7. Reflection and Persistence
Overview
Often an object oriented application maintains a model of its application domain. For example, an inventory control program might maintain a model of a warehouse with aisles and bins. In addition to the application domain, a reflective application maintains a model of itself. This allows users to query the application about design decisions, and in some cases negotiate changes in the design while the program is running.
The first half of this chapter introduces reflective systems by surveying reflection in Java, MFC, and C++. Unfortunately, reflection in C++ is inadequate for our purposes. To compensate, we introduce the Prototype Pattern, which allows programmers to instantiate classes at runtime. This is useful when the identity of the class is unknown at compile time.
After a brief survey of database systems, the second half of the chapter builds a framework for writing and reading objects to files. This is a major application of the Prototype Pattern. The framework is used in subsequent chapters.
Reflective Modules
Recall the abstraction principle from Chapter One:
The implementation of a module should be independent of its interface.
Next to modularity, abstraction is probably the most important principle in engineering. A module that hides its implementation from clients is called a black box module, because it's like an impermeable black box with lights and buttons on the outside, but offering no clues about the wires and chips inside. Everyone knows that black box modules are easier to use and easier to replace. But if this is true, then why did a group of heretics at Xerox PARC question abstraction? (See [WWW 2], [WWW 3], [WWW 4], and [WWW 11].)
The implementer of a module is usually faced with several possible implementations. He must choose which implementation to map the interface onto. This is called a mapping dilemma. For example, how will we implement a function that must sort text files:
void sort(string fileName) { ??? }
Heap sort? Quick Sort? Insertion Sort? The implementer will probably choose an implementation that will give his clients the best average performance. This is called a mapping decision. For example, we would probably choose quick sort because it has the best average behavior. However, the choice of implementation may impose performance penalties on the occasional application that isn't average. This is called a mapping conflict. For example, heap sort might be better suited for an application that must sort large files. Now the client must either introduce awkward workarounds into his code, or build his own supporting module.
Unlike a black box module, a reflective module (sometimes called a glass box module) reduces mapping conflicts by allowing clients to inspect and alter some aspects of its implementation.
Reflective Systems
A reflective or open implementation (OI) system has two levels, a base level and a meta level. Base-level objects provide application services through the system's normal user interface, while meta-level objects describe policies, structures, and strategies used by base-level objects to implement these services:
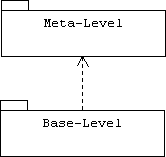
Meta level classes are called meta classes. Instances of meta classes are called meta objects. Instances of a base-level class, A, will often be linked to a single instance of a meta class, MetaA, which encapsulates a description of A. Before responding to a message, an instance of A will first consult its associated meta object for instructions:
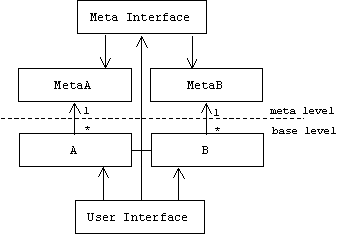
A meta interface or meta object protocol (MOP) allows clients— users and base-level objects —to access meta objects. Through the meta interface a client can inspect, modify, or replace a meta objects, thus dynamically changing the behavior of the associated base-level objects.
Applications of Reflective Systems
Strategies
The Strategy Pattern introduced in Chapter 4 provides a small scale example of reflection. In this pattern the Context class belongs to the base level, while the associated Strategy class belongs to the meta level:
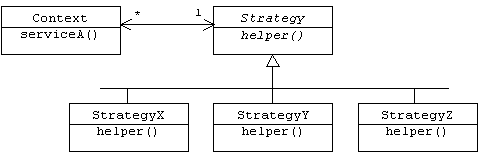
Changing the strategy used by an instance of the Context class, for example, changing the layout manager used by a frame, changes some aspect of the object's behavior.
Reflection in UML
Sometimes it's better to represent application domain types as objects rather than classes. For example, a quantity is a number together with a unit: 5 kilometers, 3.50 US dollars, -20 degrees Fahrenheit, etc. We can think of a unit like US dollars as a type of number. Normally, types are represented by classes in an object oriented model:
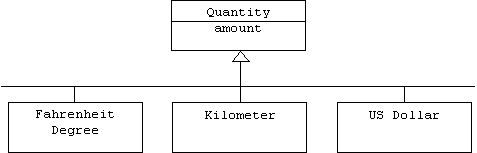
Unfortunately, a class hierarchy such as this one will never be complete. We will always be encountering new units. Adding these units to the hierarchy will involve changing the class diagram, adding new class declarations, and recompiling. Of course most programmers probably won't want a large cumbersome hierarchy that includes units they will never use, while others will complain that we've excluded exactly the units they need.
As an alternative, we can represent units as objects rather than classes:
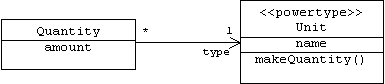
Now units such as Kilometer, US Dollar, and Fahrenheit Degree become instances of the Unit class. Adding new units is simply a matter of creating new instances of the Unit class, which can be done dynamically. Often Unit objects are factories that manufacture appropriately types quantities as products. (This prevents users from creating mistyped quantities.) As an added benefit, a Quantity object can answer the question: What is your unit? This is a primitive example of runtime type identification, which will be discussed later.
Unit is an example of a meta class, because we can regard a Unit object as a description of the Quantity objects linked to it. UML provides a <<metaclass>> stereotype for meta classes. In the case where instances of a meta class represent subtypes of a particular type, then it is more appropriate to use the <<powertype>> stereotype.
Reflective Interpreters
An interpreter is a virtual machine that can execute programs without translating them into native machine code. The base level of a reflective interpreter consists of components needed to execute programs, such as a symbol table, an expression evaluator, a statement executor, a memory manager, and a control loop. Meta level components dictate semantic rules for the programming language such as parameter passing rules, scope rules, type equivalency rules, etc. By changing these meta level components, programmers can tailor the semantics of the programming language to suit a particular application.
