Enter a non negative number: ";
cin >> x;
cin.sync(); // flush cin's buffer
if (x < 0)
cout << "The number must be non negative\n";
else
{
cout << "square root = " << sqrt(x) << endl;
cout << "Press any key to continue or q to quit: ";
response = cin.get();
more = (response != 'q');
}
}
A much bigger problem is what happens if the user enters the string "forty-nine" instead of the string "49"? The extraction of x will fail because the string can't be converted into a number. At that point cin enters the fail state. No input operations can be performed while an input stream is in this state. On most systems this means the program spins wildly around the while loop, prompting the user, but never pausing to read an answer. (Try <Ctrl>c to interrupt.)
The failure flag of a stream can be cleared using the clear() function. Here's a template function that uses these features to safely read from cin:
template <typename Data>
void getData(Data& var, const string& prompt)
{
Data response;
cout << prompt + " -> ";
while (!(cin >> response))
{
cerr << "Invalid entry, ";
cerr << "please try again or type <Ctrl>c to quit\n";
cin.clear(); // clear failure flag
cin.sync(); // flush buffer
cout << prompt + " -> ";
}
cout << "You entered " << response << endl;
var = response;
}
In our calculator example we can now replace the lines:
cout << "Enter a number: ";
cin >> x;
by the single line:
getData(x, "Enter a number");
Input File Streams
We can construct an input file stream from a file name:
ifstream ifs("data.txt");
If the file isn't found or if its permission level doesn't allow reading, then ifs will enter the fail state (i.e., it is set equal to 0):
if (!ifs)
{
cerr << "can't open file\n";
exit(1);
}
We can use the null test again to determine when the end of the file is reached. This is more reliable than the eof() function, because that returns false even when only white space characters remain in the file:
while(ifs >> val) { ... }
For example, the following function computes the average of a file of numbers:
double avg(const string& source)
{
double num, total = 0;
int count = 0;
ifstream ifs(source.c_str()); // won't work with C++ strings!
if (!ifs) error("can't open file");
while (ifs >> num)
{
total += num;
count++;
}
return total/count;
}
Of course if a non number is encountered in the file, even so much as a punctuation mark, the loop will exit and return the average of the numbers seen.
Input String Streams
Strings are character sources for input string streams. Here's the mate to the earlier template function that translated values to strings. This one translates strings into values. We must pass the value as a reference parameter so C++ can infer Value from calls to the function:
template <typename Value>
void fromString(Value& val, const string& str)
{
istringstream is(str);
is >> val; // I hope istream >> Value is defined!
}
For example, here's how we could convert the string "123" into the integer 123:
int x;
fromString(x, "123"); // x = 123
Note A.3.2.3: Stream Structure
Officially, a stream consists of three parts: a translator, a specification, and a stream buffer. The stream buffer encapsulates and manages an array of characters (i.e. the character buffer) waiting to be transferred to the program or to the output sink. The specification maintains the status and format state of the stream as well as a pointer to the stream buffer. Stream buffers are instances of the streambuf class, istream and ostream instances are translators, and specifications are instances of the ios class. Oddly, the designers of the stream library picked specialization as the relationship between translators and specifiers:
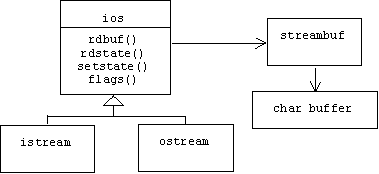
Programmers rarely need to directly access stream buffers, but if they do, they can use the rdbuf() function inherited from the ios base class to obtain a pointer to it. For example, one drawback of the input stream peek() function is that if there are no characters in the buffer, it blocks program execution until one shows up. This makes it unusable for situations where programmers want to poll multiple input streams. However, the streambuf class has a member function called in_avail() that returns the number of characters in the buffer without blocking. We can use this to create a useful stream-level version of the function:
inline int moreChars(istream& is = cin)
{
return is.rdbuf()->in_avail();
}
A stream also inherits functions from its specification that allow programmers to determine its state. For example, if s is an input stream, then:
int state = s.rdstate();
Although the state is an integer, it gets interpreted as a sequence of flags or bits indicating the status of s. We can access these bits directly with the predicates:
s.good() // next operation might succeed
s.eof() // end of file seen
s.fail() // next operation will fail
s.bad() // stream is corrupted
If s.good() is false, then subsequent extraction operations are no-ops. If s.bad() is true, forget it. The stream is broken. If s.fail() is true, then the stream can be repaired. Flush the remaining characters and set the state back to the good state using the setstate() function:
s.sync();
s.setstate(ios::goodbit);
These functions are useful when we want to implement our own translators. Recall the Rational number class declared earlier:
struct Rational
{
int num, den;
// etc.
};
When a user enters a rational number, we expect it to have the form a/b or a, where a and b are integers. Failure to meet any of these requirements results in setting the input stream state to fail, and returning immediately. For example, the inputs 3/x, 3\5, and x/5 should all result in a failed state. But what happens if the user types a single integer followed by some white space and a newline? Our policy will be to interpret this as a rational with denominator 1. We can use peek() to see if the next character is white space. Of course if the user enters "3 /5" this will be interpreted as 3/1 and the " /5" will be left in the buffer:
istream& operator>>(istream& is, Rational& rat)
{
rat.den = 1;
char c; // slash stored here
is >> rat.num;
if (is.good()) // valid numerator read
{
if (isspace(is.peek())) return is; // rat = num/1
is >> c >> rat.den;
if (c == '/' && is.good()) return is; // rat = num/den
}
is.setstate(ios::failbit);
return is;
}
The line:
is.setstate(ios::failbit);
explicitly sets the fail bit if is. Of course if the user enters a non-integer numerator or denominator, the fail bit will already be set. However, if the user enters a valid numerator and denominator, but doesn't separate them with a slash, for example, if the user enters 3\5 instead of 3/5, then the fail bit won't be set automatically, so we must do it manually.
Note A.3.2.4: Format State
Output format is controlled by a sequence of flags in the specifier. Users can create their own sequence of format flags by combining predefined masks using bitwise disjunction:
const ios::fmtflags my_flags =
ios::boolalpha | // symbolic rep of true & false
ios::hex | // hex vs. oct vs. dec
ios::right | // alignment
ios::fixed | // fixed vs. scientific vs. float
ios::showpos | // +3 vs. 3
ios::unitbuf | // flush buffer after each output
ios::uppercase; // 3E5 vs. 3e5
The old flags are saved and the new ones installed by calling the flags() function:
ios::fmtflags old_flags = cout.flags(my_flags);
In addition, the minimum width of the print field and the fill character can be set:
cout.width(20);
cout.fill('.');
Now the statement:
cout << "hi\n";
produces the output:
.................hi
The width reverts to 0 after each output operation.
