5. Design: Principles and Patterns
Modularity and Abstraction
The goal of every program is to be useful (solve the right problems), usable (easy to use), and modifiable (easy to maintain). Two important design principles that help developers achieve the last goal are modularity and abstraction:
The Modularity
Principle
Systems should be decomposed into cohesive, loosely coupled modules.
The Abstraction
Principle
The interface of a module should be independent of its implementation.
Both of these principles are valid for several different definitions of module: function, object, class, ADT, or package.[1]
A cohesive module has a unified purpose, while loose coupling implies dependencies on other modules are minimized. Taken together, this makes a module easier to reuse, replace, and understand.
The abstraction principle implies that the external function or purpose of a module (the module's interface) should be separated from its internal structure (the module's implementation). A dependency on such a module is only a dependency on its public interface, not its private implementation. This frees clients[2] from the need to understand implementation details, while implementers are free to modify the implementation without the fear of breaking client code.
Cohesion
The methods of a cohesive class work together to achieve a common goal. Classes that try to do too many marginally related tasks are difficult to understand, reuse, and maintain.
Although there is no precise way to measure the cohesiveness of a class, we can identify several common "degrees" of cohesiveness. At the low end of our spectrum is coincidental cohesion. A class exhibits coincidental cohesion if the tasks its methods perform are totally unrelated:
class MyFuns {
void initPrinter() { ... }
double calcInterest() { ... }
Date getDate() { ... }
}
The next step up from coincidental cohesion is logical cohesion. A class exhibits logical cohesion if the tasks its methods perform are conceptually related. For example, the methods of the following class are related by the mathematical concept of area:
class AreaFuns {
double circleArea() { ... }
double rectangleArea() { ... }
double triangleArea() { ... }
}
A logically cohesive class also exhibits temporal cohesion if the tasks its methods perform are invoked at or near the same time. For example, the methods of the following class are related by the device initialization concept, and they are all invoked at system boot time:
class InitFuns {
void initDisk() { ... }
void initPrinter() { ... }
void initMonitor() { ... }
}
One reason why coincidental, logical, and temporal cohesion are at the low end of our cohesion scale is because instances of such classes are unrelated to objects in the application domain. For example, suppose x and y are instances of the InitFuns class:
InitFuns x = InitFuns(), y = new InitFuns();
How can we interpret x, and y? What do they represent? How are they different?
A class exhibits procedural cohesion, the next step up in our cohesion scale, if the tasks its methods perform are steps in the same application domain process. For example, if the application domain is a kitchen, then cake making is an important application domain process. Each cake we bake is the product of an instance of a MakeCake class:
class MakeCake {
void addIngredients() { ... }
void mix() { ... }
void bake() { ... }
}
A class exhibits informational cohesion if the tasks its methods perform are services performed by application domain objects. Our Airplane class exhibits informational cohesion, because different instances represent different airplanes:
class Airplane {
void takeoff() { ... }
void fly() { ... }
void land() { ... }
}
Note that the informational cohesion of this class is ruined if we add a method for computing taxes or browsing web pages.
Dependency and Encumbrance
Assume A and B are classes, interfaces, or packages. A depends on B if changes to B could cause changes to A. UML represents dependency using dependency arrows:
We symbolize this relationship as:
A << B
Dependency is a reflexive, transitive relationship:
A << A
A << B and B << C implies A << C
The dependency relationship extends the idea of one class referencing another:
A references B implies A << B
Where A references B if:
1. A extends or implements B
2. A has a field of type B
3. A has a method that references B
4. B appears as a template parameter in A (C++ only)
5. B is a friend of A (C++ only)
6. A references a B pointer, reference, or array
A method, A.m, references B if:
1. B appears in the signature of A.m
2. A.m has a local variable of type B
3. A.m uses a global variable of type B (C++ only)
One might wonder if there are other, sneaky ways for class A to depend on class B. Certainly any such "hidden" dependencies would make A harder to understand, modify, or reuse. The Transparency Principle[3] suggests that programmers avoid hidden dependencies. We can formalize the Transparency Principle by demanding that the dependency relationship is no more than the transitive closure of the references relationship:
A << B implies A references some C where C << B
The transitive closure of A:
TC(A) = { B | A << B }
gives us an idea of how much support A requires. For example, if A is a stand-alone class, then:
TC(A) = { A }
Clearly, the larger TC(A) is, the harder it is to reuse, understand, or replace A.