Reflective Operating Systems
A reflective operating system separates mechanisms (base level) from policies (meta level). For example, process swapping is a mechanism, but process scheduling: round robin, shortest job first, highest priority first, etc. is a policy that determines which processes to swap. Page replacement is a mechanism, but choosing the page to replace: least recently used, least frequently used, oldest, etc. is a policy. In a sense, all operating systems share the same basic mechanisms, but the "personality" of an operating system— for example the difference between Unix, MacOS, OS2, and Windows NT— is determined by the policies it uses. By allowing users to examine and change policies, we allow users to change the personality of their operating system.
This is similar to the idea behind the Microkernel Architecture used by Windows NT. Basic mechanisms are encapsulated in the microkernel, while policies are encapsulated in internal servers. The original idea was that Windows NT users could run Unix and OS2 applications simply by changing internal servers.
Meta Programming
Objects that represent programming elements such as statements, variables, functions, and types are common meta-objects that are found in meta-programs: programs that manipulate other programs as data. Compilers, interpreters, debuggers, and optimizers are common examples of meta-programs.
Meta objects are also used in component-based programs. Recall that a component is an object known to its clients only through the interfaces it implements. Also recall that a client may not know which interfaces a component implements until runtime. Therefore, it is important that a component provides some standard way for clients to learn about these interfaces. We saw that ActiveX controls provide this by implementing the IUnknown interface. Java Beans— the Java notion of a component— don't need to implement a special interface because a Java Bean is a Java object, and every Java object is automatically associated with a number of meta objects that describe it. In fact, reflection in Java is so well developed, we can get a good picture of reflection in general by surveying its implementation in Java.
Reflection in Java
All Java classes are subclasses of a pre-defined base class called Object. It doesn't matter if a programmer declares this or not. All Java classes are automatically subclasses of the Object base class. (Except for the Object class itself, obviously.) One advantage of this scheme is that it allows Java programmers to create generic methods and classes. This eliminates the need for templates. For example, here is how a Java programmer might declare a generic stack container. Notice that we avoid difficulties over the type of items stored in a stack by generically referring to all of them as Objects:
public class Stack {
private final int MAX = 200;
private int top = 0;
private Object[] stack = new
Object[MAX];
public void push(Object obj) throws
StackError {
if (MAX <= top) throw new
StackError("stack full");
stack[top++] = obj;
}
public Object pop() throws
StackError {
if (top <= 0) throw new
StackError("stack empty");
return stack[--top];
}
// etc.
}
Another advantage of this scheme is that any features placed in the Object base class are automatically inherited by all present and future Java classes. So what sort of features are contained in the Object base class? Currently, the Object base class includes methods that allow any object to duplicate itself (clone), convert itself into a string (toString), compare itself with another object (equals), wait for an event to occur (wait), be notified that an event has occurred (notify), and to answer the questions, "What is your identification number?" (hashCode) and "What class are you an instance of?" (getClass):
public class Object {
protected Object clone() { ... }
public boolean equals(Object obj) { ...
}
public String toString() { ... }
public void notify() { ... }
public void wait() { ... }
public int hashCode() { ... }
public Class getClass() { ... }
// etc.
}
This last feature is interesting. What sort of answer do we expect when we ask an object what class it instantiates? We expect a class, of course. But only objects, not classes, exist at runtime. How can an object return a class in response to this query? The solution is that instead of returning a class, it returns an object representing a class. At first this notion sounds strange. How can objects represent classes? But of course objects represent all sorts of things: cars, houses, boats, people, cats, planets. Why not classes?
The class of all objects that represent classes is defined in the java.lang package. Naturally, the name of this class is Class. It includes methods for discovering the name of the class (getName), the super class (getSuperClass), the methods (getMethods), and the attributes (getFields):
class Class {
public static Class forName(String
name) { ... }
public Object newInstance() { ... }
public String getName() { ... }
public Class getSuperClass() { ... }
public Field getField(String name) {
... }
public Field[] getFields() { ... }
public Method getMethod(String name) {
... }
public Method[] getMethods() { ... }
// etc.
}
Of course this implies that there are also objects representing methods and fields. Naturally, these objects belong to the Method and Field classes, respectively, and of course like all Java classes, Class, Method, and Field are subclasses of the Object base class:
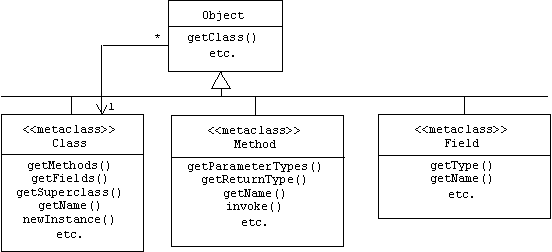
Runtime Type Information (RTTI) in Java
To demonstrate reflection in Java, we introduce a hierarchy of classes that represent different types of musical notes:
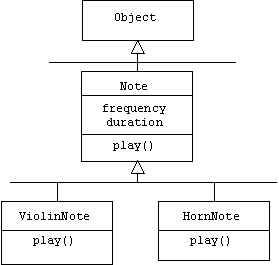
The Note class declares two public integer fields representing the duration and frequency of a note. It also declares a play() method that simply prints a message in the console window, as well as a static method called main(), where we can place our test code:
public class Note {
public int frequency = 60; // frequency of note in Hz
public int duration = 300; // duration of note in millisecs
public void play() {
System.out.println("Playing a
generic note");
}
public static void main(String[] args)
{
// test code goes here
}
}
HornNote and ViolinNote are subclasses of Note that override the inherited play() method:
class HornNote extends Note {
public void play() {
System.out.println("Playing a
horn note");
}
}
class ViolinNote extends Note {
public void play() {
System.out.println("Playing a
violin note");
}
}
Our test driver, Note.main(), begins by declaring a reference to a note:
Note note;
Unlike C++, no object is created by this declaration. Instead, note is simply a variable capable of holding a reference to any object that instantiates the Note class or any of its subclasses. Java objects are created by the new operator, which creates an object on the heap, then returns a reference to it. The following statement creates a HornNote object, then places a reference to this object in the note variable:
note = new HornNote();
Next, we ask note which class it instantiates, then print the name of this class:
Class c = note.getClass();
System.out.println("class of note = " + c.getName());
Here is the output produced:
class of note = HornNote
Notice that Java wasn't fooled by the fact that note was declared as a Note reference. Instead, it dug deeper, returning the class of the object note currently references. To make this point clearer, we reassign note so that it references a ViolinNote, reassign c so that once again refers to the class of note, then print the class name:
note = new ViolinNote();
c = note.getClass();
System.out.println("now class of note = " + c.getName());
Now here's the output produced:
now class of note = ViolinNote
Again notice that getClass() actually fetches the class of the object, not simply the class of the reference.