Flags can be set or cleared individually using setf() and unsetf():
cout.unsetf(ios::uppercase);
cout.setf(ios::showbase);
Some flags have three values instead of two:
cout.setf(ios::oct, ios::basefield);
Programmers can control the format and precision of floating point output. For example, assume the following declarations are made:
long double pi = acos(-1);
long double big = 1e50;
long double small = 1e-50;
Using the default format settings, executing the lines:
cout << "pi = " << pi << '\n';
cout << "big = " << big << '\n';
cout << "small = " << small << '\n';
produces the output:
pi = 3.14159
big = 1e+050
small = 1e-050
If we change the floating point field in the format flag to scientific notation:
cout.setf(ios::scientific, ios::floatfield);
then the insertion statements will produce the output:
pi = 3.141593e+000
big = 1.000000e+050
small = 1.000000e-050
If we change the floating point field in the format flag to fixed point notation:
cout.setf(ios::fixed, ios::floatfield);
then the insertion statements will produce the output:
pi = 3.141593
big = 100000000000000010000000000000000000000000000000000.000000
small = 0.000000
We can restore the general format by setting the floating point field to 0:
cout.setf(0, ios::floatfield);
We can change the precision of the output using the precision() member function:
cout.precision(4);
Notice that when we execute the insertion commands, only three digits are shown beyond the decimal point in pi:
pi = 3.142
big = 1e+050
small = 1e-050
Manipulators
Manipulators are functions that can be applied to output streams using the left shift operator syntax. For example, executing the statements:
cout << boolalpha << true << endl;
cout << setprecision(4) << 123.456789 << endl;
cout << hex << 42 << endl;
produces the output:
true
123.5
2a
Consult your online documentation or [STR] for a complete list of manipulators and to learn how to create your own manipulators.
Note A.3.2.5: Input/Output Streams
C++ also provides an iostream class that multiply inherits from istream and ostream. The main purpose of iostream is to serve as a base class for fstream— the class of all file streams that can be opened for reading or writing —and stringstream— the class of all string streams that can be read from or written to:
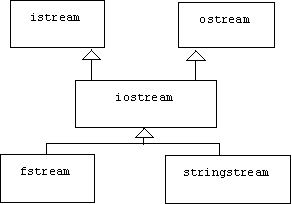
For example, we initially declare an fstream without a file name:
fstream fs;
The open() function is used to associate the fstream with a file and a flag (statically defined in ios) indicating if the file is to opened for input or output:
fs.open("data.txt", ios::out);
if (!fs)
{
cerr << "Can't open data.txt\n";
exit(1);
}
We can write data into a file stream the same way we would write data into and output stream:
for(int i = 0; i < 20; i++)
fs << i * i << endl; // << consecutive squares
If we now wish to reopen the same file for input, we first clear its error flag using the clear() function (this flag would have been set if we reached the end of the file), then close it using the close() function:
fs.clear();
fs.close();
then call the open() function a second time, but using the input flag, ios::in:
fs.open("data.txt", ios::in);
if (!fs)
{
cerr << "Can't open data.txt\n";
exit(1);
}
We can now read data from the file the same way we would read from any input stream:
int x;
while(fs >> x)
cout << "x = " << x << endl;
Readers should consult [STR] or on line documentation to gain a more comprehensive view of C++ I/O.
Note A.4: Error Handling
Assume an application is assembled from independently developed modules. How should errors detected by module M be handled? M has four choices:
1. Ignore the error.
2. Flag the error.
3. Display an error message, then gracefully terminate the program.
4. Repair the error, then continue.
The first option is just lazy programming. Ignoring an error will probably cause the program to enter an unstable state and eventually crash. When a program crashes, the operating system may print a cryptic message such as "core dump" or "segmentation violation," or the operating system may also enter an unstable state and eventually crash, requiring a reboot of the computer.
The second option is the one employed by the standard stream library. For example, when we attempt to extract a number from an input file stream, s, that doesn't contain a number, or when we attempt to associate s with a file that doesn't exist, then s enters a fail state, which we can detect by calling s.fail() or by comparing s to the null pointer. If we forget to occasionally check the state of s and repair it if it has failed:
if (s.fail())
{
s.sync();
s.setstate(ios::goodbit);
}
then subsequent operations on s quietly turn into no-ops (i.e., operations that do nothing when they are executed). The program will speed passed subsequent read operations without pausing to extract data. Setting error flags places too much trust and too much burden on client modules.
The third option is ideal when we are debugging an application. When a problem occurs, the programmer wants to know what and where, which is what a good error message should tell him. Graceful termination means the program stops immediately and returns control to the operating system or debugger. We can achieve both of these goals by defining and calling a universal error() function:
inline void error(const string& gripe = "unknown")
{
cerr << "Error, " << gripe << "!\n";
exit(1);
}
The exit() function terminates the program and returns a termination code to the operating system or debugger. Termination code 0 traditionally indicates normal termination, while termination code 1 indicates abnormal termination.
After an application has been released to clients, option 3 is no longer acceptable. Clients will be annoyed if the program terminates unexpectedly and they lose all of their unsaved data. We must use option 4 in this situation. When an error is detected, the program must trace back to the point where the error was introduced. The state of the program at this point must be restored. If the error was caused by a bad user input, for example, then the program might prompt the user to reenter the data.
The problem with option 4 is that just because module M may detect an error, doesn't mean module M can repair the error. In fact, handling the error should be left up to client modules. For example, assume M is a package of mathematical functions called Math and UI is a user interface package that uses Math:
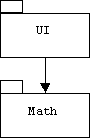
Suppose the UI package prompts the user for a number x, then some time later passes x to a log() function defined in Math and displays the result:
double x;
cout << "enter a number: ";
cin >> x;
// etc.
double result = Math::log(x);
cout << "result = " << result << endl;
// etc.
Suppose the user entered a negative number. Of course Math::log() will probably detect that its input is negative and therefore does not have a logarithm. But what should Math::log() do about the bad input? It's the responsibility of the UI package to interact with the user. If the log() function attempts to bypass the UI by reporting the error directly to the user and asking for another input, then it limits its reusability. For example, we wouldn't want to use such a function in a system with a graphical user interface. Also, result may be needed by subsequent calculations just as x may have been needed by previous calculations. Computing the log of a different number may not be relevant in this context.