We can extend the concept of dependence and transitive closure to objects in the obvious way:
TC(obj) = { x | obj << x }
Saving an object to a file or database, or sending this object to a remote object over a network will require saving or sending the entire transitive closure of that object. The size of the transitive closure-- called the encumbrance of a class, package, or object-- is a crude measure of the required set of support:
encumbrance(A) = |TC(A)|
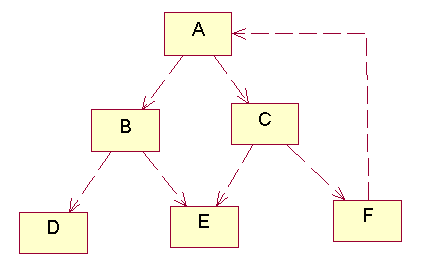
Structure of TC(A)
Bi-directional dependencies are possible
A << B AND B << A
In other words, TC(A) doesn't necessarily have a nice tree-like structure. Officially, TC(A) is a directed graph:
Coupling
The concept of coupling refines the notion of dependence by attempting to qualify and quantify the strength of the dependency of one class on another.
Assume A depends on B:
A << B
If A and B are loosely coupled, only major changes to certain methods of B should impact A. If A and B are tightly coupled, then small changes to B can have a dramatic impact on A.
Although there is no precise way to measure how tightly an association couples one class to another, we can identify several common coupling "degrees". For example, assume an E-commerce server keeps track of customers and the transactions they commit:
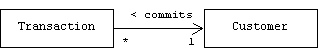
Normally, this would mean that the Transaction class has a member variable that points to a Customer:
class Transaction {
Customer customer;
// etc.
}
Some changes to the Customer class will impact the Transaction class, but some will not. For example, changing the private members of the Customer class should have no impact. This is the most common form of coupling. For lack of a better term, we will call this client coupling.
On the other hand, if a C++ Transaction class is a friend of the Customer class:
class Customer
{
friend class Transaction;
// etc.
};
Then Transaction is content coupled to Customer. Changes to the private members of Customer could impact Transaction. Declaring one class to be the friend of another tightens the coupling between the two classes.
If Customer is an interface for corporate and individual customers:
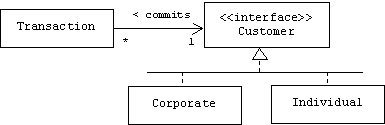
Then the Transaction class can't even be sure what type of object its customer pointer points at. There is no mention in the Transaction class of corporate or individual customers, only customers. Transactions can call public Corporate and Individual methods that are explicitly declared in the Customer interface. Other public methods such as Corporate::getCEO() or Individual::getSpouse() are not visible to transaction objects. Transaction exhibits interface coupling with the Corporate and Individual classes. Obviously interface coupling is looser than client coupling.
Message passing also helps to loosen the coupling between objects. For example, suppose an object representing an ATM machine mediates between transactions and customers:
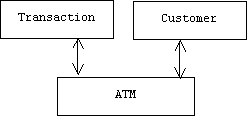
In this case transactions and customers communicate by passing messages through the ATM machine, which means that the transaction doesn't even need to know the location of the customer. We shall call this message coupling. Short of totally uncoupled, we can achieve the loosest form of coupling by combining interface and message coupling.
Domains
Instead of refining the notion of dependency, we can make the notion less precise by introducing common "levels of dependency". [JONES] calls these levels domains, although this terminology can lead to ambiguity problems. [JONES] identifies four levels of dependency:
1. Foundationl classes
2. Architectural classes
3. Domain-specific classes
4. Application-specific classes
The term "domain" refers to the application domain. This is the real world context of the application. Health care, business, manufacturing, and engineering are broad examples of application domains. A domain-specific object represents an object in the application domain. For example, a customer object in a business application would represent a real customer in the application domain. Thus, we can think of a customer object as a virtual or simulated customer. A well designed customer object might be reused or shared by other applications in the business domain, but it seems unlikely that it would be useful in a domain such as scientific measurement.
Examples of foundational components include quantities, strings, dates, and containers. A quantity is a number together with a unit, such as "3.5 US dollars", or "3.5 kilometers". A container is a data structure that holds other objects. Stacks, queues, lists, and arrays are common examples. It's easy to imagine that a well designed stack would be useful in a wide variety of applications cutting across architectures and domains.
Examples of application-specific objects include commands, command processors, and view windows. It's easy to imagine that while two applications in the business domain might share the same customer objects, it seems less likely that these applications would display the customer in the same way or respond to the same user commands in the same way.
Examples of architectural components include message dispatchers and remote server proxies. For example, a well designed database proxy would be useful in any application that needs to encapsulate access to a remote database.
Mixed Domain Coupling
Typically, a class at level n depends on other classes at level m for m <= n, but not classes at level m for n < m. Classes that violate this principle are called mixed domain classes:
class Account {
View accountView; // app-specific
...