Of course we can reassign c to reference any super class of ViolinNote:
c = c.getSuperclass();
System.out.println("base class of note = " + c.getName());
c = c.getSuperclass();
System.out.println("base of base class of note = " + c.getName());
Here is the output produced:
base class of note = Note
base of base class of note = java.lang.Object
Introspection in Java
In addition to information about super classes, we can also find out about the methods and fields of a class. Assuming c still references an object representing the ViolinNote class, then the following loop prints out the names of all of the ViolinClass methods:
Method methods[] = c.getMethods();
for(int i = 0; i < methods.length; i++)
System.out.println(methods[i].getName());
Here's the output produced:
main
hashCode
wait
wait
wait
getClass
equals
toString
notify
notifyAll
play
Notice that in addition to play(), all methods inherited from the Note and Object super classes are also listed. (The wait() method inherited from the Object super class appears three times because there are actually three different methods with this name.) Of course we could have printed out much more than the names of the methods. For example, we could have printed the parameter lists, the exception lists, and the return types.
The following code prints the names of the ViolinNote fields as well as their current values in the particular ViolinNote object referenced by note:
Field fields[] = c.getFields();
try {
for(int i = 0; i < fields.length;
i++) {
System.out.print(fields[i].getName()
+ " = ");
System.out.println(fields[i].getInt(note));
}
} catch(Exception e) {
// handle e
}
Here is the output produced:
frequency = 60
duration = 300
Non-public fields aren't printed.
Invoking Method Objects
Surprisingly, we can ask a Method object to invoke the method it represents. Of course we must provide it with the implicit and explicit arguments. For example, let's create a generic Note object, then call its play() method using reflection:
note = new Note();
c = note.getClass();
Method meth = c.getMethod("play", null);
meth.invoke(note, null);
Here's the output produced:
Playing a generic note
We repeat the experiment using a HornNote:
note = new HornNote();
c = note.getClass();
meth = c.getMethod("play", null);
meth.invoke(note, null);
Here's the output produced:
Playing a horn note
Notice that the HornNote play() method was invoked instead of the Note play() method.
Finally, we repeat the experiment one last time using a ViolinNote:
note = new ViolinNote();
c = note.getClass();
meth = c.getMethod("play", null);
meth.invoke(note, null);
Here's the output produced:
Playing a violin note
Of course it's far more efficient to simply call the play() method directly:
note.play();
Reflection is useful in those situations where we don't know which method we want to call at the time we are writing our program. Instead, this information will only be available at runtime.
Dynamic Instantiation in Java
Sometimes we don't even know the type of object we want to create until our program is running. We saw examples of this problem when we introduced the Factory Method Pattern in Chapter 3. In Java, we can create an instance of a class, C, from a Class object representing C using the newInstance() method. To make things harder, we will assume nothing is known about C at compile time. This might be the case if we were trying to define a universal instrument class. A universal instrument can imitate all other types of instruments. This is done with a play() method that expects as its input only the name of the type of note to play:
class UniversalInstrument {
public void play(String noteType) {
try {
Class c = Class.forName(noteType); // find & load a class
Note note = (Note)
c.newInstance();
note.play();
} catch (Exception e) {
// handle e here
}
}
}
Internally, the play() method first converts the name of the class, noteType, into an object representing the class itself, using the static forName() method. For example, if noteType is the string "HornNote", then forName() searches for a file named HornNote.class (this is the conventional name for the file containing the binary definition of the HornNote class), dynamically loads the file into the Java virtual machine, then creates and returns a Class object representing the HornNote class.
From the Class object, c, the newInstance() method is invoked. This creates an instance of the class represented by c. Of course this is returned as an Object, so in our example we perform an explicit downcast to the Note class, then call the play() method.
After creating a universal instrument, our test driver calls the play() method twice. The first time the string "ViolinNote" is the argument. The second time the string "HornNote" is the argument:
UniversalInstrument inst = new UniversalInstrument();
String noteType;
noteType = "ViolinNote";
inst.play(noteType);
noteType = "HornNote";
inst.play(noteType);
Here's the output produced:
Playing a violin note
Playing a horn note
Of course if we wanted to create and play a HornNote followed by a ViolinNote, why not simply do it directly:
note = new HornNote();
note.play();
note = new ViolinNote();
note.play();
To see why, suppose instead of hardwiring the "ViolinNote" and "HornNote" strings into our test program, we allow the user to specify the strings:
System.out.print("enter a type of note: ");
noteType = MyTools.stdin.readLine();
inst.play(noteType);
We don't know what the user will enter, so we don't know what type of notes to make.
Types as Objects
A reflective system consists of two levels: a base level and the meta level:
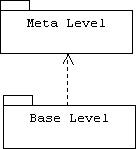
The base level consists of base classes. A base class performs application-specific tasks. Airplane, Customer, Transaction, and Company are examples of typical base classes. Normally, users only interact with the base level of a reflective system. The meta-level consists of meta-classes. An instance of a meta-class describes the implementations and policies used by one or more base classes. By interacting with the meta-level of a reflective system, power users can dynamically inspect and negotiate changes in the implementation and behavior of the base level.
For example, the meta level of a reflective operating system might allow users to inspect and modify page swapping or process scheduling policies. The meta level of a reflective compiler might allow users to inspect and modify parameter passing mechanisms and scope rules.
Runtime Type Identification (RTTI)
Type information is used by compilers to check for inconsistencies in a program before it is translated into machine language. After the translation is performed, the type information is discarded. This is fine for most applications, but in some cases we might not be able to predict the type of data a highly polymorphic function will operate on when it is called. Instead, it will be the job of the function to begin by querying the data about its type. For example, a graphical programming environment such as Visual Basic might be expected to create and manipulate foreign components developed by third-parties in the distant future.