Perhaps functions in the Math package could return some sort of error tokens to client packages when they detect bad inputs. This idea isn't bad, but it has several drawbacks. First, what should the error token be? For example, if a function returns a double, then we must either agree on a designated double to be used as the error token, which means this number can never be a normal return value. For example, many platforms provide a floating point representation of NaN (Not a Number), which can be referenced in C++ by the expression:
numeric_limits<double>::quiet_NaN
Of course we will have to do this for all possible return types. Alternatively, we could assign output values to a reference parameter and return a Boolean flag indicating if the operation was successful:
bool log(double value, double& result)
{
if (value < 0) return false; // log failed
result = ...; // calculate log of value
return true; // log succeeded
}
A bigger problem is that clients must check for the error token each time a function is called. If the return value is an error token, then the client must either handle the error or return an error token to its caller. For example, the following function uses our log() function to calculate the maximum data rate of a communication channel with bandwidth bw and signal-to-noise ration snr:
bool dataRate(double snr, double bw, double& result)
{
double factor;
if (!log(1 + snr, factor)) // factor = log of 1 + snr
return false; // dataRate failed
result = bw * factor;
return true; // dataRate succeeded
}
Catch and Throw
C++, Java, and other languages provide an error reporting mechanism that is similar to the idea of returning error tokens. When a function detects an error, it creates an error token called an exception, then uses the throw operator to "return" the exception to its caller:
double log(double x)
{
if (x <= 0)
{
BadInputException exp(x);
throw exp;
}
// calculate & return logarithm of x
}
A throw statement is similar to a return statement: it causes log() to terminate immediately. However, the exception returned by the throw statement is an arbitrary object that doesn't need to match the return type of the function. In our example the exception is an instance of an error token class we invented for representing and encapsulating all bad inputs:
class BadInputException
{
public:
BadInputException(double x = 0) { irritant = x; }
double getIrritant() { return irritant; }
private:
double irritant;
};
Any other type of object could be thrown instead:
double log(double x)
{
if (x <= 0)
{
string exp("bad input");
throw exp;
}
// calculate & return logarithm of x
}
C++ even allows us to specify the types of exceptions a function might throw. For example, assume we define two exception classes for distinguishing between negative and zero inputs:
class NegInputException: public BadInputexception { ... };
class ZeroInputException: public BadInputexception { ... };
Here is how we can specify that our log() function might throw either exception:
double log(double x) throw (NegInputException, ZeroInputException)
{
if (x < 0) throw NegInputException(x);
if (x == 0) throw ZeroInputException();
// calculate & return logarithm of x
}
Unlike Java, the compiler doesn't require us to declare which exceptions a function might throw. Also, the C++ compiler doesn't generate an error if a function throws a different type of exception than the ones specified. If this happens a system function named unexpected() is automatically called. The default implementation of unexpected() terminates the
program.
How does the calling function know if the called function throws an exception, and if so, what should it do? For example, let's re-implement the dataRate() function described earlier. Recall that this function uses our log() function to calculate the maximum data rate of a communication channel with bandwidth bw and signal-to-noise ration snr:
double dataRate(double snr, double bw)
{
double factor = log(1 + snr);
return bw * factor;
}
If snr <= -1, then log(1 + snr) will throw an exception. If this happens, then dataRate() implicitly throws the exception to its caller at the point where log() is called. In particular, dataRate() terminates immediately. The assignment and return statements are never executed.
C++ allows us to specify implicitly thrown exceptions, too:
double dataRate(double snr, double bw)
throw (NegInputException, ZeroInputException)
{
double factor = log(1 + snr);
return bw * factor;
}
In this way an exception explicitly thrown by log() is automatically propagated through the chain of calling functions. But how is the exception ultimately handled? If no function handles the exception, then the system-defined function named terminate() is automatically called. The default implementation of terminate() terminates the program.
If we think we can completely or partially handle some of the exceptions that might be thrown by certain functions, then we call these functions inside of a try block:
try
{
fun1(...);
fun2(...);
// etc.
}
One or more catch blocks immediately follow a try block:
catch(NegInputException e)
{
// handle negative input exception here
}
catch(ZeroInputException e)
{
// handle zero input exception here
}
// etc.
The thrown exception is passed to the catch block through the parameter specified in the parameter list following the reserved word "catch". The parameter type is used to control which handler is invoked when an exception is thrown. For example, if fun1() throws a ZeroInputException, then control is automatically transferred to the first line inside the second catch block.
Suppose our UI package calls dataRate(). Here is how we might handle the negative input exception it throws:
void controlLoop()
{
while(true)
try
{
double bw, snr, rate;
cout << "enter bandwidth: ";
cin >> bw;
cout << "enter signal to noise ratio: ";
cin >> snr;
rate = dataRate(snr, bw);
cout << "maximum data rate = " << rate << " bits/sec\n";
}
catch(NegInputException e)
{
cerr << "signal to noise ratio must not be < -1\n";
cerr << "you entered " << e.getIrritant() - 1 << endl;
cerr << "please try again\n";
}
}
If we enter a signal to noise ratio of –2, then the following output is produced:
enter bandwidth: 30000
enter signal to noise ratio: -2
signal to noise ratio must not be < -1
you entered -2
please try again
enter bandwidth:
If we enter a signal to noise ratio of –1, then dataRate() implicitly throws a ZeroInputException. Because controlLoop() doesn't catch this type of exception, it too implicitly throws the exception.
If controlLoop() wanted to handle both exceptions, we could add an extra catch block for the ZeroInputException:
catch(ZeroInputException e)
{
cerr << "signal to noise ratio must not be -1\n";
cerr << "please try again\n";
}
Alternatively, since ZeroInputException and NegInputException are both derived from BadInputException, we could handle both in a single catch block:
void controlLoop()
{
while(true)
try
{
double bw, snr, rate;
cout << "enter bandwidth: ";
cin >> bw;
cout << "enter signal to noise ratio: ";
cin >> snr;
rate = dataRate(snr, bw);
cout << "maximum data rate = " << rate << " bits/sec\n";
}
catch(BadInputException e)
{
cerr << "signal to noise ratio must not be <= -1\n";
cerr << "you entered " << e.getIrritant() - 1 << endl;
cerr << "please try again\n";
}
}
Standard Exceptions
Unlike the flag-setting stream library, the standard template library throws exceptions when things go wrong. The pre-defined exception classes are defined in the <stdexcept> header file:
#include <stdexcept>
The base class for all STL exceptions is exception class.
class exception
{
public:
exception() throw();
exception(const exception& rhs) throw();
exception& operator=(const exception& rhs) throw();
virtual ~exception() throw();
virtual const char *what() const throw();
};
The what() member function normally returns an error message encapsulated by the exception.
