Class-Level Refactorings
Introducing and Eliminating Classes
Extract Subclass
Problem
A class has features that are only used by some instances.
Before
Our Aircraft class contains a hover method only certain types of aircraft don't perform:

class Aircraft {
private double speed, altitude;
private boolean canHover = false;
public double getSpeed() { return
speed; }
private void setSpeed(double s) {
speed = s; }
public double getAltitude() { return
altitude; }
private void setAltitude(double a) {
altitude = a; }
public void hover() {
altitude = 100;
speed = 0;
}
public void fly() {
// etc.
if (canHover) hover();
}
}
After
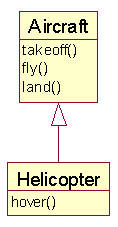
Procedure
Step 1: Introduce a new subclass:
class Helicopter extends Aircraft { }
Step 2: Push helicopter specific methods down into the subclass:
class Helicopter extends Aircraft {
public void hover() {
setAltitude(100);
setSpeed(0);
}
public void fly() {
super.fly();
hover();
}
}
Step 3: Remove methods and fields from super class. It may be necessary to change the scope of some members:
public class Aircraft {
private double speed, altitude;
//protected boolean canHover =
false;
public double getSpeed() { return
speed; }
protected void setSpeed(double s) {
speed = s; }
public double getAltitude() { return
altitude; }
protected void setAltitude(double a)
{ altitude = a; }
public void fly() {
//if (canHover) hover();
}
}
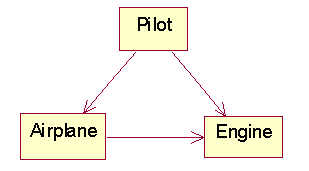
Extract Superclass
Problem
Two classes have similar features. This is a form of code duplication.
Before
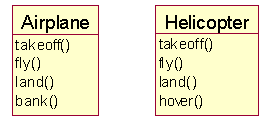
class Helicopter {
private double speed, altitude;
public void takeoff() { }
public void fly() { }
public void land() { }
public void hover() { }
}
class Airplane {
private double _speed, _altitude;
public void takeoff() { }
public void fly() { }
public void land() { }
public void bank() { }
}
After
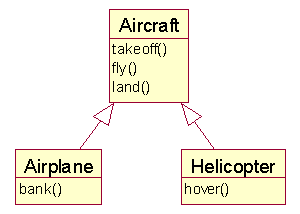
Procedure
Step 1: Introduce a new abstract superclass:
abstract class Aircraft { }
Step 2: Use Pull Up Field to move common fields to the new superclass. Be sure the fields are used in the same way. This might also require renaming some of the fields:
abstract class Aircraft {
protected double speed, altitude;
}
class Helicopter extends Aircraft {
public void takeoff() { }
public void fly() { }
public void land() { }
public void hover() { }
}
class Airplane extends Aircraft {
public void takeoff() { }
public void fly() { }
public void land() { }
public void bank() { }
}
Step 3: Pull up each method. This may require changing the signature of some methods:
abstract class Aircraft {
protected double speed, altitude;
public void takeoff() { }
public void fly() { }
public void land() { }
}
class Helicopter extends Aircraft {
public void hover() { }
}
class Airplane extends Aircraft {
public void bank() { }
}
Step 4: Common tasks performed inside bank() and hover() can be extracted into methods that get pulled up to the superclass.
Extract Class
Problem
A class has too many responsibilities.
Before