}
class Real {
Angle arctan() { ... }
Centigrade convert() { ... }
USDollars convert() { ... }
}
Abstraction
Interfaces
When it is time to upgrade or replace a chip in a computer, the old chip is simply popped out of the motherboard, and the new chip is plugged in. It doesn't matter if the new chip and old chip have the same manufacturer or the same internal circuitry, as long as they both "look" the same to the motherboard and the other chips in the computer. The same is true for car, television, and sewing machine components. Open architecture systems and "Pluggable" components allow customers to shop around for cheap, third-party generic components, or expensive, third-party high-performance components.
An interface is a collection of operator specifications. An operator specification may include a name, return type, parameter list, exception list, pre-conditions, and post-conditions. A class implements an interface if it implements the specified operators. A software component is an object that is known to its clients only through the interfaces it implements. Often, the client of a component is called a container. If software components are analogous to pluggable computer chips, then containers are analogous to the motherboards that contain and connect these chips. For example, an electronic commerce server might be designed as a container that contains and connects pluggable inventory, billing, and shipping components. A control panel might be implemented as a container that contains and connects pluggable calculator, calendar, and address book components. Java Beans and ActiveX controls are familiar examples of software components.
Interfaces and Components in UML
Modelers can represent interfaces in UML class diagrams using class icons stereotyped as interfaces. The relationship between an interface and a class that realizes or implements it is indicated by a dashed generalization arrow:
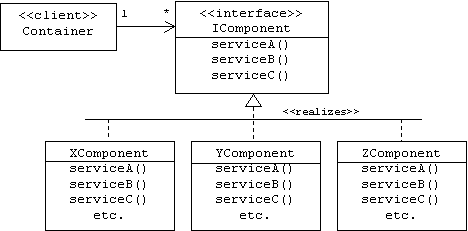
Notice that the container doesn't know the type of components it uses. It only knows that its components realize or implement the IComponent interface.
For example, imagine that a pilot flies an aircraft by remote control from inside of a windowless hangar. The pilot holds a controller with three controls labeled: TAKEOFF, FLY, and LAND, but he has no idea what type of aircraft the controller controls. It could be an airplane, a blimp, a helicopter, perhaps it's a space ship. Although this scenario may sound implausible, the pilot's situation is analogous to the situation any container faces: it controls components blindly through interfaces, without knowing the types of the components. Here is the corresponding class diagram:
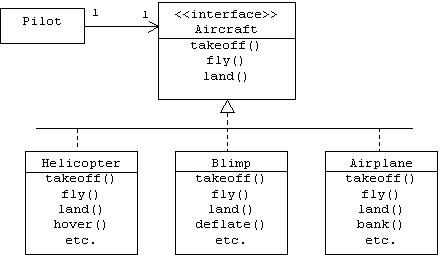
Notice that all three realizations of the Aircraft interface support additional operations: airplanes can bank, helicopters can hover, and blimps can deflate. However, the pilot doesn't get to call these functions. The pilot only knows about the operations that are specifically declared in the Aircraft interface.
We can create new interfaces from existing interfaces using generalization. For example, the Airliner interface specializes the Aircraft and (Passenger) Carrier interfaces. The PassengerPlane class implements the Airliner interface, which means that it must implement the operations specified in the Aircraft and Carrier interfaces as well. Fortunately, it inherits implementations of the Aircraft interface from its Airplane super-class:
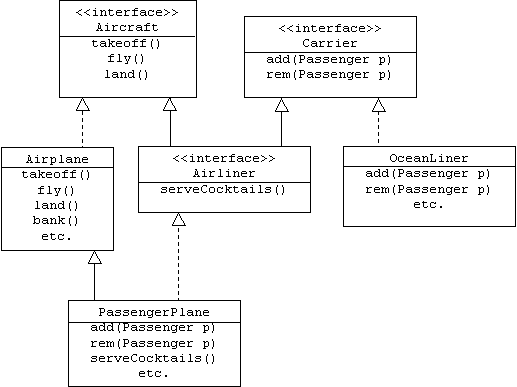
An interface is closely related to the idea of an abstract data type (ADT). In addition to the operator prototypes, an ADT might also specify the pre- and post-conditions of these operators. For example, the pre-condition for the Aircraft interface's takeoff() operator might be that the aircraft's altitude and airspeed are zero, and the post-condition might be that the aircraft's altitude and airspeed are greater than zero.
Interfaces and Components in Java
Java allows programmers to explicitly declare interfaces:
interface Aircraft {
public void takeoff();
public void fly();
public void land();
}
Notice that the interface declaration lacks private and protected members. There are no attributes, and no implementation information is provided.