The two principle derived classes are logic_error and runtime_error, although there are a number of other exception classes derived from exception:
The distinction between these two classes is a little shaky. Presumably, a logic error occurs when a bad thing happens to a bad program. In other words, a logic error is an error in the program, such as passing an invalid argument, using an index that's out of range, attempting to access elements in an empty container, etc. A runtime error occurs when a bad thing happens to a good program. In other words, a runtime error is an error caused by the program's environment, not the program itself, such as an overflow or underflow error. More commonly, runtime errors are thrown when information specified by the user, such as the name of a file to be opened or the index of an array to be accessed, is invalid.
For example, here is how we might deal with the problem of attempting to open a missing or protected file:
ifstream& openFile(const string& fname) throw(runtime_error)
{
ifstream ifs(fname.str());
if (!ifs) throw runtime_error(string("can't open ") + fname);
return ifs;
}
Here is a list of the current exception classes defined in the standard C++ library. Indentation indicated derivation depth:
exception
logic_error
length_error
domain_error
out_of_range
invalid_argument
bad_alloc
bad_exception
bad_cast
bad_typeid
ios::base::failure
runtime_error
range_error
overflow_error
underflow_error
Note A.4.1: The error() function
We can improve the error() function mentioned earlier by controlling its behavior with a global flag indicating if we are in debug or release mode:
// set to false before release build
#define DEBUG_MODE true
In debug mode, the error() function prints an error message and terminates the program. In release mode a runtime error is thrown:
inline void error(const string& gripe = "unknown")
throw (runtime_error)
{
if (DEBUG_MODE)
{
cerr << "Error, " << gripe << "!\n";
exit(1);
}
else // release mode
throw runtime_error(gripe);
}
One problem with this approach is that it prevents us from being more specific about the type of exception we are throwing, hence we can't steer our exception to a particular catch block.
Example
Assume an application will consist of a provider module called Engine and a client module called Car:
Of course the implementer of the Engine module may have no knowledge of the Car client module. Indeed, there may be other client modules.
When problems occur in the Engine module, exceptions are thrown. It's up to the client module to decide how to handle these exceptions. The Engine module can help its clients by providing a carefully designed hierarchy of exceptions. This allows the client to decide the granularity of exception handling. Fore example, should an exception indicating that the oil is low be handled by the same function that handles exceptions indicating that the gas is low? Remember, making this decision is the client's privilege.
Engines
The Engine subsystem contains several types of engines together with a hierarchy of exceptions representing typical engine problems:
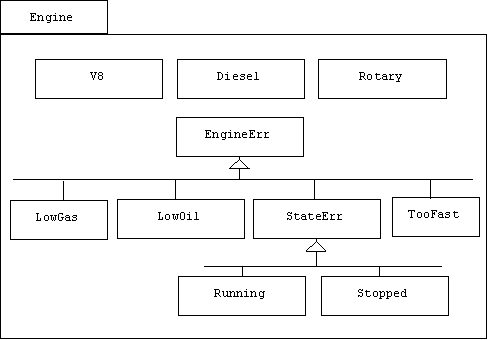
We can implement the Engine subsystem as a C++ namespace:
namespace Engine
{
class EngineErr { ... };
class LowOil: public EngineErr { ... };
class LowGas: public EngineErr { ... };
class TooFast: public EngineErr { ... };
class StateErr: public EngineErr { ... };
class Stopped: public StateErr { ... };
class Running: public StateErr { ... };
class V8 { ... };
class Diesel { ... };
class Rotary { ... };
// etc;
} // Engine
Instances of the base class of all engine errors encapsulate error messages:
class EngineErr
{
public:
EngineErr(string s = "unknown error")
{
gripe = string("Warning: ") + s;
}
string what() { return gripe; }
private:
string gripe;
};
We could have derived EngineErr from one of the predefined exception classes such as exception or runtime_error:
class EngineErr: public runtime_error { ... };
This would give clients the option of treating all exceptions the same way.
The LowOil, LowGas, and TooFast exceptions encapsulate the current oil, gas, or engine speed, respectively. For example:
class LowOil: public EngineErr
{
public:
LowOil(double amt): EngineErr("oil is low!") { oil = amt; }
double getOil() { return oil; }
private:
double oil;
};
State errors occur when we try to drive a car isn't running or change the oil in a car that is running:
class StateErr: public EngineErr
{
public:
StateErr(string gripe = "Invalid state"): EngineErr(gripe) {}
};
For example, here is the exception thrown when we attempt to change oil in a running car:
class Running: public StateErr
{
public:
Running(): StateErr("engine running!") {}
};
A typical engine is the V8:
class V8
{
public:
V8(double g = 10, double o = 2);
void print(ostream& os = cout);
void start() throw(LowGas, LowOil, Running);
double getGas() throw(Running);
double getOil() throw(Running);
void run() throw(LowGas, LowOil, Stopped, TooFast);
void stop() throw(Stopped, exception);
private:
double gas; // = gallons of gas
double oil; // = quarts of oil
double rpm; // = engine speed in roations per minute
bool running;
};
The implementation of run() first passes through a gauntlet of throw statements:
void Engine::V8::run() throw(LowGas, LowOil, Stopped, TooFast)
{
if (!running) throw Stopped();
if (gas < .25) throw LowGas(gas);
if (oil < .25) throw LowOil(oil);
if (8000 < rpm) throw TooFast(rpm);
gas *= .5;
oil *= .8;
rpm *= 2;
}
Here is the implementation of getGas():
double Engine::V8::getGas() throw(Running)
{
if (running) throw Running();
gas = 10; // fill it up
return gas;
}
Cars
The Car subsystem depends on the Engine subsystem:
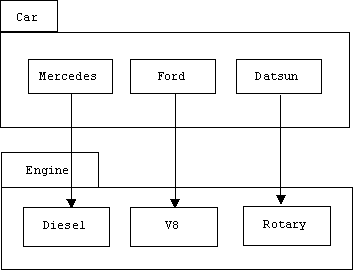
We can represent the Car subsystem as a C++ namespace:
namespace Car
{
using namespace Engine;
class Ford
{
public:
Ford(V8* eng = 0) { myEngine = eng; speed = 0; }
void start() throw(LowGas, LowOil);
void drive() throw(LowGas, LowOil, Stopped, TooFast)
{
myEngine->run();
speed += 10;
}
void stop() throw();
void print(ostream& os = cout);
void getGas() throw(Running) { myEngine->getGas(); }
void getOil() throw(Running) { myEngine->getOil(); }
private:
V8* myEngine;
double speed; // = driving speed in miles/hour
};
class Datsun { ... };
class Mercedes { ... };
// etc.