After

Procedure
Inline Class
Problem
A class has too few responsibilities.
Before

After

Method
Replace Type Tags
Problem
Behavior is determined by a type tag. This can lead to complex and ubiquitous multi-way conditionals that perform type tag dispatches.
Before

class Aircraft {
public static final void AIRPLANE = 0;
public static final void HELICOPTER =
1;
public static final void BLIMP = 2;
private int type;
public void fly() {
switch(type) {
case AIRPLANE: flyAirplane();
break;
case HELICOPTER: flyHelicopter();
break;
case BLIMP: flyBlimp(); break;
default: defaultFly();
}
}
// etc.
}
After
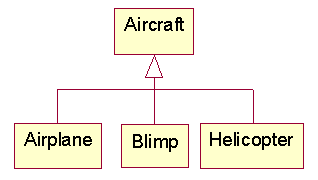
Procedure
Step 1: For each value of the type tag introduce a subclass that overrides any methods containing dispatches.
class Airplane extends Aircraft {
public void fly() { flyAirplane(); }
// etc.
}
Step 2: Replace body of original methods by default code or else make them abstract:
class Aircraft {
public static final void AIRPLANE = 0;
public static final void HELICOPTER =
1;
public static final void BLIMP = 2;
private int type;
public void fly() { defaultFly();
}
// etc.
}
Step 3: Remove type tags:
class Aircraft {
public void fly() { defaultFly(); }
// etc.
}
See Replace Constructor with Factory Method.
Collapse Hierarchy (Introduce Type Tags)
Problem
A superclass and a subclass are not very different.
Before
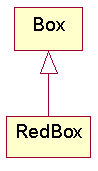
After

Procedure
Step 1: Choose which class to eliminate.
Step 2: Iteratively apply Pull Up Method/Field or Push Down Method/Field.
Delegation
Replace Inheritance by Delegation
Problem
A subclass only uses part of what it inherits from a superclass. Alternatively, objects need to dynamically alter the implementation of their superclass.
Before

class Fleet extends Vector {
public void add(Aircraft a) { if
(good(a)) super.add(a); }
// etc.
}
After

Procedure
Step 1: Add a field that references the superclass.
class Fleet extends Vector {
private Vector members = new
Vector();
// etc.
}
Step 2: Qualify all internal calls to inherited methods by this reference.
class Fleet extends Vector {
private Vector members = new Vector();
public void add(Aircraft a) { if
(good(a)) members.add(a); }
// etc.
}
Step 3: Add methods to replace external calls to inherited methods. For example, assume Fleet doesn't override the inherited isEmpty method, but the inherited isEmpty method is called through Fleet objects by external clients:
class Fleet extends Vector {
private Vector members = new Vector();
public void add(Aircraft a) { if
(good(a)) members.add(a); }
public boolean isEmpty() {
return members.isEmpty(); }
// etc.
}
Step 4: Remove superclass declaration.
class Fleet {
private Vector members = new Vector();
public void add(Aircraft a) { if
(good(a)) members.add(a); }
public boolean isEmpty() { return members.isEmpty();
}
// etc.
}
Replace Delegation by Inheritance
Problem
Too many delegation operations must be performed.
Before

After

Procedure
Step 1: Make the delegate class the superclass.
Step 2: Remove qualifiers from calls to delegate methods.
Step 3: Remove delegate reference.
Replace a Bi-directional Association by a Unidirectional Association
Problem
Bidirectional associations add to the complexity of a program.
Before

After

Procedure
Removing the Customer pointer field from Account is similar to moving a field from a source class to a target class, only in this case the field is being eliminated altogether.
Replace a Unidirectional Association by a Bi-directional Association
Problem
A back link is required.
Before

// Account.h
class Account { ... };
// Customer.h
#include "Account.h"
class Customer {
Account* account;
public:
void setAccount(Account* acct) {
delete account;
account = acct;
}
// etc.
};
After:

Procedure
Step 1: Add a field for the back pointer:
class Account {
Customer* customer;
// etc.
};
Step 2: Decide which class will control the association. In some cases this choice is arbitrary. In other cases the choice is dictated by application logic. Collections and assemblies are usually controllers. In our example we choose Customer as the controller.
Step 3: Add a helper function to the non-controller class. The helper function sets the back pointer:
class Account {
Customer* customer;
public:
void helper(Customer* cust) {
customer = cust;
}
// etc.
};
Step 4: Modify the setter on the controller side so that it calls the helper:
class Customer {
Account* account;
public:
void setAccount(Account* acct) {
acct.helper(this);
delete account;
account = acct;
}
// etc.
};
Other Issues:
Resolving new file dependencies
In C++ we have added a new dependency from Account.h to Customer.h. We can't resolve this dependency with an include directive. We can add a forward reference to Account.h:
// Account.h
class Customer;
class Account {
Customer* customer;
public:
void helper(Customer* cust) {
customer = cust;
}
// etc.
};
This trick works as long as Account.h makes no assumptions about the Customer class. For example, if the helper function needed to call a customer method:
void helper(Customer*
cust) {
if (cust->important()) customer =
cust;
}
then this implementation must be moved to Account.cpp, which must now include Customer.h:
// Account.cpp
#include "Customer.h"
void Account::helper(Customer* cust) {
if (cust->important()) customer =
cust;
}
Preventing users from calling the helper function
By choosing a suitably obscure name for the helper function, we may not need to worry much about this problem. There are some techniques to guarantee that users won't call the helper function.
In C++ we can always make the helper function private, but grant access to the Customer class using a friend declaration:
class Account {
friend class Customer;
Customer* customer;
void helper(Customer* cust) {
customer = cust;
}
// etc.
};
In Java, we can declare the helper function to have package scope, while the setter in the controller has public scope.
We can go one step further in Java by declaring Account to be a public interface:
public interface Account {
void deposit(double amt);
void withdraw(double amt);
Customer getCustomer();
// etc.
}
The Account interface is implemented by a private inner class of the Customer. A factory method creates the accounts:
public class Customer {
private Set accounts = new Hashset();
private class AccountImpl implements
Account {
Customer getCustomer() { return
Customer.this; }
// etc.
}
public Account makeAccount() {
Account acct = this.new
AccountImpl();
accounts.add(acct);
return acct;
}
// etc.
}
Dealing with helper errors
If errors are possible, then the helper function should throw an exception:
void helper(Customer*
cust) {
if (!valid()) throw
InvalidAccountError();
customer = cust;
}
Recall that the helper function was called before the customer's account pointer was set:
void setAccount(Account*
acct) {
acct.helper(this);
delete account;
account = acct;
}
Thus, if the helper throws an exception, setAccount implicitly throws an exception before any customer fields have been modified.
Dealing with collections
In practice, a customer may have many accounts. In this case the customer is equipped with a collection of some sort:
class Customer {
set<Account*> accounts;
public:
void add(Account* acct) {
acct.helper(this);
accounts.insert(acct);
}
void remove(Account* acct) {
accounts.erase(acct);
delete acct;
}
// etc.
};
Using Canonical Form
In C++ the delegator is called the handle and the delegate is called the body. Following the Canonical Form pattern, it is common practice for the handle to manage the body. This means redefining the handle's assignment operator and the copy constructor so that copying the handle also copies the body. It also means providing the handle with a destructor so that deleting the handle also deletes the body. Thus, the C++ implementation of Customer might look like this:
class Customer {
Account* account;
public:
Customer(Customer& cust) {
account = new Account(cust.account);
}
~Customer() { delete account; }
Customer& operator=(Customer&
cust) {
delete account;
account = new Account(cust.account);
return *this;
}
// etc.
};
We are probably adding a back pointer because there is a way to reach an account object other than through a customer object, otherwise we would always know the customer and therefore wouldn't need a back pointer. This means there will be other pointers to an account. If deleting a customer deletes the associated account, then these pointers could become dangling references. In this situation we might want to apply the counted pointer idiom.
Hide Delegation
Problem
Before
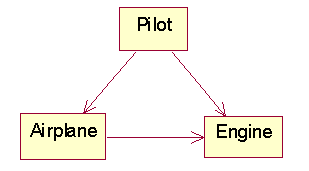
After
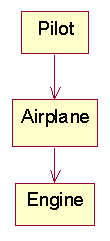
Eliminating the Middleman
Problem
Before
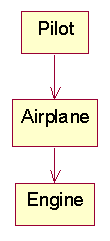
After
Reference versus Value Objects
The identity of a value object is determined by its fields. Two value objects are the same if and only if their fields are the same. Value objects should be immutable. Dates, numbers, and quantities are examples of value objects. It doesn't matter if a program contains multiple value objects that are the same.
The identity of a reference object is determined by what it represents. Two reference objects are the same if they both represent the same thing. Entities, events, and types are examples of reference objects. Having multiple objects in a program that represent the same thing can lead to synchronization problems and confusion.
Replace Values by References
Problem
We want to convert a composite into an aggregation. In other words, we want to change a value object container into a reference container.
Before
Customer objects are value objects in the sense that two customer objects represent the same real world customer if and only if their name fields match:
class Customer {
private String name;
public String getName() { return name;
}
public Customer(String name) {
this.name = name; }
public boolean equals(Object
other) {
if (other == null) return false;
if (other.getClass() !=
this.getClass()) return false;
Customer cust = (Customer)other;
return name.equals(cust.getName());
}
// etc.
}
An order contains a customer by value:

public class Order {
private Customer customer;
public Customer getCustomer() { return
customer; }
public Order(String customerName) {
customer = new
Customer(customerName);
}
// etc.
}
Determining if a particular customer placed a particular order is awkward and inefficient:
if (customer.equals(order.getCustomer())) { ... }
After

Procedure
The basic idea is to keep all customers in a table indexed by customer names. Each place where a customer is constructed is replaced by a factory method that first searches the table to determine if the customer object already exists.
Step 1: Replace the constructor of the value class by a factory method:
class Customer {
private String name;
public String getName() { return name;
}
public static Customer
makeCustomer(String name) {
return new Customer(name);
}
private Customer(String name) {
this.name = name; }
public boolean equals(Object other) {
if (other == null) return false;
if (other.getClass() !=
this.getClass()) return false;
Customer cust = (Customer)other;
return name.equals(cust.getName());
}
// etc.
}
public class Order {
private Customer customer;
public Customer getCustomer() { return
customer; }
public Order(String customerName) {
customer = Customer.makeCustomer(customerName);
}
// etc.
}
Step 2: Alter the factory method to return a reference:
class Customer {
private String name;
public String getName() { return name;
}
private static Map registry = new
Hashtable();
public static Customer
makeCustomer(String name) {
Customer cust = (Customer)
registry.get(name);
if (cust == null) {
cust = new Customer(name);
registry.put(name, cust);
}
return cust;
}
private Customer(String name) {
this.name = name;
}
// etc.
}
We may want to add a new Order constructor:
public Order(Customer
customer) {
this.customer = customer;
}
Value and Reference Objects in C++
The situation is simpler in C++ is conceptually simpler, where we replace value objects by pointers:
Before:
class Order {
Customer customer;
public:
Customer getCustomer() { return
customer; }
// etc.
};
After:
class Order {
Customer* customer;
public:
Customer* getCustomer() { return
customer; }
// etc.
};
Syntactically this can be a headache because we have changed the type of the field.
Replace References by Values
Problem
Immutable objects don't really need to be references.
Before

The center of a circle is a point:
class Circle {
Point center;
double radius;
// etc.
}
A point is completely determined by its x and y coordinates, which can't be changed:
class Point {
double xc, yc;
public String toString() {
return "(" + xc + ",
" + yc + ")";
}
// etc.
}
After

Procedure
We override the inherited equality, which simply tests for literal equality, with a version that tests for logical equality. To make hash tables work properly, we must also replace the inherited hash code function with one that guarantees logically distinct points will have different hash codes:
class Point {
private double xc, yc;
public String toString() {
return "(" + xc + ",
" + yc + ")";
}
public boolean equals(Object other)
{
if (other == null) return false;
if (other.getClass() != getClass())
return false;
Point p = (Point)other;
return p.xc == xc && p.yc ==
yc;
}
public int hashCode() {
return toString().hashCode();
}
// etc.
}