A Pilot uses an Aircraft reference to control various types of aircraft:
class Pilot {
private Aircraft myAircraft;
public void fly() {
myAircraft.takeoff();
myAircraft.fly();
myAircraft.land();
}
public void setAircraft(Aircraft a) {
myAircraft = a;
}
// etc.
}
Java also allows programmers to explicitly declare that a class implements an interface:
class Airplane implements Aircraft {
public void takeoff() { /* Airplane
takeoff algorithm */ }
public void fly() { /* Airplane fly
algorithm */ }
public void land() { /* Airplane land
algorithm */ }
public void bank(int degrees) { /* only
airplanes can do this */ }
// etc.
}
The following code shows how a pilot flies a blimp and a helicopter:
Pilot p = new Pilot("Charlie");
p.setAircraft(new Blimp());
p.fly(); // Charlie flies a blimp!
p.setAircraft(new Helicopter());
p.fly(); // now Charlie flies a helicopter!
It is important to realize that Aircraft is an interface, not a class. As such, it cannot be instantiated:
p.setAircraft(new Aircraft()); // error!
Java also allows programmers to create new interfaces from existing interfaces by extension:
interface Airliner extends Aircraft, Carrier {
public void serveCocktails();
}
Although a Java class can only extend at most one class (multiple inheritance is forbidden in Java), a Java interface can extend multiple interfaces and a Java class can implement multiple interfaces. A Java class can even extend and implement at the same time:
class PassengerPlane extends Airplane implements Airliner {
public void add(Passenger p) { ... }
public void rem(Passenger p) { ... }
public void serveCocktails() { ... }
// etc.
}
Abstract Classes
Classes only inherit obligations from the interfaces they implement—obligations to implement the specified methods. By contrast, an abstract class is a partially defined class. Classes derived from an abstract class inherit both features and obligations. For example, airplanes, blimps, and helicopters all have altitude and speed attributes. Why not declare these attributes, as well as their attending getter and setter functions, in the Aircraft base class:
abstract public class Aircraft {
protected double altitude = 0, speed =
0;
public Aircraft(double a, double s) {
altitude = a;
speed = s;
}
public Aircraft() {
altitude = speed = 0;
}
public double getSpeed() { return speed;
}
public double getAltitude() { return
altitude; }
public void setSpeed(double s) { speed
= s; }
public double setAltitude(double a) {
altitude = a; }
abstract public void takeoff();
abstract public void fly();
abstract public void land();
}
Aircraft is no longer an interface, because it contains fields and implemented methods. But takeoff(), fly(), land() are abstract methods, which means users still won't be allowed to instantiate the Aircraft class.
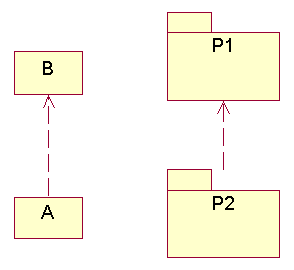
Names of abstract classes and virtual functions are italicized in UML:
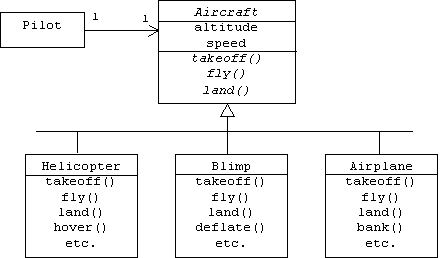
Architectural Patterns
Sometimes the same architectural design recurs in diverse applications. We call this an architectural pattern. Here are a few examples.
Container-Component
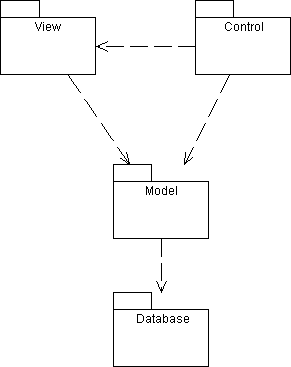
Model-View-Control
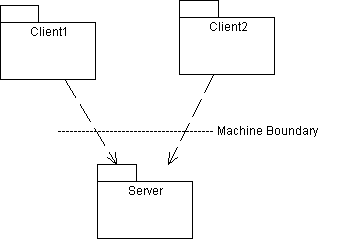
Client-Server
Reflection
Layers
Package Structures
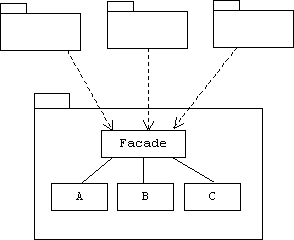
There are a few other patterns that are used for developing packages. To loosen the coupling between packages, the facade pattern designates one class as the package interface to the others. A package only exports its facade:
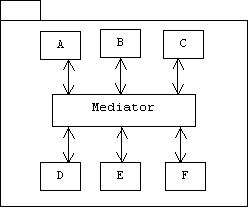
The mediator minimizes the connections between classes within a package:
Design Patterns
Publisher-Subscriber
Resource Managers
Programs normally have complete control over the objects they create. This is fine provided these objects are not shared or sensitive resources such as threads, windows, and databases. Giving a program complete control over such a resource could be risky. What would happen, for example, if a program created a fake desktop, modified a database while another program was querying it, or created a run away thread that couldn't be interrupted?