}
Notice that Ford member functions declare the exceptions they implicitly throw. Naturally, the exceptions they handle aren't specified in the exception list. For example, start() catches the Running exception thrown by Engine::start(), so it only throws LowGas and LowOil:
void Car::Ford::start() throw(LowGas, LowOil);
{
try
{
myEngine->start();
}
catch(Running)
{
cout << "engine already running\n";
}
}
Control
The control panel (i.e., dashboard) for an associated car redefines the default terminate() and unexpected() functions:
class DashBoard
{
public:
DashBoard(Car::Ford* car = 0)
{
myCar = car;
oldTerm = set_terminate(myTerminate);
oldUnexpected = set_unexpected(myUnexpected);
}
~DashBoard()
{
set_terminate(oldTerm);
set_unexpected(oldUnexpected);
}
void controlLoop();
private:
Car::Ford* myCar;
terminate_handler oldTerm;
unexpected_handler oldUnexpected;
};
Here are the new versions:
void myUnexpected()
{
cerr << "Warning: unexpected exception\n";
exit(1);
}
void myTerminate()
{
cerr << "Warning: uncaught exception\n";
exit(1);
}
The control loop catches all Engine exceptions:
void DashBoard::controlLoop()
{
bool more = true;
string cmmd;
while (more)
try
{
myCar->print();
cout << "-> ";
cin.sync();
cin >> cmmd;
if (cmmd == "quit")
{
more = false;
cout << "bye\n";
}
else if (cmmd == "start")
{
myCar->start();
cout << "car started\n";
}
else if (cmmd == "drive")
{
myCar->drive();
cout << "car driving\n";
}
else if (cmmd == "stop")
{
myCar->stop();
cout << "car stopped\n";
}
else
cerr << string("unrecognized command: ") + cmmd << endl;
}
catch(Engine::LowGas e)
{
cout << e.what() << endl;
cout << "gas = " << e.getGas() << endl;
cout << "Getting gas ... \n";
myCar->stop();
myCar->getGas();
cout << "Finished.\n";
}
catch(Engine::LowOil e)
{
cout << e.what() << endl;
cout << "oil = " << e.getOil() << endl;
cout << "Getting oil ...\n";
myCar->stop();
myCar->getOil();
cout << "Finished.\n";
}
catch(Engine::TooFast e)
{
cout << e.what() << endl;
cout << "rpm = " << e.getRpm() << endl;
cout << "Car stopping ...\n";
myCar->stop();
cout << "Car stopped.\n";
}
catch(Engine::StateErr e)
{
cout << "Start or stop the car, first!\n";
cerr << e.what() << endl;
}
catch(Engine::EngineErr e)
{
cerr << e.what() << endl;
}
}
Notice that the last catch block will catch all engine exceptions not specified above.
Test Driver
The test driver uses a catch-all block to catch any type of exception (system defined or programmer defined):
int main()
{
try
{
Engine::V8* eng = new Engine::V8(10, 2);
Car::Ford* car = new Car::Ford(eng);
DashBoard dashBoard(car);
dashBoard.controlLoop();
}
catch(...)
{
cerr << "some exception has been thrown\n";
return 1;
}
return 0;
}
Note A.5: Initializer Lists
One of the original design goals of C++ was to eliminate the bug-infested gap between object creation and object initialization. When a C++ object is created, a user-defined or system-defined constructor is automatically called to initialize the object's member variables.
An initializer list is a list of pre-initializations— member variable initializations that occur in the imperceptibly brief gap between object creation and the execution of the first line of the called constructor. Syntactically, the list is announced by a colon and is sandwiched between the header of a constructor and its body:
Class(PARAM, ... PARAM): INIT, ... INIT { STMT; ... STMT; }
Why not initialize all member variables inside the constructor's body? Because some member variables are in "hard to reach" places. For example, inherited member variables may have been declared private in the base class, and nested member variables— i.e., member variables of member objects —may have been declared private in the associated class.
Assume an Employee class has a private member variable called name of type string, which is initialized by Employee constructors. Assume a Manager class and a Secretary class are derived from the Employee class:
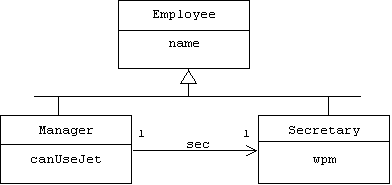
Secretaries have a private integer member variable called wpm, which represents typing speed in words per minute. Managers have a private Boolean member variable called canUseJet, which indicates if recreational use of the company jet is allowed on weekends. Each manager object also has a private member variable called sec of type Secretary, which represents the manager's personal secretary:
class Manager
{
Secretary sec;
bool canUseJet;
public:
Manager(string mnm, string snm, int wpm, bool jet);
// etc.
};
In addition to the explicitly declared canUseJet and sec variables, a manager object also encapsulates the inherited name variable as well as the nested sec.name and sec.wpm. For example, the declaration:
Manager smith("Smith", "Jones", 60, false);
might create an object in memory that looks like this:
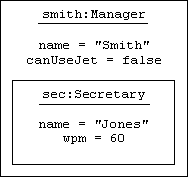
But how can a Manager constructor initialize these implicit member variables? If we leave them uninitialized, then the Employee and Secretary default constructors— if they exist —will be automatically called to perform the pre-initializations, but this doesn't help us.
We can't simply initialize them in the constructor's body:
Manager::Manager(string mnm, string snm, int wpm, bool jet)
{
name = mnm; // error! name is private
sec.name = snm; // error! sec.name is private
sec.wpm = wpm; // error! sec.wpm is private
canUseJet = jet; // ok
}
The Manager constructor could create an anonymous temporary secretary object, then assign it to sec:
Manager::Manager(string mnm, string snm, int wpm, bool jet)
{
sec = Secretary(snm, wpm); // ok, sec = temp
Employee(mnm); // this does nothing!
canUseJet = jet; // ok
}
But this can be inefficient if the default Secretary constructor, which is still automatically called to pre-initialize the sec variable, consumes a lot of time or memory, and of course we still have the problem of initializing the inherited name variable. Calling the Employee constructor inside the body of the Manager constructor only creates a temporary anonymous employee object with a name member variable that is unrelated to the inherited name member variable.