But what sort of answer should an object produce when asked about its class? Objects only exist at runtime, while classes only exist at compile time. Clearly, we need the ability to represent classes as objects. This sounds strange at first. We are familiar with representing application domain objects such as airplanes, customers, and pancakes as objects, but not solution domain objects such as programs, classes, and functions. What class would an object representing the Airplane or Customer class belong to? The answer: the Class class of course!
In UML a class whose members represent classes is called a meta-class. UML even provides a <<metaclass>> stereotype. We take a broader view and define a meta-class to be any class whose instances represent solution domain objects such as functions, variables, classes, statements, or programs. A meta-program is a program that manipulates meta-class objects. Compilers, debuggers, CASE tools, and optimizers are familiar examples of meta-programs.
RTTI in Java
All Java classes—user or system defined –extend the Object base class. In addition, Java provides Class, Method, and Field meta classes. Every Java object inherits from the Object base class a getClass() function that returns a reference to an appropriate Class meta-level object:
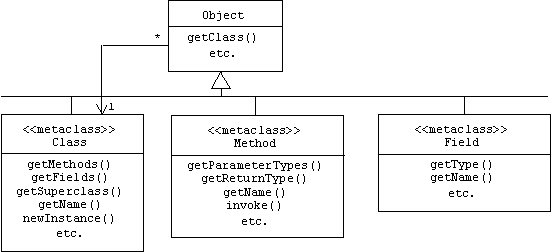
For example, assume the following Java class declarations are made:
class Document { ... }
class Memo extends Document { ... } // Memos are Documents
class Report extends Document { ... } // Reports are Documents
In other words, Memo and Report are specializations of Document:
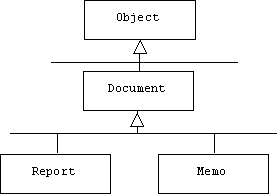
We can think of
Document, Report, and Memo as base classes and Class, Method, and Field as meta
classes.
Assume x is declared as a Document reference variable:
Document x; // x can hold a reference to a document
Then we can assign references to Memo or Report objects to x:
x = new Report(); // x holds a reference to a Report object
x = new Memo(); // now x holds a reference to a Memo object
At some point in time we may be unsure if x refers to a Memo object, a Report object, or perhaps some other special type of Document object (Letter? Contract? Declaration of Independence?) This isn't a problem. Programmers can fetch x's runtime class object by calling the inherited getClass() function:
Class c = x.getClass();
For example, executing
the following Java statements:
Document x = new Report();
Class c = x.getClass();
System.out.println("class of x = " + c.getName());
c = c.getSuperclass();
System.out.println("base class of x = " + c.getName());
c = c.getSuperclass();
System.out.println("base of base class of x = " + c.getName());
x = new Memo();
c = x.getClass();
System.out.println("now class of x = " + c.getName());
produces the output:
class of x = Report
base class of x = Document
base of base class of x = java.lang.Object
now class of x = Memo
Notice that the name of
the Object class is qualified by the name of the package (i.e., the namespace) that it belongs to, java.lang (see
Programming Note A.1.2 in Appendix 1).
Java reflection goes
further by introducing Method and Field meta classes. (In Java member functions
are called methods and member
variables are called fields.) Let's
add some fields and methods to our Document class:
class Document
{
public int wordCount = 0;
public void addWord(String s) {
wordCount++; }
public int getWordCount() { return
wordCount; }
}
Next, we create a
document and add some words to it:
Document x = new
Document();
Class c = x.getClass();
x.addWord("The");
x.addWord("End");
Executing the following
Java statements:
Method methods[] = c.getMethods();
for(int i = 0; i < methods.length; i++)
System.out.println(methods[i].getName()
+ "()");
Field fields[] = c.getFields();
try
{
System.out.print(fields[0].getName() + " = ");
System.out.println(fields[0].getInt(x));
}
catch(Exception e)
{
System.out.println("fields[0] not
an int");
}
produces the output:
getClass
hashCode
equals
toString
notify
notifyAll
wait
wait
wait
addWord
getWordCount
wordCount = 2
Notice that the methods
inherited from the Object base class were included in the array of Document
methods. (There are three overloaded variants of the wait() function in the
Object class.) If wordCount is declared private, as it normally would be, then
its value doesn't appear in the last line:
wordCount =
RTTI in C++
Recently, C++ has added runtime class objects that provide a limited amount of runtime type information (RTTI). Runtime class objects are instances of the type_info class, which is declared in typeinfo.h:
class type_info
{
public:
virtual ~type_info();
int operator==(const type_info&
rhs) const;
int operator!=(const type_info&
rhs) const;
int before(const type_info& rhs)
const;
const char* name() const;
const char* raw_name() const;
private:
...
};
The typeid() operator returns the type of its argument:
Appliance* app = new Refrigerator(...);
type_info rtc = typeid(*app);
cout << rtc.name() << endl; // prints "class
Refrigerator"
RTTI can be used to perform safe down casts and cross casts. Assume ref can hold a pointer to a refrigerator:
Refrigerator* ref;
We would like to assign app, our appliance pointer, to ref, but we are concerned that app might not actually point at a refrigerator object at the time of the assignment. The dynamic_cast() operator uses RTTI to perform safe casts. If app no longer points at a refrigerator object, the null pointer, 0, is returned:
if ( ref = dynamic_cast<Refrigerator*>(app) )
ref->setTemperature(-30);
else
cerr << "invalid
cast\n";
RTTI Compiler Options
You will need to include the <typeinfo> header file to get the declaration of typeid (which is in the std namespace). Also, you may have to specify some compiler options to generate the extra typing information needed by RTTI. In VC++, select the C/C++ tab in the dialog that appears when you select Settings from the Project menu. Pick "C++ Language" in the Category combo box. Check the "Enable Runtime Type Information (RTTI)" box.