One way to prevent such problems is to associate a resource manager to each resource class (resources are instances of resource classes). The resource manager alone is responsible for creating, manipulating, and destroying instances of that class. Resource managers provide a layer of indirection between programs and the resources they use:
Resource Manager [ROG]
Other Names
Object manager, lifecycle manager
Problem
In some situations we may need to hide from clients the details how certain resources are allocated, deallocated, manipulated, serialized, and deserialized. In general, we may need to control client access to these objects.
Solution
A resource manager is responsible for allocating, deallocating, manipulating, tracking, serializing, and deserializing certain types of resource objects. A resource manager adds a layer of indirection between clients and resources. This layer may be used to detect illegal or risky client requests. In addition, the resource manager may provide operations that can be applied to all instances of the resource such as "save all", statistical information such as "get count", or meta-level information such as "get properties".
Static Structure
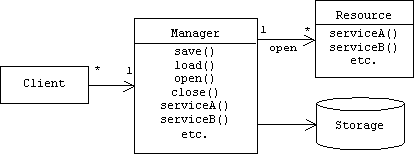
A resource manager is a singleton that maintains a table of all instances of the resource that are currently open for use:
class Manager
{
public:
int open(); // resource factory method
bool close(int i);
bool serviceA(int i);
bool serviceB(int i);
// etc.
private:
map<int, Resource*> open;
bool authorized(...); // various
parameters
};
If the caller is authorized, the open() function creates a new resource object, places it in the table, then returns the index to the caller. Clients must use this index number when subsequently referring to the resource. For example, here's how an authorized client invokes the serviceA() method of a previously allocated resource:
bool Manager::serviceA(int i)
{
if (!authorized(...)) return false; //
fail
open[i]->serviceA();
return true; // success
}
Authorization can have a variety of meanings: Does the requested resource exist? Does the client have access rights to it? Is it currently available?Is the proposed operation legal?
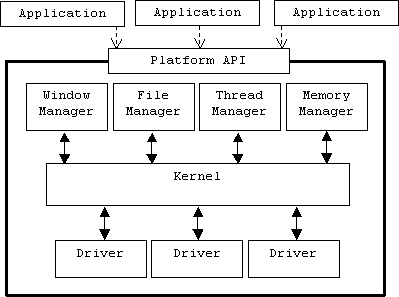
An operating system provides resource managers for most classes of system resources:
Commands and Command Processors
Instead of directly modifying the model in response to user inputs, controllers create commands and forward them to a centralized command processor. It is the job of the command processor to execute the commands.
One advantage of this arrangement is that it makes it easy to provide several types of controllers that do the same thing. For example, most menu selections have corresponding tool bar buttons and hot key combinations that perform the same action. More advanced users prefer the tool bar or keyboard because they are faster to use, while beginners can make the GUI simpler by hiding the tool bar. We can avoid coding redundancy by having multiple controllers create the same type of command. Thus a menu selection and its corresponding toll bar button can create the same type of command object:
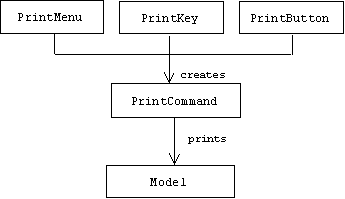
Controllers send the commands they create to a centralized command processor object. It is the job of the command processor to execute the commands it receives, but it can do a lot more. For example, by keeping track of all commands, the command processor can implement application-independent commands such as undo, redo, and rollback. All of this is summarized in the command processor pattern:
Command Processor [POSA] [Go4]
Other Names
Commands are also called actions and transactions.
Problem
A framework wishes to provide an undo/redo mechanism, and perhaps other features such as scheduling, concurrency, roll back, history mechanisms, or the ability to associate the same action to different types of controllers (e.g. for novice and advanced user).
Solution
Create an abstract base class for all commands in the framework. This base class specifies the interface all concrete command types must implement.