The solution to our problem is to use the initializer list to specify any non-default constructors that should be called to pre-initialize inherited and nested member variables:
Manager::Manager(string mnm, string snm, int wpm, bool jet)
: Employee(mnm), sec(snm, wpm)
{
canUseJet = jet;
}
Notice that the Employee base class constructor is explicitly called, while the Secretary constructor is implicitly called by specifying the arguments after the sec variable.
Note A.5.1: Initializing Constant Members
In addition to inherited and nested private member variables, constant member variables also present an initialization problem. Constants are read-only variables. It's an error for a constant to appear on the left side of an assignment statement:
const double pi;
pi = 3.1416; // error!
So how do we initialize a constant? This must be done in its declaration:
const double pi = 3.1416; // ok, this is not an assignment
But then how do we initialize constant member variables like critical, the constant member of our nuclear reactor class from chapter 2?
class Reactor
{
double temp; // = temperature of reactor's core
const double critical; // critical < temp is too hot!
public:
Reactor(double t = 0, double c = 1500);
// etc.
};
Initializing critical in the constructor's body will be regarded as an illegal assignment statement by the compiler:
Reactor::Reactor(double t, double c)
{
critical = c; // error! critical is read-only
temp = t; // ok
}
Fortunately, we can also use the initializer list to pre-initialize constant members:
Reactor::Reactor(double t, double c)
: critical(c)
{
temp = t; // ok
}
Recall that the initial value of a simple variable can be specified using C syntax:
double critical = c;
or C++ syntax:
double critical(c);
Initializer lists always use the latter form.
What is the advantage of having constant members? Why not simply define critical to be a global constant or a member of an anonymous, nested enumeration:
class Reactor
{
enum { critical = 1500 };
// etc.
};
Well for one thing, members of enumerations must be integers, not doubles. But more importantly, declaring critical to be a constant member means different reactors can have different critical temperatures.
References are essentially constant pointers, so we run into the same initialization problems we faced with constants. For example, assume reactors send notifications of temperature changes to a monitor that is represented by a reference to an output stream:
class Reactor
{
double temp; // temperature of reactor's core
const double critical; // critical < temp is too hot!
ostream& monitor; // send temp change notifications here
public:
Reactor(double t = 0, double c = 1500, ostream& m = cout);
// etc.
};
Like constants, references must be initialized in the initializer list:
Reactor(double t, double c, ostream& m)
: critical(c), monitor(m)
{
temp = t;
}
It turns out that all member variables can be initialized in an initializer list, leaving the constructor body empty:
Reactor(double t, double c, ostream& m)
: critical(c), monitor(m), temp(t)
{ } // no op!
Note A.6: Scope, Visibility, Extent, and Storage Class
A declaration creates a binding between a name and a bindable (e.g., a type, variable, or function). For example, the declaration:
int x;
creates a binding between the name x and an integer variable. (See Programming Note A2.2) Of course a name may be bound to multiple bindables, and a bindable may be bound to multiple names.
The visibility of a binding is the lexical region of the program where the binding is valid. A binding has global visibility if it is visible throughout the entire program, otherwise we say the binding has local visibility.
The extent of a binding (also called the lifetime of a binding) is the period of time that the binding exists. A binding has global extent if it exists from the moment of its declaration until the program terminates, otherwise we say the binding has local extent.
Generally speaking, global visibility implies global extent and local visibility implies local extent, although in some cases a binding with local visibility may have global extent. (Why would global visibility with local extent would be a recipe for disaster?)
Unfortunately, there is no simple or elegant mapping between these concepts and C/C++ terminology. C++ programmers speak of the scope of a name, rather than the visibility of a binding. Even the phrase "scope of a name" is inaccurate. What is really meant is the scope of a declaration, which simply refers to the file, namespace, class, or block in which the declaration occurs.
The scope of a declaration is loosely related to the visibility of the binding it creates. For example, a declaration with block scope creates a binding that is only visible from the point of declaration to the end of the block. A declaration with file scope creates a binding that is visible from the point of declaration to the end of the file, unless the binding is explicitly imported to another file. For example, placing the declaration:
const double pi = 3.1416;
in a source file means the binding between the name pi and the constant 3.1416 is visible from the point of declaration to the end of the file. However, we can refer to this binding in other files by including the pure declaration:
extern const double pi;
Recall that when a C or C++ program is loaded in memory, it is allocated four segments of memory:

In addition, program data can also be stored in the processor's registers. The storage class of a variable refers to the memory segment where the variable is located: register, heap, stack, or static. (C/C++ uses the term automatic to refer to stack variables.)
C++ programmers speak of the storage class of a variable rather than the extent of a binding. There is a loose relationship. For example, bindings to static variables have global extents, while bindings to automatic variables have local extents. (Heap variables come into existence when the new() operator is called and disappear when the delete() operator is called.)
The relationship between the storage class of a variable and the scope of variable's declaration is tricky. Normally, a variable declaration with file scope produces a binding to a static variable, while a variable declaration with block scope produces a binding to an automatic variable. However, we can override this by specifying the storage class in the declaration.
For example, suppose we want to define a function that returns the number of times it has been called. The following definition fails because we keep the call count in a variable created by a block-scope declaration which is created (and initialized to 0) each time the function is called, and is destroyed each time the function terminates:
int numCalls()
{
int count = 0;
return ++count; // wrong: always returns 1
}
We can remedy the situation by specifying the call count to be static:
int numCalls()
{
static int count = 0; // local scope with global extent!
return ++count;
}
Curiously, placing static in front of a file scope declaration limits the scope of the binding it creates to the file in which it is declared. I.e., it cannot be exported into other files.
Scope, visibility, extent, and storage class become very confusing when we think about member variables and functions. For example, consider the following class declaration:
class Account
{
public:
Account(double bal = 0) { balance = bal; }
void withdraw(double amt);
void deposit(double amt);
// etc.
protected:
double balance;
};
All of the member declarations have class scope according to C++ terminology. However, this doesn't tell us much about visibility, extent, or storage class. The declaration of balance, for example, doesn't create a variable. No variable is created until we create some instances of the Account class:
Account a, b, c;
At this point three variables have been created: a.balance, b.balance, and c.balance. The extent and storage class of these variables will be the same as the extend and storage class of a, b, and c, respectively. The visibility of the bindings between these qualified names and the corresponding variables is restricted to member functions of the Account class and all classes derived from the Account class. This is because balance was declared protected.
The unqualified name balance, is bound to all three variables, but the visibility of each binding is restricted to member functions of the Account class and all classes derived from the Account class. In this case the restricted visibility has nothing to do with the fact that balance is a protected member variable, the visibility of the binding remains unchanged even if balance is public! (In truth, the compiler replaces all unqualified references to balance by the qualified reference this->balance.)