The UML Meta Model
Power types
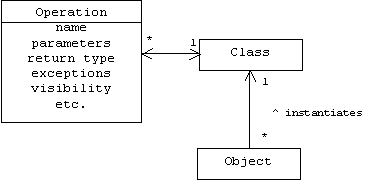
A power type is a special kind of meta class in which instances represent subclasses of a particular class. For example, there are many types of aircraft: airplanes, blimps. helicopters, space ships, etc. We could represent this situation by introducing blimp, helicopter, and airplane as subclasses of an aircraft base class:
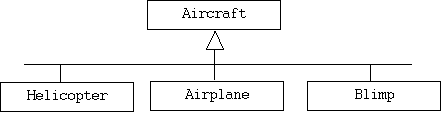
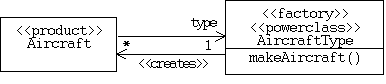
Alternatively, we could define a single Aircraft class and represent the different types of aircraft by different instances of an AircraftType power type. In this case it's common for instances of the power type to act as a factories that create instances of the type of objects they represent, the same way a class would provide a constructor for creating instances. It is also common for products created by a power type object to carry a type pointer back to the factory that created them:
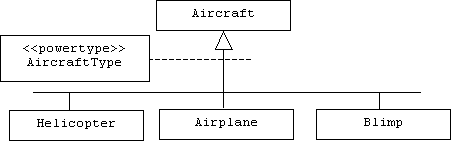
In UML we can also represent a power type with a dashed line connecting it to the hierarchy of subclasses it represents:
Dynamic Instantiation
Instances of power types are often factories and instances of the subclasses represented by a power type instance are the products this factory creates. In C++ we can force clients to create objects by calling power type factory methods by making constructors private and by declaring the power type to be a friend class:
class Aircraft
{
public:
void takeoff() { ... }
void fly() { ... }
void land() { ... }
AircraftType* getType() { return
myType; }
private:
AircraftType* myType; // = blimp,
plane, saucer, etc.
Aircraft() {}
Aircraft(AircraftType* t) { myType = t;
}
Aircraft(const Aircraft& a) {}
friend class AircraftType;
};
class AircraftType
{
public:
AircraftType(string n) { name = n; }
string getName() { return name; }
Aircraft* makeAircraft() { return new
Aircraft(this); }
private:
string name; // = blimp, plane, saucer,
etc.
};
A Java Implementation of a Power Type
How can we insure that users won't bypass the factory and directly create aircraft? This can be done in Java by defining Aircraft to be a private inner class of AircraftType. We begin by introducing an aircraft interface:
interface IAircraft {
public AircraftType getType();
public void takeoff();
public void fly();
public void land();
}
Next, we define the AircraftType class with a private inner class and a factory method:
class AircraftType {
private String name;
public AircraftType(String n) { name =
n; }
public String toString() { return name;
}
// factory method:
public IAircraft makeAircraft() {
return new Aircraft();
}
private class Aircraft implements
IAircraft {
public void takeoff() {
System.out.println("An
aircraft is taking off");
}
public void fly() {
System.out.println("An
aircraft is flying");
}
public void land() {
System.out.println("An
aircraft is landing");
}
public AircraftType getType() {
return AircraftType.this;
}
} // Aircraft
} // AircraftType
Here is how a client might create an aircraft:
public class TheApp {
public static void main(String[] args)
{
AircraftType blimp = new
AircraftType("Blimp");
AircraftType helicopter = new
AircraftType("Helicopter");
//IAircraft a = blimp.new
Aircraft(); // ok if inner class is public
IAircraft a = blimp.makeAircraft();
a.takeoff();
a.fly();
a.land();
System.out.println("a.getType()
= "+ a.getType()); //prints Blimp
}
}
Of course reflection is built into Java, so we can use the Java meta classes Class, Field, Method, etc. without writing extra code. For example, let's drop the getType() function from the IAircraft interface:
interface IAircraft {
// public AircraftType getType();
public void takeoff();
public void fly();
public void land();
}
Assume Helicopter and SpaceShip implement this interface:
class SpaceShip implements IAircraft {
public void takeoff() {
System.out.println("A spaceship
is taking off");
}
public void fly() {
System.out.println("A
spaceship is flying");
}
public void land() {
System.out.println("A
spaceship is landing");
}
}
Here is how a client might build and takeoff in an aircraft without knowing the type of aircraft:
import java.lang.reflect.*;
public class Test {
public static void main(String[] args)
{
try {
String className =
"SpaceShip";
Class c =
Class.forName(className);
IAircraft a =
(IAircraft)c.newInstance();
Method[] meths = c.getMethods();
for(int i = 0; i <
meths.length; i++)
if
(meths[i].getName().equals("takeoff"))
meths[i].invoke(a, null);
}
catch(Exception e) {
System.err.println("error =
" + e);
}
}
}
Advantages and Disadvantages
In these examples we have replaced the static type system provided by C++ (and to a lesser extent Java) with a dynamic type system in which values are type tagged (this is similar to languages like LISP). Of course we loose the advantages of inheritance and polymorphism. Instead, we need to provide our own forms of inheritance and polymorphism. This can be done by providing power type objects with virtual function tables:
class AircraftType
{
public:
typedef void (*Function)(Aircraft*);
void takeoff(Aircraft* a)
{ /* search vft for takeoff and call it
*/ }
void fly(Aircraft* a) { /* search vft
for fly and call it */ }
void land(Aircraft* a) { /* search vft
for land and call it */ }
// etc.
private:
map<string, Function> vft;
};
The Aircraft member functions simply delegate to the corresponding member functions of their associated type object:
class Aircraft
{
public:
void takeoff() {
myType->takeoff(this); }
void fly() { myType->fly(this); }
void land() { myType->land(this); }
AircraftType* getType() { return
myType; }
private:
AircraftType* myType; // = blimp,
plane, saucer, etc.
Aircraft() {}
Aircraft(AircraftType* t) { myType = t;
}
Aircraft(const Aircraft& a) {}
friend class AircraftType;
};
Links as Objects: Association Classes
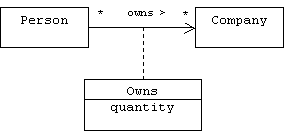
Consider the relationship: "Person P owns shares in company C." We might represent this relationship as a simple association between the Person class and the Company class:
![]()
Now consider the relationship: "Person P owns N shares in company C." Where should the number of shares, N, be recorded? It wouldn't make sense to store this information in the Person class, because a person might own different numbers of shares of different companies. Similarly, it wouldn't make sense to store this information in the Company class, because a company might have many share holders, each owning different numbers of shares.
The number of shares owned is clearly a property of the link between a person and a company. Unfortunately, until now we have been representing links by C++ pointers or Java references, and neither of these can bear attributes. It's time to take a more object-oriented view of links. Instead of pointers or references, we can represent links as objects and associations as classes.
For example, suppose Smith owns 50 shares of IBM. Thus, there is a link between Smith and IBM, which is an instance of the owns association. We can represent this link as an object that instantiates the Owns association class, is linked to both Smith and IBM, and has a quantity attribute with value 50:

Notice that Smith and IBM are no longer directly linked, but are instead linked through the Owns object.
An object representing a link is called a link object. A link object is an instance of an association class. In UML we depict association classes using a class icon connected to an association with a dashed line:
C++ Implementation
class Person
{
set<Owns*> holdings;
// etc.
};
class Company { ... };
class Owns
{
Person* owner;
Company* holding;
int quantity;
void addShares(int quant) { quantity +=
quant; }
// etc.
};
Of course we must take special care to avoid inconsistencies in the C++ implementation. This might be accomplished by making Owns a friend of the Person class. A single public constructor is provided:
Owns::Owns(Person* p, Company* c, int quant)
{
quantity = quant;
holding = c;
owner = p;
(p->holdings).insert(this);
}
Java Implementation
class Person {
private Set holdings = new TreeSet();
public addHolding(Owns h) {
holdings.add(h);
}
// etc.
}
class Company { ... }
class Owns {
private Person owner;
private Company holding;
private int quantity;
public void addShares(int quant) {
quantity += quant; }
public Owns(Person p, Company c, int
quant) {
quantity = quant;
owner = p;
holding = c;
p.addHolding(this);
}
// etc.
}
Reified Associations
Now consider the relationship "Person P purchases N shares of Company C." Again we might represent this relationship as a simple association between the Person class and the Company class. Again we are confronted with the problem of where to store the quantity attribute, N. Clearly, purchases should be represented as instances of a Purchase class with a quantity attribute. In fact, the implementation of the Purchase class would be almost identical to the implementation of the Owns class shown above.
However, the Purchase class is not considered to be an association class. This is because Smith might purchase 20 shares in IBM today and 30 shares tomorrow. Each purchase is an instance of the Purchase class that links Smith and IBM. Of course there will only be a single instance of Owns that links Smith and IBM:
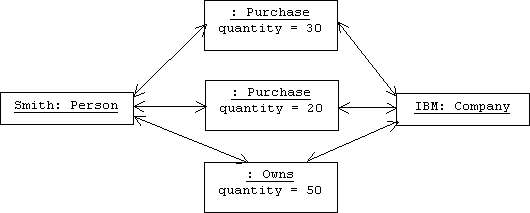
The point is that the identity of a link object is completely determined by the objects it links together, not its attributes. There will only be one instance of the Owns class that links Smith with IBM, while there can be many instances of the Purchase class, each distinguished by the quantity purchased (and perhaps other attributes such as date of purchase and price per share paid).
To put it another way, the owns N shares relationship is a set or links (repeat members disallowed), while the purchases N shares relationship is a bag or multi-set of links (repeat members allowed). This difference might be reflected in the implementation of the Person and Company classes. Here's the C++ version:
class Person
{
set<Owns*> holdings;
multi_set<Purchase*> purchases;
// etc.
};
and here's a possible Java version:
class Person {
private Set holdings = new TreeSet();
priavte List purchases = new Vector();
// etc.
}
No special notation is needed to represent the Purchase class in a class diagram:

Although Purchase isn't an association class, it is an example of a reified class. Reification means objectification: the tendency to view abstractions (such as relationships, events, aggregations, processes, and concepts) as concrete objects. Instances of the Purchase class represent stock purchasing events. The ontological status of a stock purchasing event is a bit more nebulous than a company or a person. A person is a physical object in the real world, a purchasing event is not. (The ontological concreteness of a company is somewhere between the person and event.) Reification is an important modeling tool that is used extensively in science and mathematics. (Quantum mechanics is a good example of reification.)
Instances of a reified class represent abstractions in the application domain. Both the Owns and the Purchase classes are reified classes.
Persistence
Persistent objects can be saved to and restored from files or databases. Transient objects can't be saved or restored. Transient objects simply disappear when the application that created them terminates, if not before. We can extend these ideas to classes in the usual way: a class is persistent if its instances are persistent, and transient if its instances are transient. By default, all C++ and Java classes are transient. Usually, programmers must write extra code to declare persistent classes.
Objects representing important entities or events in an application domain generally need to be persistent. For example, business domain objects such as accounts, invoices, and transactions should be persistent; health care domain objects such as records of patients, treatments, and test results need to be persistent; and engineering domain objects such as part models, reports, and workflows ought to be persistent.
Not all objects need to be persistent, however. For example, it would be a waste of secondary memory to store user interface objects such as windows, control panels, message handlers, and message dispatchers. It's more efficient to create new instances of these objects each time the application restarts. These objects tend to be transient.
Object-Oriented Databases
In an ideal world, persistent objects would be stored in object-oriented databases: databases specifically designed to store objects in a language-neutral format. When, for example, a C++ program references an object stored in such a database, an object fault occurs: the database manager automatically fetches the object, translates it into a C++ object, and loads it into the program's address space. If our C++ program updates this object, then the modified object is automatically translated back into a language-neutral object that replaces the original object in the database. Later, a Java program can reference and update the same object. The sequence of events is identical except this time the translation is between Java and the language-neutral format.
Because the object-oriented database manager automates the movement of objects between databases and programs, the line between primary and secondary memory becomes transparent; programmers no longer need to explicitly save and restore persistent objects. Naturally, the database manager also provides search functions and maintains the consistency of the database by preventing synchronization problems. Object-oriented databases are discussed further in Programming Note 5.12.2.
Relational Databases
In the real world successful object-oriented applications need to be able to save and restore persistent objects using relational databases. Relational databases predate the object-oriented paradigm, which, among other things, means they are far more entrenched in the market place.
Relational databases store tables, not objects. Instances of a class, C, would be stored in a relational database as rows of a table, TC, with columns that correspond to an attributes of C. For example, assume a persistent Student class has been declared as follows:
class Student
{
public:
Student(string ln, string fn, float
avg,
Course* p1, Course* p2,
Course* p3);
// etc.
private:
string lastName, firstName;
float gpa; // grade point average
// current course schedule:
Course *period1, *period2, *period3;
};
Assume three instances of this class have been created and are subsequently saved to the "Student" table in the "School" database:
Student
s1("Anderson",
"Mary", 3.14, &physics2, &math2, &chem2),
s2("Jones", "Mark",
2.9, &physics2, &math1, &chem2),
s3("Smith", "Bob",
3.4, &physics1, &math1, &chem1);
save("School", "Student", s1);
save("School", "Student", s2);
save("School", "Student", s3);
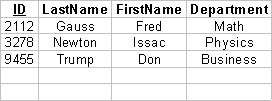
These objects appear as rows in the Student table (TStudent):

The first column of this table holds a unique identification number automatically assigned to each object by the database manager. In a sense, this identification number can be thought of as the object's "address" within the database. (Of course the usual concept of address doesn't make sense in secondary memory.) Instead of storing the pointer to the course a student takes during a given period, which wouldn't make sense either, we store the identification number of a row in the School database's Course table. Relational databases are discussed further in Programming Note 5.12.1.
Unfortunately, translating between objects and rows in a table isn't automatically done by a relational database manager. Programmers must explicitly read and write each field of an object to the database using special library functions provided by the database vendor. This is sometimes referred to as impedance mismatch: the mismatch between data formats commonly used in main memory (e.g., objects) and data formats commonly used in secondary memory (e.g., table rows). It has been estimated that 30% of both implementation time and execution time is devoted to translating between data formats.
Serialization
Assume we must implement persistent objects, but no database is available, neither relational nor object oriented. We could simply require all classes of persistent objects to provide a member function that inserts each member variable into a given file stream[1] (this process is called serialization) and a member function that extracts data from a given file stream and puts it into the corresponding member variable (this process is called deserialization.)
XML
Although we usually think of XML documents as documents, it can be more instructive to think of them as serialized objects. More precisely, we can think of XML elements as objects. Element attributes correspond to object attributes. Namespaces correspond to packages. If each object is equipped with a unique OID attribute, then we can use XPointers to represent links between objects.
One advantage of representing objects as XML documents is that it provides a degree of language transparency. Since XML documents can be self-describing, a Java program can easily read an XML document created by a C++ application, parse it, and turn it into a Java object.
Programming Notes
Persistence in Java
Java provides object output and input streams. Any object that implements Java's Serializable interface can be written to an object output stream and read from an object input stream:
class Address implements Serializable { ... }
class Person implements Serializable { ... }
The amusing thing is that the Serializable interface is empty:
interface Serializable {}
There's nothing for the programmer to implement! Thanks to reflection, once Java knows the class of an object, it can dynamically create an instance of that class. What's more, Java can learn the number and types of member variables the newly created object has. Java can use this information to automatically generate serialize() and deserialize() functions for the class.
Relational Databases
The most common type of databases are relational databases. Conceptually, a relational database is organized into tables or relations. The rows of a table, also called records, represent objects in some application domain class, the columns of a table represent attributes. For example, our school database might consist of three tables representing the classes Student, Teacher, and Course. Assume each student takes exactly three courses per term, and each teacher teaches exactly three courses per term:
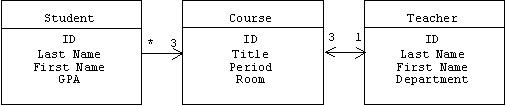
Rows in the student table represent students, columns represent student attributes such as identification number, last name, first name, grade point average, first period course, second period course, third period course, etc. An entry in a given row and column is called an attribute value:

An attribute that is unique for each record is called a candidate key. For identification purposes there must be at least one candidate key for each table. In our example the ID attribute is a candidate key. One candidate key is selected as the primary key. The numbers in the "Period 1", "Period 2", and "Period 3" columns are foreign keys. A foreign key is a candidate key in another table. Foreign keys allow us to express links between records, hence associations between classes. In our example the foreign keys represent the ID numbers of courses in the Courses table:
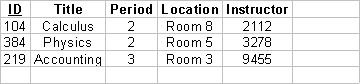
The entries in the Instructor column are foreign keys that represent the ID numbers of teachers in the Teacher table:
SQL
Structured Query Language or SQL is the ISO standard language for defining and manipulating relational databases. The basic data manipulation commands are:
SELECT ... To query data in
a database
INSERT ... To insert rows into a table
UPDATE ... To update rows in a table
DELETE ... To delete rows from a table
Select is the most common command. Its basic format is:
SELECT column, column, ...
FROM table, table, ...
WHERE condition
For example, the query:
"What are the names of all students who have at least a 2.0 grade point averange and who take calculus during first period?"
can be expressed in SQL by:
SELECT LastName, FirstName
FROM Students
WHERE Period1.Title = "Calculus" AND 2.0 <= GPA
The result of executing a select command is a new table created from the tables listed in the FROM clause. The columns of the result table are those listed in the SELECT clause. The rows of the result table are those meeting the condition specified in the WHERE clause. If there is no WHERE clause, then no rows are filtered from the result table.
From the user's perspective, the result table appears to be one of the tables in the database, but in fact, the result table is often not explicitly stored in the database. Tables that are explicitly stored in the database are called base tables. Tables constructed from executing queries are called virtual tables or views. The tables listed in the FROM clause might be base tables or virtual tables.
Interfaces to Relational Databases
Humans normally use browsers with graphical user interfaces to interactively query and update databases. But how do applications query and update databases? For example, how do browsers query and update databases? Many database management systems include an API (Application Programmer Interface). This is a library of functions that perform the most common types of database operations and that can be called from an application. Unfortunately, there is no ISO standard governing these APIs, so a program might need to be altered if the DBMS is changed. Open Database Connectivity (ODBC) is a standard RDBMS API being proposed by Microsoft. To implement ODBC, RDBMS vendors provide a driver in the form of a DLL (Dynamic Link Library) that interfaces with the RDBMS API and interprets ODBC function calls.
Another way DBMS vendor-dependency can be eliminated is by using embedded SQL. Embedded SQL allows programmers to embed SQL statements directly into their source code. Subsequently, a preprocessor replaces them with calls to vendor-specific API functions that directly access the RDBMS.
Object Oriented Databases and ODMG 2.0
The correspondence between records in a relational database and C++ objects is not as close as one would hope. (For example, C++ concepts like pointer, member function, and derived class don't have obvious RDBMS counterparts.) The rows of a table must still be converted into objects, and this can be a lot of work for the programmer and the CPU. In fact, it has been estimated that as much as 30% of programming effort and code space is devoted to converting data from database or file formats into and out of program-internal formats such as objects [ATK]. The gap between database formats and program-internal formats is called impedance mismatch.
In contrast to relational databases, object databases are collections of objects organized into classes that are related by association and specialization. But what type of objects? C++ objects? Java objects? Smalltalk objects? If an object database contains C++ objects, then impedance mismatch is eliminated between the database and C++ client programs, but not between the database and Java or Smalltalk programs. To resolve this problem a consortium of companies has formed the Object Database Management Group[2] (ODMG) to define standards for object oriented database management systems (OODBMS). Version 2 of the standard (ODMG 2.0) appeared in 1997.
ODMG 2.0 includes specifications of an object model[3] (i.e., language-independent definitions of object oriented concepts such as object, class, inheritance, attribute, method, etc.); OQL, the Object Query Language (a language with SQL-like syntax for searching object oriented databases); and language bindings for C++, Java, and Smalltalk. GemStone, Itasca, Objectivity/DB, Object Store, Ontos, O2, PoetT, and Versant are examples of ODMG 2.0-compliant OODBMSs.
Using an object database[4], a C++ (or Java or Smalltalk) program may refer to objects without worrying if they are in main memory or secondary memory. If the requested object is in secondary memory, an object fault occurs, and the OODBMS transparently locates the requested object using the object's unique object identifier number (OID), translates the object into a C++ (or Java or Smalltalk) object, then loads the object into main memory. If the program updates an object (and commits to the update), the procedure is reversed: the ODBMS translates the C++ (or Java or Smalltalk) object into an ODMG object, then writes the translated object back to the database.[5]
Problems
Problem 1
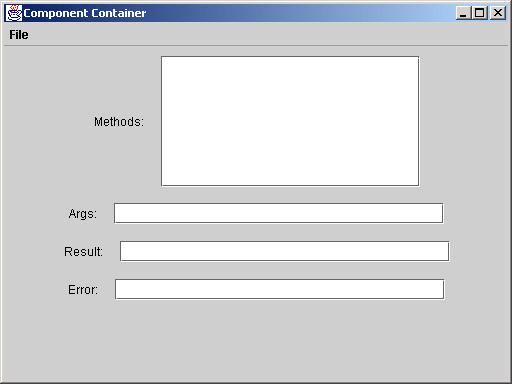
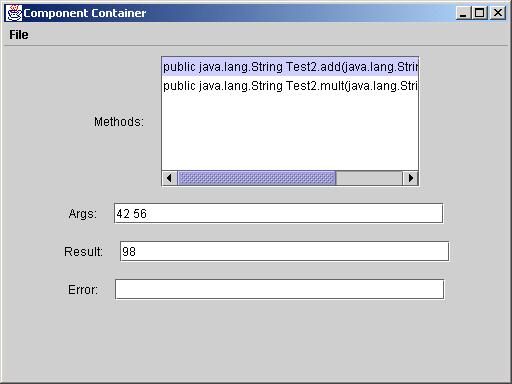
Component Container allows users to discover and execute methods that process strings.
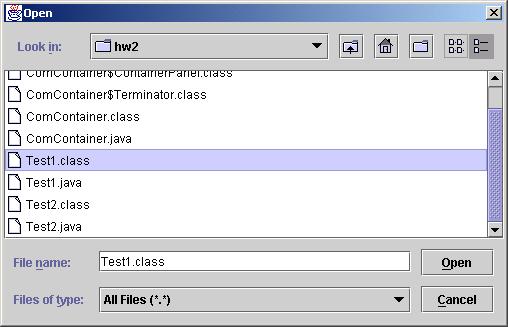
Selecting Open from the File menu displays a file chooser dialog. The dialog should display .class files located in the working directory (unlike mine does):
After selecting a class file, the declared methods of that file are displayed in the method list box. When the user types a sequence of strings in the Args field then selects a method that takes strings as inputs, the Component Container instantiates the class, then invokes the selected method on the specified arguments. The return value is displayed in the Return field.
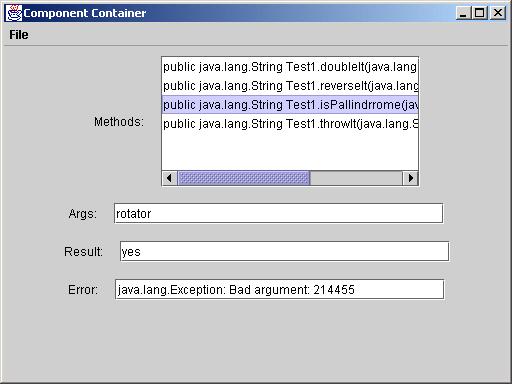
Exceptions thrown are displayed in the error field:
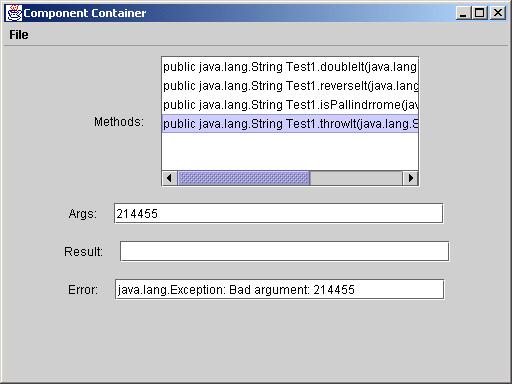
You will find two files called Test1.class and Test2.class. You should show screen shots of the result of invoking the methods in these classes. Of course your program should not be hardwired to work with only these classes.