Commands are created by controllers such as menu selections, buttons, text boxes, and consoles. The commands are forwarded to a command processor, which can store, execute, undo, redo, and schedule them.
In the smart command variant of the pattern, commands know how to execute themselves. In the dumb command variant commands are simply tokens, and the command processor must know how to execute them.
Scenario
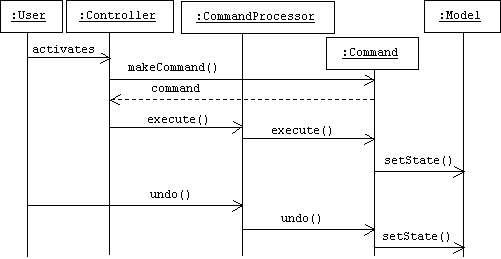
When a user clicks a button, selects a menu item, or activates some other type of controller, the controller creates an appropriate command object, then asks the command processor to execute it. If we are using dumb commands, then either the command processor must know how to execute the command, which implies some knowledge of the application, or the command processor must ask some other component, such as the model, to execute the command. In the smart command variant, the commands are objects that know how to execute and undo themselves:
Model-View-Controller
The Model-View-Controller design pattern formalizes the Model-View-Controller architecture and the presentation-application independence principle:
Model-View-Controller [POSE]
Other Names
MVC, Model-View-Controller architecture, Model-View architecture, Model-View Separation pattern, Document-View architecture.
Problem
The user interface is the component most susceptible to change. These changes shouldn't propagate to application logic and data.
Solution
Encapsulate application logic and data in a model component. View components are responsible for displaying application data, while controller components are responsible for updating application data. There are no direct links from the model to the view-controllers.
Static Structure
Note that navigation from views and controllers to their associated model is allowed, but not the reverse. A model is independent of its views and controllers, because it doesn't know about them:

For example, a model for a spread sheet might be a two dimensional array of cells containing data and equations for a family's budget:
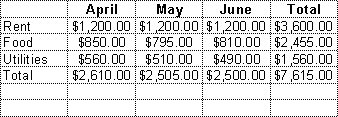
Budget
The user can choose to view this data in many ways: bar charts, pie graphs, work sheets, etc. In addition, sub windows such as menus and tool bars contain controllers that allow the user to modify the budget's data. Here's a possible object diagram:

To take another example, a model component for a word processor might be a document containing a chapter of a book. The user can view the document as an outline (outline view), as separate pages (page layout view), or as a continuous page (normal view):

Proxies
Suppose we want to add features to a server. The obvious way to do this would be to create a derived class with the added features:
class SpecialCommandServer: public CommandServer
{
// added features
};
Of course this doesn't add features to the original server. Instead, we must create new servers that instantiate the derived class.
Another approach uses the idea of the Decorator pattern introduced in Chapter 4. Instead of creating a server object that instantiates a derived class, we place a decorator-like object called a proxy between the client and the server. The proxy intercepts client requests, performs the additional services, then forwards these requests to the server. The server sends any results back to clients through the proxy.
The proxy implements the same interface as the server, so from the client's point of view the proxy appears to be the actual server. Of course the proxy has no way of knowing if the server it delegates to is the actual server or just another proxy in a long chain, and of course the server has no way of knowing if the object it provides service to is an actual client or a proxy. The idea is formalized by the Proxy design pattern:
Proxy [POSA], [Go4]
Other Names
Proxies are also called surrogates, handles, and wrappers. They are closely related in structure, but not purpose, to adapters and decorators.
Problem
1. A server may provide the basic services needed by clients, but not administrative services such as security, synchronization, collecting usage statistics, and caching recent results.
2. Inter-process communication mechanisms can introduce platform dependencies into a program. They can also be difficult to program and they are not particularly object-oriented.
Solution
Instead of communicating directly with a server, a client communicates with a proxy object that implements the server's interface, hence is indistinguishable from the original server. The proxy can perform administrative functions before delegating the client's request to the real server or another proxy that performs additional administrative functions.
Structure
To simplify creation of proxies, a Proxy base class can be introduced that facilitates the creation of delegation chains:
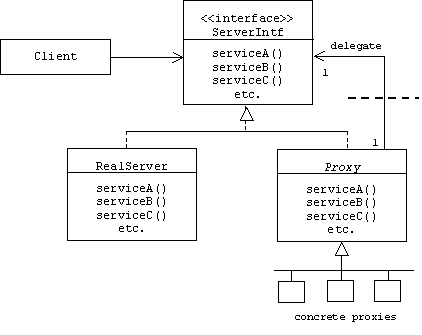
The class diagram suggests that process or machine boundaries may exist between proxies. Proxies that run in the same process or on the same machine as the client are called client-side proxies, while proxies that run in the same process or on the same machine as the server are called server-side proxies.