Note A.6.1: Static Members
Placing the static specifier in front of a member variable has two consequences. First, static member variables are allocated in the static memory segment, as expected. Second, static member variables are not encapsulated in objects! A static member variable is unique, and it has global extent: it comes into existence before main() begins execution, and disappears when main() terminates.
For example, suppose we want to keep track of the number of account objects that exist. It wouldn't make sense to store the count in an ordinary member variable. In this case every account object would encapsulate a count variable. But this leads to a chicken-versus-egg problem: the count variable only exists if account objects exist to encapsulate it. How could it ever be 0? Also, each time a new account is created or destroyed, we would have to update each remaining account's count variable. We could store the count in a global variable (i.e. a variable created by a file-scope declaration):
int Account_count = 0;
Of course file scope variables have global visibility, so there is a possibility of corruption. The best strategy is to use a private static member variable:
class Account
{
public:
Account(double bal = 0) { balance = bal; count++; }
Account(const Account& acct) { balance = acct.balance; count++; }
~Account() { count--; }
void withdraw(double amt);
void deposit(double amt);
// etc.
private:
double balance;
static int count;
};
Notice that Account constructors increment count while the Account destructor decrements count. (Why was it necessary to define a new copy constructor?)
The chicken-versus-egg problem is solved because the extent of count is global, it isn't tied to the extent of any particular account object. The corruption problem is solved, too. The visibility of count is restricted to Account member functions because it is private.
How will clients access count? Outside of the class scope the variable goes by its qualified name: Account::count, but this doesn't help, because it is still a priavte variable. We could provide a public member function for this purpose:
int Account::getCount() { return count; }
But this leads back to the chicken-versus-egg problem. An account object must exists before we can call its getCount() member function.
Fortunately, member functions can also be declared static:
class Account
{
public:
Account(double bal = 0) { balance = bal; count++; }
Account(const Account& acct) { balance = acct.balance; count++; }
~Account() { count--; }
void withdraw(double amt);
void deposit(double amt);
static int getCount() { return count; }
// etc.
private:
double balance;
static int count;
};
Unlike ordinary member functions, static member functions don't have implicit parameters. This means they can be called even if no instance of the class exist. For example, here's how a client might display count:
cout << Account::getCount() << endl;
One last problem: how will Account::count get initialized to 0? We can't initialize it in an Account() constructor, because constructors are only called when objects are created and they are called each time an object is created. In fact, the declaration of count is only a pure declaration, it does not bind Account::count to any particular variable, it only says that it will be bound to a variable. We still need the definition:
int Account::count = 0;
This definition would normally be a file-scope declaration in a source file such as account.cpp.
Note A.7: Type Conversion
Sometimes strict type checking can limit the flexibility of an algorithm. For example, it would be a real headache if the cos() function refused to accept integer arguments:
cos(0); // error, argument must be a float?
Fortunately, the C++ compiler recognizes many of these situations and automatically converts the given value to an equivalent value of the expected type.
In some situations this might involve actually transforming the internal representation of the value. This is called coercion. For example, the C++ compiler automatically translates cos(0) to cos(0.0). Of course the internal representation of 0 is quite different from the internal representation of 0.0.
In other situations the internal representation doesn't need to change, it only needs to be temporarily retyped. For example, assume the following inheritance hierarchy has been defined:
Assume we define a pointer to an executive object:
Executive* smith = new Executive(...);
We can freely use this pointer in contexts where pointers to employees are expected:
Employee* employee = smith;
In this case the compiler simply retypes the pointer to the expected type. The actual value of the pointer doesn't need to change because a pointer to an Executive is— technically and logically —a pointer to an Employee.
C/C++ uses the term casting to refer to both coercion and retyping. Retyping an Executive pointer to an Employee pointer is called up casting because the target type is a base class of the original type. Up casts are performed automatically by the compiler, as required. A cast that is performed automatically is called an implicit cast.
By contrast, a down cast replaces the original type with a more specialized derived class. Of course this only makes sense if the pointer actually points to an instance of the more specialized class. For example, assume we need a single pointer that can be used to point at all types of employees. Only an Employee pointer allows this flexibility:
Employee* emp;
At one point in our program we point our emp pointer at an Executive object:
emp = new Executive(...);
Assigning an Executive pointer to an Employee pointer is an up cast, so the C++ compiler automatically performs the necessary retyping operation. Now suppose we want to find out the bonus of this employee using the Executive::getBonus() member function:
cout << emp->getBonus() << endl; // error
This generates a compile-time error because the C++ compiler has no way of knowing that emp actually points to an Executive object, and of course there is no Employee::getBonus() member function.
Of course we know that emp points to an Executive, so we can tell the compiler to perform the cast using the static_cast() operator:
Executive* exec = static_cast<Executive*>(emp);
cout << exec->getBonus() << endl; // okay
We can also use the traditional C syntax to perform static casts:
Executive* exec = (Executive*)emp;
If a type has a simple name, for example if we introduce ExecPointer as a synonym for pointers to Executives:
typedef Executive* ExecPointer;
then we can also use "function call" syntax to perform static casts:
Executive* exec = ExecPointer(emp);
In contrast to implicit casts, casts performed by the programmer— regardless of the syntax used —are called explicit casts.
We have to be careful, though. If emp doesn't really point at an Employee, if emp points at a Programmer instead:
emp = new Programmer(...); // allowable upcast
then our static cast forces the compiler to point an Executive pointer at a Programmer object, and calling exec->getBonus() causes the program to crash or, worse yet, produces the incorrect answer.
We can guard against this type of error by using the dynamic cast operator, which uses runtime type information (RTTI, see chapter 6) to determine if the object is actually an instance of the target type. If not, then the null pointer, 0, is returned:
Executive* exec;
if (exec = dynamic_cast<Executive*>(emp))
cout << exec->getBonus() << endl;
else
cerr << "invalid cast\n";
Note: dynamic casting requires the base class to be virtual (i.e., at least one member function must be virtual, the destructor for example). Also, some compilers may require special RTTI options to be designated.
