Testing Overview
System and Error Views
There are four important system views: functional, static structural, dynamic structural, and deployment. The functional view refers to the externally observable input/output behavior of the system. Use case diagrams capture the functional view. The static structure of a system corresponds to its internal design and implementation. Class diagrams, object diagrams, flow charts, source code, and dependency graphs capture the static structural view. The dynamic structural view corresponds to the internal state changes and message exchanges that occur while the program is running. We can see the dynamic structure of the system when we use a debugger to step through the execution line by line. State machines, debuggers, and sequence diagrams capture the dynamic structural view. The deployment view assigns system components to network nodes and the communication protocols used by the components. Deployment diagrams capture the deployment view.
Similarly, there are three views of a "problem". A failure is the functional view of a problem, an error is the dynamic structure view, and a fault is the static structure view.
Terminology
A failure is any difference between the expected behavior of a system and its actual behavior. Failures are seen from the functional view. An error is any difference between the expected state of a system and its actual state. A fault or bug is a location in the source code that causes a failure.
For example, an algorithm computes the average of five numbers: 10, 11, 12, 13, and 14. It produces the answer 10. This is a failure. The correct answer should have been 12. Internally, the algorithm sums the five numbers, then divides the sum by five:
result = sum/5
At this point the value stored in sum (i.e., the state of the sum variable) is 50. This is an error. The sum should have been 60. This is not a failure, because we can't observe that sum has the wrong value. Sum is internal to the algorithm. We can only observe that the wrong answer was produced. Upon closer inspection we discover that when 14 was added to sum:
sum = sum + 14 = 46 + 14 = 50
we forgot to carry the one. This is a fault.
Here's another example: a tax calculator computes the wrong tax in some cases. This is a failure. This happens because internally the tax calculator is using the wrong tax table in these cases. This is an error. When we examine the code, we see that the calculator re-initialization method has neglected to re-initialize the tax table pointer. This is a fault.
Reliability is a measurement of the number of expected failures in a fixed period of constant operation. Fault tolerance means designing a system that can recover from faults (e.g. the Tandem computer had dual processors for this purpose), fault avoidance refers to development strategies aimed at reducing the number of faults produced, and fault detection refers to strategies for systematically locating faults. We take this to be our definition of testing.
It is useful to distinguish between functional and structural testing. Functional testing compares the observed behavior of a module with its specified behavior. This might be done by comparing the outputs produced by a module against a list of expected outputs (called an oracle). Functional testing looks for failures while structural testing looks for faults. This might be done by a code review (inspection or walkthrough) or by a formal verification proof. (In one study 85% of the faults in a system were found by code reviews while only 15% were found by functional testing.)
Modularity (review)
The Modularity Principle states:
A program should be decomposed into a network of cohesive, loosely coupled modules.
For our purposes a module might be a method, a class, a package, or a subsystem (which is probably implemented as a package).
The basic relationship between modules is dependency: module M1 depends on module M2 if M1 explicitly uses M2 or if M1 implicitly uses M2. M1 implicitly uses M2, if M1 uses a module M that depends on M2. (In other words, dependency is a transitive relationship.) In either case we call M1 the client module and M2 the provider module. We can represent the statement "M1 depends on M2" graphically as follows:
![]()
Of course the roles of client and provider are constantly shifting. It might also be the case that M2 depends on M1. In this case we can draw a bi-directional dependency arrow between M1 and M2:
![]()
We can view all of a program's modules and dependencies as a network called a dependency graph:
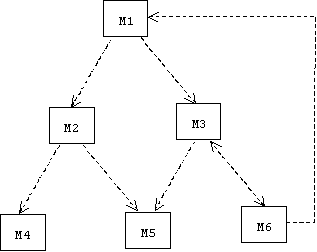
In this diagram implicit dependencies are not shown. For example, M1 depends on M2, and M2 depends on M4, hence there is an implicit dependency from M1 to M4, which may be inferred from the diagram, but is not represented by a dashed arrow.
Ideally, the topology of a dependency graph should be as simple as possible e.g., (trees and stars). More complex topologies (e.g., containing lots of cycles) can make a program harder to test, understand, and maintain.
Testing Plan
A testing plan is a tree of (functional) tests, one for each module. Each test simply produces PASS or FAIL as its result. The root of the tree tests the top-most module in the system. A test for a particular module first verifies that the modules it depends on pass their associated tests. Thus, we can quickly test the entire system by running the root test.
In this diagram Ti is the test associated with module Mi:
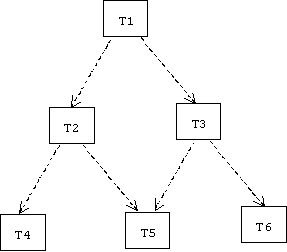
Of course we need to worry about bi-directional dependencies and possible infinite loops. Module M6 depends on module M3 and M1, but test T6 cannot run T1 and T3. In cases like this T6 might employ stubs that mimic the expected behavior of M3 and M1.
Tests
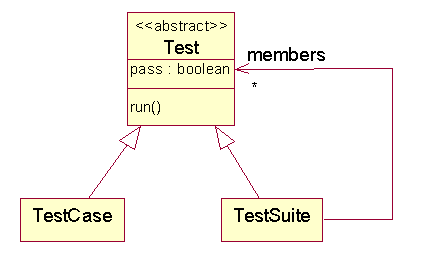
A test of a single method (the leaves of our dependency graph) is called a test case. A test that runs other tests is called a test suite. A test is either a test case or a test suite. We can use the composite diagram to model the situation:
More Terminology
Testing a class is called unit testing. Testing a subsystem-- verifying that all of the classes are properly integrated-- is called integration testing. (The term Structural Testing is sometimes used to refer to integration testing of the top-level module in a system.) Testing the entire system-- verifying that all requirements have been met-- is called system testing. Acceptance testing is done by the client after an initial Beta version of the system has been delivered.
Other Types of Testing
The goal of every program is to be useful (solve the right problems), usable (easy to use), and modifiable (easy to maintain). "Usefulness testing" is just system testing: does the system solve the right problem. Usability testing studies samples of model users and measures how quickly they can learn to perform certain tasks using the system. (Performance testing might fall somewhere between usefulness and usability testing depending on how critical performance is.) We might define modifiability testing as a way of describing the activity of inspecting code not for faults but for anti-patterns or kluges-- i.e., design flaws that might make the code difficult to modify.