Scenario
As in the decorator pattern, proxies can be chained together. The client, and each proxy, believes it is delegating messages to the real server:
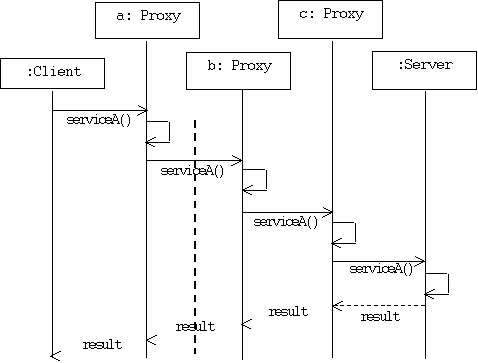
Examples of Client-Side Proxies
A firewall proxy is essentially a filter that runs on the bridge that connects a company network to the Internet. It filters out client requests and server results that may be inconsistent with company policies. For example, a firewall may deny a local web browser's request to download web pages from sites considered to host non work-related material such as today's Dilbert cartoon.
A cache proxy is a client-side proxy that searches a local cache containing recently received results. If the search is successful, the result is returned to the client without the need of establishing a connection to a remote server. Otherwise, the client request is delegated to the server or another proxy. For example, most web browsers transparently submit requests for web pages to a cache proxy, which attempts to fetch the page from a local cache of recently downloaded web pages.
Virtual proxies provide a partial result to a client while waiting for the real result to arrive from the server. For example, a web browser might display the text of a web page before the images have arrived, or a word processor might display empty rectangles where embedded objects occur.
Examples of Server-Side Proxies
Protection proxies can be used to control access to servers. For example, a protection proxy might be inserted between the CIA's web server and the Internet. It demands user identifications and passwords before it forwards client requests to the web server.
A synchronization proxy uses techniques similar to the locks discussed earlier to control the number of clients that simultaneously access a server. For example, a file server may use a synchronization proxy to insure that two clients don't attempt to write to the same file at the same time.
High-volume servers run on multiple machines called server farms. A load balancing proxy is a server-side proxy that keeps track of the load on each server in a farm and delegates client requests to the least busy server.
Counting proxies are server-side proxies that maintain usage statistics such as hit counters.
Remote Proxies and Remote Method Invocation
Communicating with remote objects through sockets is awkward. It is entirely different from communicating with local objects, where we can simply invoke a member function and wait for a return value. The socket adds an unwanted layer of indirection, it restricts us to sending and receiving strings, it exposes the underlying communication protocol, and it requires us to know the IP address or DNS name of the remote object.
A remote proxy encapsulates the details of communicating with a remote object. This creates the illusion that no process boundary separates clients and servers. Clients communicate with servers by invoking the methods of a client-side remote proxy. Servers communicate with clients by returning values to server-side remote proxies. This is called Remote Method Invocation or RMI.
For example, a client simply invokes the member functions of a local implementation of the server interface:
class Client
{
ServerIntf* server;
public:
Client(ServerIntf* s = 0);
CResult taskA(X x, Y y, Z z)
{
return server->serviceA(x, y, z);
}
// etc.
};
Internally, the client's constructor creates a client-side remote proxy, which is commonly called a stub:
Client::Client(ServerIntf* s /* = 0 */)
{
server = (s? s: new Stub(...));
}
Stubs use IPC mechanisms such as sockets to forward client requests to server-side remote proxies, which are commonly called skeletons. A Java skeleton customizes a Java version of our server framework and implements the server interface by delegating to a real server:
class Skeleton implements ServerIntf extends Server
{
private ServerIntf server = new
RealServer();
protected SkerverSlave makeSlave(Socket
s)
{
return new SkeletonSlave(s, this);
}
public JResult serviceA(U u, V v, W w)
{
return server.serivceA(u, v, w);
}
// etc.
}
The real server simply returns computed results to its local caller, the skeleton. Therefore, the server doesn't need to depend on any special inter-process communication mechanism:
class RealServer implements ServerIntf
{
public JResult serviceA(U u, V v, W w)
{
JResult result = ...; // compute
result
return result;
}
// etc.
};
The skeleton slave handles the communication with the client's stub and invokes the appropriate methods of its master, the skeleton:
class SkeletonSlave extends ServerSlave
{
protected boolean update()
{
receive request from client;
call corresponding method of
skeleton (= master);
send result back to client;
}
// etc.