When we introduce multiple inheritance into our hierarchy, then we allow the possibility of cross casts. For example, assume a company's chief executive officer (CEO) must be an employee and a stock holder:
Assume an Employee pointer actually points at a CEO object:
Employee* gates = new CEO();
At some point in the program we may want to know how many shares of stock gates owns, but Employee is neither a base class nor a derived class of StockHolder, so neither an up cast nor a downcast will work in this situation, and consequently the static cast:
static_cast<StockHolder*>(gates);
causes a compile-time error. Retyping gates as a StockHolder is called a cross cast because the target type is a peer of the original type. Cross casts must be performed dynamically:
dynamic_cast<StockHolder*>(gates);
C++ also offers the reinterpret_cast() and const_cast() operators. The const_cast() operator is used to retype a variable of type const T* to a variable of type T*. For example:
void review(const Executive* exec)
{
if (hasOtherOffers(exec))
{
Executive* temp = const_cast<Executive*>(exec);
temp->setBonus(1000000);
}
}
Of course review(smith) only changes smith.bonus if smith was not declared as a constant.
The reinterpret_cast() operator is the elephant gun of casting operators. Using it, we can force the compiler to perform static casts it would otherwise disallow. For example, the compiler would normally disallow a static cast from a pointer to an integer::
Executive* smith = new Executive();
int location = static_cast<int>(smith); // error!
But if we are real sure we know better than the compiler, then we can force the retyping operation:
int location = reinterpret_cast<int>(smith);
Note A.7.1: Programmer-Defined Coercions
We can declare a coercion from an existing type, T, to a programmer-defined class, C, by simply declaring a constructor for C that expects a single parameter of type T.
C::C(T t) { ... }
We can declare coercion from C to T by defining a member function for C that overloads the T() casting operator (i.e., the operator called by T(exp)):
C::operator T() { ... }
The C++ compiler will automatically call the appropriate coercion when it sees an instance of C appearing in a context where an instance of T is expected, and vice-versa.
For example, suppose we define a rational number class with two integer member variables representing numerator and denominator:
class Rational
{
int num, den; // = num/den
public:
Rational(int n = 0, int d = 1) { num = n; den = d; }
// etc.
};
Every integer, n, can be interpreted as the rational n/1, therefore we would like to be able to use integers in contexts where rational numbers are expected. For example, we would like to be able to assign an integer to a Rational variable:
Rational r;
r = 6; // r = 6/1
In this case the compiler will automatically search for a Rational constructor that expects a single integer parameter. If it finds one, it will translate the assignment as:
r = Rational(6);
In our example, the compiler will use the constructor above with the default second argument:
r = Rational(6, 1); // r = 6/1
Every rational number can be approximated by a floating point number. For example, 7/6 could be approximated by 1.166660. In general, the rational n/m is approximated by the floating point result of dividing n by m. Therefore, we would like to be able to use rationals in contexts where floating point numbers are expected. For example, we may want to assign a rational number to a variable of type double:
Rational r(7, 6);
double x;
x = r; // x = 1.166660
Defining a Rational constructor that expects a single parameter of type double doesn't help, because it would coerce doubles to rationals, and we need to go the other way; we need to coerce rationals to doubles. This is easy to do if we realize that static casts such as:
double(r);
are actually calls to an operator that can be overloaded. The syntax is a little weird, though. The official name of the operator is "operator double()" (i.e., a blank space is part of the name!). Also, this operator must always return a double, so as with constructors, C++ doesn't allow programmers to specify the return type. (Otherwise the compiler would need to decide how to respond if the programmer specified the wrong return type.) Here is our definition of the double() operator for rationals:
class Rational
{
int num, den; // = num/den
public:
Rational(int n = 0, int d = 1) { num = n; den = d; }
operator double() { return double(num)/double(den); }
// etc.
};
The compiler will automatically translate the assignment given above to:
x = double(r);
Note A.8: A few facts about LISP
We occasionally contrast C++ with LISP, a flexible, interpreted, expression-oriented language developed by John McCarthy in 1960. LISP is commonly used to implement artificial intelligence applications such as expert systems. Our examples use the Scheme dialect of LISP. Technically speaking, Scheme isn't a dialect of LISP, because it doesn't conform to the Common LISP standard.
LISP syntax is strange. There are no infix operators, only prefix operators, and a function's name or operator symbol is placed inside its argument list! For example, the expression
30 + 12 is written as:
(+ 30 12)
the expression 6 * 5 + 4 * 3 is written as:
(+ (* 6 5) (* 4 3))
and the expression sin(atan(x, y)) is written as:
(sin (atan x y))
Unlike C++ functions, the body of a LISP function consists of a single return statement. This is because although assignment statements are available in LISP, their use is de emphasized, and so there's not much else to do in the body of a LISP function other than to return the value produced by a parameterized expression. Furthermore, because return statements are the only statements in the body, there's no need for an explicit return command as in C++. For example, the C++ function:
double square(double x) { return x * x; }
Would be defined in LISP by:
(define (square x) (* x x))
See [PEA] for more details on the Scheme dialect of LISP.
Note A.9: A few facts about Java
Note A.9.1: The Object Base Class
All Java classes implicitly specialize Java's Object class. This makes it easy to create heterogeneous containers such as stacks, because we can generically refer to the items stored in the stack as objects:
class Stack
{
private int MAX = 100;
priave int size = 0;
private Object[] items = new Object[MAX];
public void push(Object x) { if (size < 100) items[size++] = x; }
public Object pop() throws Exception
{
if (size <= 0) throw new Exception("Stack empty");
return items[--size];
}
// etc.
}
Of course clients must down cast items popped off the stack:
Pancake breakfast = (Pancake)PancakeStack.pop();
In addition, we can put useful operations in the Object base class that we want all objects to inherit. For example, Java's Object class includes the methods clone(), getClass(), and toString(). Java's Object base class is comparable to MFC's CObject base class.
Note A.9.2: Specifying Member Access
Unlike C++, each member of a Java class must be declared public, protected, or private. Unfortunately, specifying the access of every single member gets to be quite tiring. If we forget to specify the access of a member, then the default is package scope, which means the member is visible to member functions in other classes defined in the same package.
Note A.9.3: Virtual Functions
By default, all Java member functions are virtual functions. In other words, selecting the variant of an overloaded member function is done dynamically. If we don't want a function to be virtual, then we must explicitly declare it to be non-virtual by writing the reserved word "final" in front of the function's declaration:
class MathTools
{
final public double sin(double x) { ... }
// etc.
}
Note A.9.4: References
Java variables don't hold objects, instead, they hold references to heap-based objects. (A reference is a pointer that automatically dereferences itself.) For example, the declaration:
Animal x;
does not create any object, x is merely a variable that can hold a reference to an object. Of course we can assign a reference to any instance of a class that extends the Animal class, and the up cast will be performed automatically:
x = new Fish();
The analogous situation in C++ would be:
Animal& x = Fish();