}
Remote proxies can be quite complex. In our example, the message sent from the stub to the skeleton includes the name of the requested service, "serviceA," and the parameters: x, y, and z. Of course x, y, and z need not be strings. They might be C++ numbers (in which case the stub will need to converted them into strings by inserting them into string streams) or they might be arbitrary C++ objects (in which case the stub will need to serialize them using the techniques of Chapter 5). This process is called marshalling.
The problem is even more complicated in our example because the server implementation is apparently a Java object, not a C++ object. Thus, after the skeleton deserializes x, y, and z, it will have to translate them into Java data. For example, an ASCII string representing a C++ number will have to be converted into a Java Unicode sting, probably using Java character streams, then the Java string must be converted into a Java number. This process is called de-marshalling.
Of course the skeleton must marshal the result before sending it back to the stub, and the stub must de-marshal the result before returning it to the client.
Finally, the reader may well ask how the skeleton knows a received request is a string containing C++ parameters and therefore C++ to Java translation should be performed, or how does the stub know a received result is a string containing Java data and therefore Java to C++ translation should be performed? Remember, clients and servers are often developed independently.
One way to solve this problem is for all programmers to agree on a common object oriented language, let's call it COOL. Marshalling must include translating data from the implementation language into COOL, and de-marshalling must include translating data from COOL into the implementation language.
Of course getting programmers to agree on what COOL should be is difficult. The Object Management Group (OMG), is promoting a standard called the Interface Description Language, IDL. An IDL description of ServerIntf looks an awful lot like a C++ header file. Compilers are available that will automatically translate IDL interfaces into stubs and clients in most object oriented languages, including Java and C++. Microsoft is promoting a standard called the Component Object Model (COM). COM interfaces are objects that can be discovered by clients at runtime through a COM meta interface.
Dynamics
In the following scenario we enhance a real server by adding four proxies between it and a client. On the client side we have a cache proxy and a stub. On the server side we have a skeleton and a synchronization proxy. The stub and skeleton perform parameter marshalling and de-marshalling.
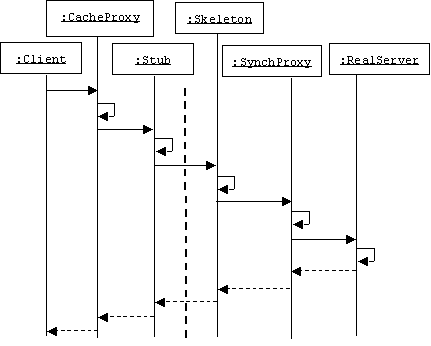
Adapters
Have you ever fried a hair dryer or electric shaver while travelling in a foreign country? The problem is that in some countries a walloping 220 volts comes out of the outlets, while most appliances made in the US expect a meager 110 volts. There are three solutions to the problem: grow a beard and sun dry your hair, use battery powered appliances, or put an adapter between the foreign outlet and your hair dryer. An adapter is a device that turns a 220 volt input into a 110 volt output.
Programmers can also face this problem. Assume a client expects a server object to conform to a specific interface. As implementers of the server, our first duty is to shop around to see if there are any server classes that can be reused. Assume we find such a class, but its interface doesn't quite conform to the interface expected by the client. This is analogous to the problem with the foreign electrical outlet that provides electricity, but doesn't conform to the interface expected by the electric razor. Our solution is analogous, too:
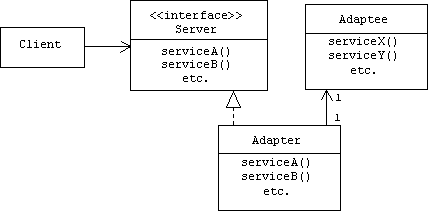
Adapter [Go4]
Other Names
Wrapper
Problem
An existing server class implements the functions required by a client, but the interface doesn't match the required interface.
Solution
Insert an adapter between the client and the server. The adapter implements the interface required by the client by calling the corresponding server functions. The adapter and server can be related by specialization or delegation.
Static Structures
The adapter design pattern defines a collaboration between four classes: the client, the server interface, the adapter, and the adaptee (i.e., the server with the wrong interface). The adapter implements the server interface in the sense described above. The client holds a reference to an adapter, but typed as a reference to a server. There are two possible relationships between the adapter: specialization or delegation.
If the adapter specializes the adaptee, then it can call the adaptee functions directly:
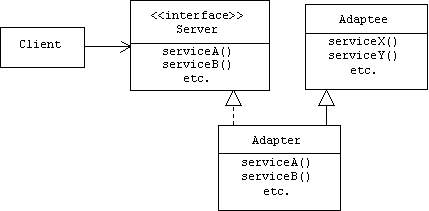
Alternatively, the adapter can access the adaptee services by delegation: