7. Active and
Distributed Objects
Overview
A client-server application is composed of interacting objects separated by process or machine boundaries. We call these distributed objects, because they may be distributed among machines connected by a network. Distributed objects must communicate using inter-process communication mechanisms such as mailboxes, sockets, brokers, and proxies.
A server may have many clients simultaneously making requests. In order to prevent a selfish client from starving the others, the server must create active objects— objects that "own" their own thread of control — each servicing a different client. Of course these active objects may need to share resources such as a database, data structure, or file. In this case the threads must use synchronization mechanisms such as mutexes or semaphores to prevent potentially harmful effects that may arise from simultaneous access.
In this chapter we will introduce mechanisms, services, and design patterns that are important for client-server applications. We begin by introducing concurrency and synchronization. Next, we define a C++ wrapper class for the Socket API. These ideas are combined to form a working, platform-independent, server framework. We introduce client-side and server-side remote proxies to hide sockets altogether. This allows clients and servers to communicate using remote method invocation. Finally, we decouple client and server by introducing a message passing broker.
Much of the platform dependence associated with threads, mutexes, semaphores, and sockets is hidden by a generic system interface defined in the programming notes at the end of the chapter. The programming notes also contain a Win32 API implementation of this interface.
Distributed
Processing
Computers normally have many programs running at the same time. This is called multi-tasking. For example, a computer may be running a spread sheet in one window, a word processor in another, and a web browser in a third. Each of these programs is working toward a different goal. Each is designed to solve a different problem. Each is "aware" of the others only in so far as they all compete for memory, processor time, and other resources.
Of course it is possible for programs to cooperate rather than compete with each other. This is called distributed processing. Instead of working on separate problems, several programs collaborate to solve the same problem. Instead of depending on the operating system to allocate and de-allocate shared resources, collaborating programs voluntarily take turns accessing shared resources.
What is the advantage of distributed processing? Surely the required communication and synchronization introduces development and runtime overhead that wouldn't be present in a more traditional non-distributed application. Indeed, sometimes it is necessary to eschew an interesting distributed solution for a less interesting traditional solution for exactly these reasons. That being said, there are at least three reasons for considering a distributed solution: sharing programs and data, eliminating control logic, and exploiting multiple processors.
Sharing Programs
and Data
The evolution of distributed processing can be divided into three eras: the time sharing era, the PC era, and the client-server era. Assume a team of engineers works together to design a new airplane. During the time sharing era (circa 1970 – 1980) an expensive central mainframe computer would have stored the data for the new design and run the programs that manipulated this data. The engineers would have communicated with the mainframe through inexpensive character terminals on their desktops that were connected to the mainframe through serial lines. While this arrangement made economic sense, it wasn't a good workload balance, because the mainframe did all of the computing, while the dumb terminals simply sent text commands to the mainframe and displayed the text results that were returned.
During the PC era (circa 1980 – 1990) each engineer would have demanded and received a personal computer. The authority and mystery of the mainframe dissolved, but PC networks were immature, so sharing programs and data was difficult. Also, the workload balance shifted too far in the other direction. Each PC needed to store and process the project data, which led to redundancy.
During the client-server era (circa 1990 – present) a centralized server program running on a powerful server machine managed project data and performed "global" computations, while client programs running on a network of inexpensive workstations called thin clients managed GUIs and performed "local" computations. The dividing line between global and local computations could be adjusted to fine tune the workload balance.
Eliminating Control
Logic
Recall that we used passive filters in our data-driven pipeline example from Chapter 2. It was our job to ensure the flow of control from one filter to the next. We accomplished this using the publisher-subscriber pattern. Alternatively, we could have built a separate pipeline control component that activated each filter according to a pre-defined schedule. In either case, the control logic, along with the application logic, was our responsibility.
Recall that an active filter "owns" a thread, in which it runs a perpetual control loop:
void Filter::controlLoop()
{
while(true)
{
Message val = inPipe->read();
val = transform(val); // do
something to val
outPipe->write(val);
}
}
Of course active filters may have to share the same CPU. This means one filter will only get to execute a few cycles of its control loop before it will be interrupted by another filter. Fortunately, scheduling the CPU is automatically done by the operating system. This means we can concentrate on application logic without worrying about control logic.
Exploiting Multiple
Processors
Of course if active filters in a pipeline do share the same CPU, the overall time it will take to run a sequence of messages through the pipeline will be about the same as the time it would take to run the same sequence of messages through a pipeline composed of passive filters. Only the filter activation order may vary. For example, if there are m messages in the sequence, n filters in the pipeline, and each filter processes a single message in k steps, then it's easy to see that processing the entire sequence would require k * m * n steps.
On the other hand, some computers have more than one processor. A clever operating system might assign active filters to different processors. In this case a filter near the beginning of the pipeline may be processing a message near the end of a message sequence at the same time a filter near the end of the pipeline is processing a message near the beginning of the message sequence. If each filter was assigned to its own processor, then a length n pipeline processing a length m sequence of messages could complete the task in k * (m + n – 1) steps, a considerable improvement over k * m * n steps. (See Problem 7.1.)
While most computers still have a single processor, a network of computers has many processors. A distributed application can take advantage of these processors by carefully assigning different components to different computers.
Inter-Process
Communication (IPC)
Objects in a non-distributed application reside in the same address space. This makes communication easy. Object A communicates with object B simply by calling B's member functions. Distributed objects have process or machine boundaries between them. Communicating across such boundaries requires some help from the underlying platform and network. There are two styles of inter-process communication: shared memory and message passing.
Shared Memory
Distributed applications normally share objects contained in files, databases, and shared memory segments (some operating systems allow programs to link shared memory segments into their address spaces). As a simple example of shared memory communication, we can imagine that some of these shared objects are "mail boxes." Distributed objects can communicate with each other by leaving messages in these mailboxes.
Blackboard
Architectures
Blackboard architectures provide a more interesting example of shared memory communication. In this architecture distributed objects called contributors communicate by updating a shared object called a blackboard. A moderator object determines the order in which contributors perform these updates. There is even a Blackboard design pattern:
Blackboard Architecture [POSA]
Problem
In many pattern recognition problems raw data collected by sensors (e.g., sounds, images, telemetry, etc.) must be transformed into high-level data structures (e.g., parse trees, component models, text, etc.). If the semantic gap between the raw data and the high-level data structures is large, then there may be no deterministic algorithm for performing the transformation. Instead, only algorithms that perform partial transformations may exist, but the order in which these algorithms should be applied isn't known in advance.
Solution
A Blackboard architecture consists of three types of components: a blackboard, a moderator, and one or more contributors. The blackboard is a shared data structure that maintains the application data in different levels. Level 0 contains the raw data itself, while the data at level n + 1 consists of transformations of level n data. The highest level will ultimately contain the high-level data structures that we seek.
A contributor or knowledge source is an independent object that is able to transform some types of level n data into level n + 1 data. Contributors don't communicate directly with each other. Instead, each one examines the blackboard, then makes a proposal for transforming the data. A proposal usually has an accompanying degree of certainty, which is based on the current state of the blackboard.
Proposals are submitted to the moderator or controller. The moderator determines which proposal might move the problem furthest toward an ultimate solution. The moderator selects a proposal, allows the corresponding contributor to update the blackboard, and the cycle repeats. In some cases the moderator may need to backtrack if it determines that the present direction will not lead to the desired solution.
Static Structure
Note: In a distributed architecture possible process or machine boundaries are shown as heavy dashed lines.

Example
HEARSAY II used a blackboard architecture to recognize human speech. In this case the raw data was acoustical data which was to be transformed into a database query. Contributors existed for transforming acoustical data (level 0, wave forms) into phonetic data (level 1, phonemes), phonetic data into lexical data (level 2, words), lexical data into syntactical data (level 3, phrases), and syntactical data into queries (level 4).
Synchronization
Although shared memory communication is easy and efficient, synchronization is a significant problem. We can predict execution order within a process, but we cannot predict execution order when the instructions are executed by different processes. For example, object A in process #1 may check a shared mail box before object B in process #2 has had a chance to insert an important message. Thus, object A misses the message, resulting in significantly different behavior than if the mail box is checked by A after B inserts the message. Shared memory communication requires some type of synchronization mechanism to force object A wait by the empty mailbox until object B's message arrives. (This was the job of the moderator in the Blackboard architecture.)
Message Passing
In some situations communication through shared memory may be difficult or impossible to arrange, or synchronization problems may be intractable. (For example, processes separated by machine boundaries can't share memory segments.) In these situations it is more natural for distributed objects to communicate by message passing. There are several variants: direct communication through sockets, indirect communication through a message broker, or virtual direct communication through proxies.
Assume objects A and B communicate through some message passing service. Assume A sends message m to B. B may be waiting for m or B may have a pre-designated message handler function that the service will automatically call with m as an argument. A may wait for a reply from B (synchronous message passing), or A may continue with its business, not caring if B received m or not (asynchronous message passing). A message passing service is connection-oriented if it guarantees that B always receives messages from A in the order in which they were sent. Otherwise, the service is connectionless, and the job of ordering the messages belongs to A and B.
Concurrency
From a human perspective a process is a sequence of instruction executions— a running program —but from the operating system's point of view a process is an object— a record of a running program —consisting of a state and a memory context.
The memory context of a process consists of the memory segments that constitute its address space (code, heap, stack, static, etc.) as well as its caches, page table, and the contents of the CPU's registers:

A process is always in one of at least four states: Ready (waiting for the CPU), Running (using the CPU), Blocked (waiting for input), or Terminated:

It is the job of an operating system component called a scheduler to allocate and de-allocate the CPU. Typically, all ready processes are stored in a ready queue. If process B is at the front of the ready queue when process A requests input, the scheduler performs a process switch:
1. Change A's state from Running to Blocked;
2. Save A's memory context;
3. Place A in a queue of blocked processes;
4. Restore B's memory context;
5. Change B's state from Ready to Running;
6. Remove B from the ready queue.
What happens if A never requests input? Some schedulers will let A use the CPU until it terminates, other schedulers are preemptive. This means they automatically take the CPU away from A after it has used the CPU for a fixed amount of time (called a time slice) without requesting input. A moves to the rear of the ready queue and the CPU is allocated to the process at the front of the ready queue.
A process switch is time consuming. Saving A's memory context and restoring B's memory context involves writing A's registers, caches, and page table to main memory, then reading B's registers, caches, and page table from main memory. If B hasn't run for a while, we can also expect a rash of page faults. The inefficiency of process switching has often discouraged programmers from using distributed architectures when the collaborating objects share the same CPU, because we must add process switching time to the time already consumed performing application-specific tasks.
To solve this problem, many operating systems allow programs to create threads. A thread is a lightweight process: it has a state and memory context, but the memory context is small, consisting only of registers and a stack. The other segments are shared with the process that created the thread.

The scheduler allocates the CPU to threads the same way it allocates the CPU to processes. (In fact, some schedulers simply consider processes to be special types of threads.) However, their smaller memory contexts make switching threads far more efficient than switching processes.
Threads
Unfortunately, threads are not part of the standard C++ library. Instead, we must rely on thread libraries provided by the underlying platform. Obviously this will make our programs platform-dependent. In Programming Note 7.1 we present implementation techniques that mitigate this problem. For now, assume the following thread class has been defined:
class Thread
{
public:
Thread(int d = 5) { state = READY;
delay = d; peer = 0; }
virtual ~Thread() { stop(); }
ThreadState getState() { return state;
}
void stop(); // RUNNING ->
TERMINATED
void start(); // READY -> RUNNING
void suspend(); // RUNNING ->
BLOCKED
void resume(); // BLOCKED -> RUNNING
void sleep(int ms); // BLOCKED for ms
miliseconds
void run(); // sleep-update loop
protected:
virtual bool update() { return false; }
// stop immediately
ThreadOID peer; // reference to a
system thread
int delay; // # msecs blocked between
calls to update()
ThreadState state;
};
A thread's state member variable indicates its current state. There are four possible values:
enum ThreadState { TERMINATED, READY, RUNNING, BLOCKED };

The run() function perpetually calls update() and sleep(delay) until either update() returns false, or until the thread state is set to TERMINATED:
void Thread::run()
{
while (state != TERMINATED && update())
sleep(delay); // be cooperative
state = TERMINATED;
}
The interleaved calls to sleep() will guarantee that CPU-bound threads won't dominate the CPU on non-preemptive operating systems.
Of course update() is a virtual function that immediately returns false. The idea is that programmers will create thread derived classes that will re-implement update() to do something more useful.
Active Objects
Most objects are passive. A passive object does nothing unless a client calls one of its member functions. When the member function terminates, the object goes back to doing nothing. The primary purpose of a passive object is to encapsulate a set of related variables. Thus, passive objects are simply high-level memory organization units.
Like a passive object, an active object[1] encapsulates a set of related variables, and like a passive object, an active object's member functions can be called by clients[2], but unlike a passive object, an active object is associated with its own thread of control. This thread of control gives an active object a temporal as well as a spatial dimension. Active objects not only passively provide services to clients, they can also be seen as tiny virtual machines that drive the application toward a goal using a perpetual control loop:
1. Inspect environment;
2. Compare environment state to goal state;
3. If same, quit;
4. Update environment;
5. Repeat.
Of course there may be many active objects, each with its own goal. In some cases these goals may even conflict with each other, but the overall effect is that the application is collectively driven toward some larger goal. In effect, active objects allow us to structure our programs as societies of virtual machines. Active objects are particularly useful in simulations of systems containing autonomous, active elements.
In this text active objects are simply instances of classes derived from the Thread class. In this case the perpetual control loop is Thread::run() and the environmental update procedure is Thread::update(), which returns false when the environment reaches the goal state.
The Master-Slave
Design Pattern
Most multithreaded applications instantiate some variant of the Master-Slave design pattern:
Master-Slave [POSA]
Problem
An identical computation must be performed many times, but with different inputs and context. The results of these computations may need to be accumulated. If possible, we would like to take advantage of multiple processors.
Solution
A master thread creates multiple slave threads. Each slave performs a variation of the computation, reports the result to the master, then terminates. The master accumulates the results.
Static Structure
An active master object creates many active slave objects. Each slave object retains a pointer back to its master:

Implementation
The Slave::update() function performs a basic task, then returns true if it needs to be called again, otherwise false is returned and the slave terminates. Each slave is equipped with a pointer back to its master:
class Slave: public Thread
{
public:
Slave(Master* m = 0) { myMaster = m; }
protected:
bool update() { /* basic slave task
goes here */ }
Master* myMaster;
};
The master controls communication and coordination among its collection of slaves. The master's work is also accomplished by repeated calls to its update() function:
class Master: public Thread
{
protected:
bool update() { /* basic master task
goes here */ }
vector<Slave*> mySlaves(N);
};
The master's basic task typically includes creating and starting its slaves:
for(int i = 0; i < N; i++)
{
mySlaves[i] = new Slave(this);
mySlaves[i]->start();
}
Example: The
Producer-Consumer Problem
In the traditional Producer-Consumer problem a producer thread produces imaginary objects called widgets and places them in a buffer. At the same time a consumer thread removes widgets from the buffer and consumes them.

Despite its simplicity, this problem contains a number of synchronization problems. For example, assume the buffer is a length N array of widget pointers:
Widget* buffer[N];
Assume the producer always places new widget pointers at
buffer[k] and the consumer always consumes *buffer[k - 1], where k is the
current number of widgets in the buffer (0 £ k < N). Assume the
consumer consumes *buffer[k - 1] at the same moment the produce places a
pointer to a new widget at buffer[k]. Which widget will the consumer consume
next? Will it consume *buffer[k – 2], not realizing there is a pointer to a new
widget in buffer[k]? After the consumer consumes *buffer[0] it will enter a
blocked state waiting for the producer to produce more widgets. Meanwhile,
after the producer fills buffer[N – 1], it will enter a blocked state waiting
for the consumer to make some more room. This is called deadlock.
Alternatively, the consumer may notice the new widget pointer and consume
*buffer[k] next. Eventually, the consumer will attempt to re-consume *buffer[k
– 1]. The invalid pointer in
buffer[k – 1] will cause a program error or a crash.
Buffers
A joint bank account provides a simple example of the Producer-Consumer problem. In this context the buffer is a shared bank account, widgets are dollars, producers deposit dollars into the account, and consumers withdraw dollars from the account.
class Account
{
public:
Account(double bal = 0) { balance =
bal; }
void deposit(double amt);
void withdraw(double amt);
private:
double balance;
};
Our first implementation of the deposit() member function copies the balance member variable into a local variable, adds the deposited amount, goes to sleep for 500 milliseconds to simulate production time, then copies the local variable back into the deposit member variable. The output statements merely print diagnostic messages:
void Account::deposit(double amt)
{
cout << "depositing $"
<< amt << endl;
double temp = balance + amt;
System::impl->sleep(500); //
simulate production time
balance = temp;
cout << "exiting deposit(),
balance = $" << balance << endl;
}
Like the deposit() function, the withdraw() function also copies the balance member variable into a local variable, performs the deduction, sleeps for 350 milliseconds to simulate consumption time (spending it is always easier than making it), then copies the local variable back into the balance member variable:
void Account::withdraw(double amt)
{
cout << "... withdrawing
$" << amt << endl;
double temp = balance – amt;
System::impl->sleep(350); //
simulate consumption time
if (amt <= balance)
balance = temp;
else
cout << "... sorry,
insufficient funds\n";
cout << "... exiting
withdraw(), balance = $";
cout << balance << endl;
}
(See Programming Note 7.1 for a discussion of System::impl and System::sleep().)
Producer Slaves
Each producer encapsulates a pointer to the joint account and a counter that determines how many times its update() function will be called by the inherited Thread::run() function. (Recall that Thread::run() terminates when update() returns false.) If the counter is non-negative, then the update() function decrements the counter and deposits $10 in the joint account. If the initial value of the counter is 5, the default, then the total amount deposited will be 6 * $10 = $60.
class Depositor: public Thread
{
public:
Depositor(Account* acct = 0, int cycles
= 5)
{
account = acct;
counter = cycles;
}
bool update()
{
if (counter-- < 0) return false;
account->deposit(10);
return true;
}
private:
int counter;
Account* account;
};
Consumer Slaves
Each consumer thread also encapsulates a pointer to the shared account and a counter that determines how many times its update() function will be called. If the counter is non-negative, then the update() function decrements the counter and withdraws $8 from the joint account. If the initial value of the counter is 5, the default, and if the "insufficient funds" message never appears, then the total amount withdrawn will be 6 * $8 = $48.
class Withdrawer: public Thread
{
public:
Withdrawer(Account* acct = 0, int
cycles = 5)
{
account = acct;
counter = cycles;
}
bool update()
{
if (counter-- < 0) return false;
account->withdraw(8);
return true;
}
private:
int counter;
Account* account;
};
The Master
The master thread creates an account with an initial balance of $100, a producer slave and a consumer slave are created and started, then the master enters a blocked state waiting for keyboard input from the user. This prevents the master from terminating while its slaves are still at work.
int main()
{ // the master thread
Account* acct = new Account(100);
Depositor* depositor = new Depositor(acct);
Withdrawer* withdrawer = new
Withdrawer(acct);
depositor->start();
withdrawer->start();
cout << "press any key to
quit\n";
cin.sync();
cin.get(); // block until slaves are
done
return 0;
}
A Sample Run
Here's the output produced by the first test run of the program. For readability, the diagnostic messages from Account::withdraw() are indented, while the Account::deposit() messages are left justified:
depositing $10
... withdrawing $8
... exiting withdraw(), balance = $92
... withdrawing $8
exiting deposit(), balance = $110
depositing $10
... exiting withdraw(), balance = $84
... withdrawing $8
exiting deposit(), balance = $120
depositing $10
... exiting withdraw(), balance = $76
... withdrawing $8
... exiting withdraw(), balance = $68
... withdrawing $8
exiting deposit(), balance = $130
depositing $10
... exiting withdraw(), balance = $60
... withdrawing $8
exiting deposit(), balance = $140
depositing $10
... exiting withdraw(), balance = $52
exiting deposit(), balance = $150
depositing $10
exiting deposit(), balance = $160
Synchronization
Notice that the producer
deposited $10 six times for a total of $60. The consumer withdrew $8 six times—
the "insufficient funds" message never appeared — for a total of $48.
Since the account initially contained $100, the final balance should have been
$100 + $60 - $48 = $112, not $160. We got into trouble right away when the
consumer interrupted the producer before the balance was updated to $110:
depositing $10
... withdrawing $8
... exiting withdraw(), balance = $92
... withdrawing $8
exiting deposit(), balance = $110
Readers might think that the
root of the problem is the leisurely pace of the Account's deposit() and
withdraw() member functions. Perhaps if we reduced these functions to single
lines we could have avoided the interruption problem:
void Account::deposit(double amt) { balance += amt; }
void Account::withdraw(double amt) { balance -= amt; }
This idea appears to work
until we set the withdrawer and depositor counters to a large value, say
30,000, then, eventually, the problem reappears. The real problem is that while
a typical CPU will complete the execution of an assembly language instruction
without interruption, the same is not true for a C++ instruction. Even the simple
C++ instruction:
balance += amt;
may translate into several
assembly language instructions:
mov reg1, balance //
register1 = balance
mov reg2, amt // register2 = amt
add reg1, reg2 // register1 +=
register2
mov balance, reg1 // balance = register1
Eventually this sequence will
be interrupted by the withdrawer thread sometime after the first instruction
but before the last. When that happens, the amount withdrawn will be lost.
Locks
One way to coordinate access
to a shared resource like a joint bank account is to associate a lock with the
resource. A lock is an object that is always in either a locked or an unlocked
state, and it provides indivisible lock() and unlock() operations for changing
this state. (An operation is indivisible
if it can't be interrupted by another thread.)
If a lock is unlocked, the
lock() operation simply changes the state to locked. If the lock is locked,
then the thread calling the lock() function enters a blocked state and is
placed on a queue of blocked threads waiting to access the associated resource.
If a lock is unlocked, the
unlock() operation does nothing. If it is locked and there are no blocked
threads waiting to access the associated resource, then the unlock() operation
simply changes the state back to unlocked. If there are blocked threads waiting
to access the resource, the first thread on the queue is unblocked. From the
perspective of this unblocked thread, the lock() operation it called has just
been succesfully completed: the lock is locked and the thread has gained access
to the associated resource. Unless the thread checks the system clock, it is
unaware that it has been languishing on a queue of blocked threads since it
called lock().
Assume the following Lock
class has been implemented:
class Lock
{
public:
Lock();
void lock(); // state = locked
void unlock(); // state = unlocked
private:
LockOID peer; // reference to a system lock
};
Implementing Lock::lock() and Lock::unlock() requires the ability to disable interrupts and the ability to block, queue, and unblock system threads. For this reason locks are usually created, managed, and destroyed by the operating system. Semaphores and mutexes are examples of system level locks. In our implementation the peer member variable identifies the corresponding system lock. The Lock::lock() and Lock::unlock() functions simply delegate to corresponding system lock member functions. See Programming Note 7.2 for details.
A Thread-Safe
Buffer
We can make shared resources such as joint bank accounts safe for access by multiple threads by equipping them with locks.
class Account
{
public:
Account(double bal = 0) { balance =
bal; }
void deposit(double amt);
void withdraw(double amt);
private:
double balance;
Lock
myLock;
};
Account::deposit() and Account::withdraw() call the associated lock's lock() function upon entry and call the unlock() function upon exit:
void Account::deposit(double amt)
{
myLock.lock();
// as before
myLock.unlock();
}
void Account::withdraw(double amt)
{
myLock.lock();
// as before
myLock.unlock();
}
It's important to realize that there is only one lock per bank account. When it's locked, either by the call to lock() at the top of Account::withdraw() or the call at the top of Account::deposit(), all other threads must wait for unlock() to be called before they can call either of these functions. If we could peer into the computer's memory, we might see a locked account with an associated queue of depositors and withdrawers waiting to gain access:
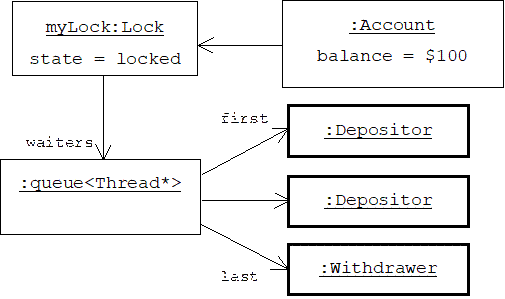
Another Sample Run
Running the simulation a second time using a lockable account produces the desired synchronization between the depositor and withdrawer threads:
depositing $10
exiting deposit(), balance = $110
... withdrawing $8
... exiting withdraw(), balance = $102
depositing $10
exiting deposit(), balance = $112
... withdrawing $8
... exiting withdraw(), balance = $104
depositing $10
exiting deposit(), balance = $114
... withdrawing $8
... exiting withdraw(), balance = $106
depositing $10
exiting deposit(), balance = $116
... withdrawing $8
... exiting withdraw(), balance = $108
depositing $10
exiting deposit(), balance = $118
... withdrawing $8
... exiting withdraw(), balance = $110
depositing $10
exiting deposit(), balance = $120
... withdrawing $8
... exiting withdraw(), balance = $112
Notice that the depositor never interrupts the withdrawer, and the withdrawer never interrupts the depositor. At the end of the simulation, no money has been lost or gained.
Direct
Communication
If objects A and B are separated by a machine boundary, then they must communicate with each other by sending messages across a network. The simplest method is to equip A and B with connected sockets. A socket is basically a transceiver. A transceiver combines a transmitter (an object that can be used to send or transmit messages) with a receiver (an object that can receive messages). Telephones, CB radios, and mailboxes are examples of transceivers. Of course a transceiver is only useful if it is connected to another transceiver in such a way that messages sent by one are received by the other and vice versa:

Assume the following Socket class has been implemented:
class Socket
{
public:
Socket(int port = 0, string name =
"localhost");
Socket(SocketOID sock) { peer = sock; }
~Socket() { closesocket(oid); }
void send(string msg); // uses TCP
string receive();
private:
SocketOID peer; // socket descriptor
};
Example: A Date
Client
Most standard Internet servers— ftp servers, telnet servers, web servers, etc.— perpetually listen for clients at well known port numbers below 100. For example, most computers are equipped with a date server that listens for clients at port 13. When a connection is made, the date server sends the local date and time to the client.
When an instance of our DateClient class is created, the constructor attempts to create a socket connected to the data server of a specified host. Much can go wrong. The client machine may be disconnected from the network, the server machine may be down, the date server may not be running, or the domain name address may be bad. Our Socket constructor throws an exception if anything like this happens. Once connected, the date client gets the date by calling the socket's receive function:
class DateClient
{
public:
DateClient(string serverLoc =
"localhost")
{
try { server = new Socket(13,
serverLoc); }
catch(runtime_error e) {
error(e.what()); }
}
string getDate() { return
server->receive(); }
protected:
Socket* server;
};
Here and elsewhere we are using the error() function defined in appendix 3 (util.h). Recall that this function prints its argument to cerr, then either terminates the application or throws an exception.
A Server Framework
Most servers follow the same basic design, so instead of developing a single example of a server, we develop a server framework that can be easily customized.
Our server framework uses the Master-Slave design pattern. The server is the master. It perpetually listens for client requests. When a client request arrives, the server creates a slave to service the client, then goes back to listening for more clients. If the server attempted to service clients by itself, then many clients would get a "busy signal" when they attempted to connect to the server.

What type of server slave should the server create? Our Server class is equipped with a virtual factory method that will be implemented in various derived classes to produce the right types of slaves:
class Server
{
public:
Server(int port = 5001);
void listen();
protected:
SocketOID peer; // server socket descriptor
virtual ServerSlave* makeSlave(Socket*
cs, Server* m) = 0;
};
The complete details of Server::listen() are given in Programming Note 7.6. For now, it is sufficient to know that listen() perpetually removes descriptors of sockets connected to clients from a queue of clients waiting for service (using the Socket API accept() function), creates a slave with a socket connected to the client, then starts the slave:
while(true)
{
SocketOID client = accept(...);
ServerSlave* slave = makeSlave(new Socket(client),
this);
slave->start();
}
The ServerSlave class merely serves as a polymorphic base class for all concrete server slave classes:
class ServerSlave: public Thread
{
public:
ServerSlave(Socket* s = 0, Server* m =
0)
{
sock = s;
master = m;
}
virtual ~ServerSlave() { delete sock; }
protected:
Socket* sock; // connected to a client
Server* master;
};
Example: A Command
Server Framework
We can extend our server framework to a command server. A command slave interprets client messages as commands that need to be executed. The slave executes each command, then sends the result back to the client. Of course execute() is a virtual function that needs to be re-implemented in derived server slave classes:
class CommandSlave: public ServerSlave
{
public:
CommandSlave(Socket* cs = 0, Server* m
= 0)
: ServerSlave(cs, m) {}
bool update();
protected:
virtual string execute(string cmmd)
{
return string("echo: ") +
cmmd; // for now
}
};
Server slaves are threads, hence we need to provide them with an update() function. A command slave's function receives a command from the client, executes the command, sends the result back, then returns true. Recall that this will cause Thread::run() to repeatedly call update(). The loop terminates when the client sends the "quit" command:
bool CommandSlave::update()
{
string command, result;
command = sock->receive();
cout << "command = "
<< command << endl;
if (command == "quit")
{
cout << "slave quitting
...\n";
return false; // terminate thread
}
try
{
result
= execute(command);
cout << "result = "
<< result << endl;
}
catch(runtime_error e)
{
result = e.what();
}
sock->send(result);
return true; // keep thread going
}
Of course we also need a command slave factory method. This is implemented in a Server-derived class:
class CommandServer: public Server
{
public:
ServerSlave* makeSlave(Socket* cs)
{
return new CommandSlave(cs, this);
}
};
Many commercial servers implement slave factories so that they allocate slaves from a slave pool instead of creating new ones. This implementation is explored in the problem section.
Example: A Command
Client
Command client constructor attempts to create a socket connection to the command server.
class CommandClient
{
public:
CommandClient(string serverLoc =
"localhost",
int serverPort = 5001)
{
try
{
server = new Socket(serverPort,
serverLoc);
}
catch(SockException e) {
error(e.what()); }
}
void controlLoop();
protected:
Socket* server;
};
Once a command client is created, we can simply start its control loop, which perpetually prompts the user for a command, sends the command to the server, then receives and displays the result returned by the server:
void CommandClient::controlLoop()
{
bool more = true;
string msg, response;
while(more)
{
cout << "command ->
";
getline(cin, msg); // VC++ getline()
is broken[3]
try
{
if (msg == "quit")
{
more = false;
server->send(msg);
}
else
{
server->send(msg);
response =
server->receive();
cout << "result =
" << response << endl;
}
}
catch(SockException e)
{
cerr << e.what() <<
endl;
more = false;
}
} // while
cout << "bye\n";
}
Indirect
Communication
In some sense we are using the term "direct communication" to mean just the opposite. Instead of normal, "face-to-face conversation", two objects separated by a process boundary must communicate with each other through sockets. To make matters worse, using sockets requires some awareness of network protocols and addressing formats. Also, transmitting anything other than a string through a socket is difficult.
In the context of C++ objects, "face-to-face conversation" means invoking member functions. No special transceiver device is required, parameters and return values can be arbitrary objects, and objects can be located using ordinary pointers rather than protocol-dependent network addresses.
Remote method invocation (RMI) combines the best of both worlds by allowing distributed objects to communicate by ordinary member function invocations. This illusion is created by introducing proxies— local representatives of remote objects— into the address space of each object. Instead of direct communication, distributed objects communicate indirectly through proxies, which hide the details of direct communication.
Proxies
Suppose we want to add features to a server. The obvious way to do this would be to create a derived class with the added features:
class SpecialCommandServer: public CommandServer
{
// added features
};
Of course this doesn't add features to the original server. Instead, we must create new servers that instantiate the derived class.
Another approach uses the idea of the Decorator pattern introduced in Chapter 4. Instead of creating a server object that instantiates a derived class, we place a decorator-like object called a proxy between the client and the server. The proxy intercepts client requests, performs the additional services, then forwards these requests to the server. The server sends any results back to clients through the proxy.
The proxy implements the same interface as the server, so from the client's point of view the proxy appears to be the actual server. Of course the proxy has no way of knowing if the server it delegates to is the actual server or just another proxy in a long chain, and of course the server has no way of knowing if the object it provides service to is an actual client or a proxy. The idea is formalized by the Proxy design pattern:
Proxy [POSA], [Go4]
Other Names
Proxies are also called surrogates, handles, and wrappers. They are closely related in structure, but not purpose, to adapters and decorators.
Problem
1. A server may provide the basic services needed by clients, but not administrative services such as security, synchronization, collecting usage statistics, and caching recent results.
2. Inter-process communication mechanisms can introduce platform dependencies into a program. They can also be difficult to program and they are not particularly object-oriented.
Solution
Instead of communicating directly with a server, a client communicates with a proxy object that implements the server's interface, hence is indistinguishable from the original server. The proxy can perform administrative functions before delegating the client's request to the real server or another proxy that performs additional administrative functions.
Structure
To simplify creation of proxies, a Proxy base class can be introduced that facilitates the creation of delegation chains:

The class diagram suggests that process or machine boundaries may exist between proxies. Proxies that run in the same process or on the same machine as the client are called client-side proxies, while proxies that run in the same process or on the same machine as the server are called server-side proxies.
Scenario
As in the decorator pattern, proxies can be chained together. The client, and each proxy, believes it is delegating messages to the real server:

Examples of
Client-Side Proxies
A firewall proxy is essentially a filter that runs on the bridge that connects a company network to the Internet. It filters out client requests and server results that may be inconsistent with company policies. For example, a firewall may deny a local web browser's request to download web pages from sites considered to host non work-related material such as today's Dilbert cartoon.
A cache proxy is a client-side proxy that searches a local cache containing recently received results. If the search is successful, the result is returned to the client without the need of establishing a connection to a remote server. Otherwise, the client request is delegated to the server or another proxy. For example, most web browsers transparently submit requests for web pages to a cache proxy, which attempts to fetch the page from a local cache of recently downloaded web pages.
Virtual proxies provide a partial result to a client while waiting for the real result to arrive from the server. For example, a web browser might display the text of a web page before the images have arrived, or a word processor might display empty rectangles where embedded objects occur.
Examples of
Server-Side Proxies
Protection proxies can be used to control access to servers. For example, a protection proxy might be inserted between the CIA's web server and the Internet. It demands user identifications and passwords before it forwards client requests to the web server.
A synchronization proxy uses techniques similar to the locks discussed earlier to control the number of clients that simultaneously access a server. For example, a file server may use a synchronization proxy to insure that two clients don't attempt to write to the same file at the same time.
High-volume servers run on multiple machines called server farms. A load balancing proxy is a server-side proxy that keeps track of the load on each server in a farm and delegates client requests to the least busy server.
Counting proxies are server-side proxies that maintain usage statistics such as hit counters.
Remote Proxies and
Remote Method Invocation
Communicating with remote objects through sockets is awkward. It is entirely different from communicating with local objects, where we can simply invoke a member function and wait for a return value. The socket adds an unwanted layer of indirection, it restricts us to sending and receiving strings, it exposes the underlying communication protocol, and it requires us to know the IP address or DNS name of the remote object.
A remote proxy encapsulates the details of communicating with a remote object. This creates the illusion that no process boundary separates clients and servers. Clients communicate with servers by invoking the methods of a client-side remote proxy. Servers communicate with clients by returning values to server-side remote proxies. This is called Remote Method Invocation or RMI.
For example, a client simply invokes the member functions of a local implementation of the server interface:
class Client
{
ServerIntf* server;
public:
Client(ServerIntf* s = 0);
CResult taskA(X x, Y y, Z z)
{
return server->serviceA(x, y, z);
}
// etc.
};
Internally, the client's constructor creates a client-side remote proxy, which is commonly called a stub:
Client::Client(ServerIntf* s /* = 0 */)
{
server = (s? s: new Stub(...));
}
Stubs use IPC mechanisms such as sockets to forward client requests to server-side remote proxies, which are commonly called skeletons. A Java skeleton customizes a Java version of our server framework and implements the server interface by delegating to a real server:
class Skeleton implements ServerIntf extends Server
{
private ServerIntf server = new
RealServer();
protected SkerverSlave makeSlave(Socket
s)
{
return new SkeletonSlave(s, this);
}
public JResult serviceA(U u, V v, W w)
{
return server.serivceA(u, v, w);
}
// etc.
}
The real server simply returns computed results to its local caller, the skeleton. Therefore, the server doesn't need to depend on any special inter-process communication mechanism:
class RealServer implements ServerIntf
{
public JResult serviceA(U u, V v, W w)
{
JResult result = ...; // compute
result
return result;
}
// etc.
};
The skeleton slave handles the communication with the client's stub and invokes the appropriate methods of its master, the skeleton:
class SkeletonSlave extends ServerSlave
{
protected boolean update()
{
receive request from client;
call corresponding method of
skeleton (= master);
send result back to client;
}
// etc.
}
Remote proxies can be quite complex. In our example, the message sent from the stub to the skeleton includes the name of the requested service, "serviceA," and the parameters: x, y, and z. Of course x, y, and z need not be strings. They might be C++ numbers (in which case the stub will need to converted them into strings by inserting them into string streams) or they might be arbitrary C++ objects (in which case the stub will need to serialize them using the techniques of Chapter 5). This process is called marshalling.
The problem is even more complicated in our example because the server implementation is apparently a Java object, not a C++ object. Thus, after the skeleton deserializes x, y, and z, it will have to translate them into Java data. For example, an ASCII string representing a C++ number will have to be converted into a Java Unicode sting, probably using Java character streams, then the Java string must be converted into a Java number. This process is called de-marshalling.
Of course the skeleton must marshal the result before sending it back to the stub, and the stub must de-marshal the result before returning it to the client.
Finally, the reader may well ask how the skeleton knows a received request is a string containing C++ parameters and therefore C++ to Java translation should be performed, or how does the stub know a received result is a string containing Java data and therefore Java to C++ translation should be performed? Remember, clients and servers are often developed independently.
One way to solve this problem is for all programmers to agree on a common object oriented language, let's call it COOL. Marshalling must include translating data from the implementation language into COOL, and de-marshalling must include translating data from COOL into the implementation language.
Of course getting programmers to agree on what COOL should be is difficult. The Object Management Group (OMG), is promoting a standard called the Interface Description Language, IDL. An IDL description of ServerIntf looks an awful lot like a C++ header file. Compilers are available that will automatically translate IDL interfaces into stubs and clients in most object oriented languages, including Java and C++. Microsoft is promoting a standard called the Component Object Model (COM). COM interfaces are objects that can be discovered by clients at runtime through a COM meta interface.
Dynamics
In the following scenario we enhance a real server by adding four proxies between it and a client. On the client side we have a cache proxy and a stub. On the server side we have a skeleton and a synchronization proxy. The stub and skeleton perform parameter marshalling and de-marshalling.

Example: A Table
Server
The Table Interface
A table allows clients to store and retrieve associations between string keys and string values:
class Table // an interface
{
public:
virtual ~Table() {}
virtual void put(string key, string
val) = 0;
virtual bool get(string key,
string& val) = 0;
virtual void rem(string key) = 0;
};
Assume a table server is running. Two command clients are started in separate console windows. Each connects with the table server. Here's the interaction between client #1 and the server:
command -> put fish tuna
tuna
command -> put fruit grapes
grapes
command -> put server 135.199.227.55
135.199.227.55
command -> quit
bye
Here's the interaction between client #2 and the server. Notice that client #2 can fetch the values placed in the table by client #1:
command -> get server
result = 135.199.227.55
command -> get fish
result = tuna
command -> get fruit
result = grapes
command -> erase fruit
unrecognized command
command -> rem fruit
command -> get fruit
result = fail
command -> quit
bye
Structure
Our plan is to use remote proxies on the client and server side. In this case the implementers of the client and table server only need to communicate with local objects. All of the technical details of communicating with remote objects is encapsulated by the stub and skeleton proxies. In addition, the skeleton will use the server framework developed earlier:

A Table Server
A table server is a server in the most general sense, not in the sense of a server-derived class. It is simply an adapter that adapts STL maps to the expected Table interface. We use the find() function defined in util.h to search the map:
class TableServer: public Table // adapter
{
public:
void put(string key, string val) {
table[key] = val; }
bool get(string key, string& val)
{
return find(key, val, table);
}
void rem(string key) {
table.erase(key); }
private:
map<string, string> table; //
adaptee
};
A Synchronization
Proxy
Many clients may attempt to access the table server concurrently, therefore we need to place a synchronization proxy in front of the table server:
class SynchProxy: public Table
{
public:
SynchProxy(Table* t = 0)
{
table = t? t: new TableServer();
}
void put(string key, string val)
{
myLock.lock();
table->put(key, val);
myLock.unlock();
}
bool get(string key, string& val)
{
myLock.lock();
bool result = table->get(key,
val);
myLock.unlock();
return result;
}
void rem(string key)
{
myLock.lock();
table->rem(key);
myLock.unlock();
}
private:
Table* table;
Lock myLock;
};
The only indication that a synchronization proxy delegates to a table server and not another proxy occurs in the constructor, where a table server object is created if an alternative isn't specified.
Skeletons:
Server-Side Remote Proxies
A server-side remote proxy is simply a server that implements the Table interface by delegating to a table server or proxy:
class TableSkeleton: public Server, public Table
{
public:
TableSkeleton(Table* t = 0, int port =
6001): Server(port)
{
table = t? t: new TableServer();
}
void put(string key, string val) {
table->put(key, val); }
bool get(string key, string& val)
{
return table->get(key, val);
}
void rem(string key) { table->rem(key);
}
ServerSlave* makeSlave(Socket* cs)
{
return new SkeletonSlave(cs, this);
}
private:
Table* table;
};
Creating and starting a delegation chain consisting of a table skeleton, a synchronization proxy, and a table server might be done in main() as follows:
Server* s = new TableSkeleton(new SynchProxy());
s->listen();
Recall that the synchronization proxy's default constructor automatically creates a TableServer object.
The Skeleton's
Slave
A skeleton slave is simply a special type of command slave:
class SkeletonSlave: public CommandSlave
{
public:
SkeletonSlave(Socket* cs, Server* m):
CommandSlave(cs, m) {}
string execute(string cmmd);
};
A skeleton slave's execute() function receives commands of the form:
put KEY VALUE
get KEY
rem KEY
After identifying the type of command, execute() calls the corresponding member function of its master, the skeleton. In this context the master is viewed not as a server, but as a table. Generally speaking, it is necessary for skeletons to implement the server interface, because their slaves are the clients of this interface.
string SkeletonSlave::execute(string cmmd)
{
TableSkeleton* table = (TableSkeleton*)
master;
istringstream tokens(cmmd); // string
-> stream
string op, key, val, done =
"done";
tokens >> op; // = put, get, rem,
???
if (op == "put")
{
tokens >> key;
tokens >> val;
table->put(key, val);
return done;
}
else if (op == "get")
{
tokens >> key;
bool found = false;
found = table->get(key, val);
if (found) return val;
return
"fail";
}
else if (op == "rem")
{
tokens >> key;
table->rem(key);
return done;
}
else
return "unrecognized";
}
Our implementation of execute() sacrifices abstraction at the altar of efficiency. Ideally, we might like to keep the slave in the dark about the implementation of the table interface that it uses. This might be accomplished by casting the master pointer to a Table pointer rather than a TableSkeleton pointer:
Table* table = (Table*) master; // this fails
After all, master does indeed point to an object that implements the Table interface. Unfortunately, master is typed as a Server pointer, and Table is not derived from Server, nor is Server derived from Table. In other words, this cast is neither an upcast nor a downcast, so the compiler won't allow it.
We could attempt a downcast followed by an upcast:
Table* table = (Table*) ((TableSkeleton*) master);
This works, but it doesn't provide the layer of abstraction that we seek, because the execute() function still contains an explicit reference to the TableSkeleton class.
To achieve what we want, we must perform a cross cast. (See Programming Note A.7 in Appendix 1.) Cross casting must be done using the dynamic cast operator:
Table* table = dynamic_cast<Table*>(master);
Of course the dynamic cast operator uses the runtime type information (RTTI) feature of C++, which makes our code bigger and slower.
A Table Client
Our table client encapsulates a pointer to a local table implementation:
class TableClient
{
public:
TableClient(Table* t = 0) { table = (t?
t: new TableStub()); }
~TableClient() { delete table; }
void controlLoop();
protected:
Table* table;
};
The client's control loop perpetually prompts the user, reads a command, then asks its table to execute the corresponding function:
void TableClient::controlLoop()
{
bool more = true;
string cmmd, key, val;
while(more)
{
cout << "command ->
";
cin >> cmmd;
try
{
if (cmmd == "quit")
more = false;
else if (cmmd == "put")
{
cin >> key >> val;
table->put(key, val);
cout << val <<
endl;
}
else if (cmmd == "get")
{
cin >> key;
if (table->get(key, val))
cout << "result
= " << val << endl;
else
cout << "result
= fail\n";
}
else if (cmmd == "rem")
{
cin >> key;
table->rem(key);
}
else
{
cout <<
"unrecognized command\n";
cin.sync();
}
}
catch(runtime_error e) {
error(e.what()); }
} // while
cout << "bye\n";
}
Stubs: Client-Side Remote Proxies
Our client's local table server is actually a client-side remote proxy called a stub:
class TableStub: public Table
{
public:
TableStub(string serverLoc =
"localhost",
int serverPort = 6001);
~TableStub();
void put(string key, string val);
bool get(string key, string& val);
void rem(string key);
protected:
Socket* server;
};
The stub's constructor attempts to create a connection to a specified server:
TableStub::TableStub(string serverLoc, int serverPort)
{
try { server = new Socket(serverPort,
serverLoc); }
catch(SocketException e) {
error(e.what()); }
}
The destructor sends a quit message to the server, then deletes its socket:
TableStub::~TableStub()
{
server->send("quit");
delete server;
}
Recall that the table client extracted command arguments from cin so they could be passed to the stub's member functions. Internally, these member functions undo the work of the client by reuniting these arguments with their operator using string concatenation. The resurrected command string is sent to the server, then the stub patiently waits for a reply:
void TableStub::put(string key, string val)
{
try
{
server->send("put " +
key + ' ' + val);
string result =
server->receive();
}
catch(SocketException e) {
error(e.what()); }
}
bool TableStub::get(string key, string& val)
{
try
{
server->send("get " +
key);
string result =
server->receive();
if (result == "fail")
return false;
val = result;
return true;
}
catch(SocketException e) {
error(e.what()); }
}
void TableStub::rem(string key)
{
try
{
server->send("rem " +
key);
string result =
server->receive();
}
catch(SocketException e) {
error(e.what()); }
}
We create and start a client in main()with two lines:
TableClient* t = new TableClient();
t->controlLoop();
Recall that the default client constructor automatically constructs a stub.
The definitions of TableStub and TableSkeleton are tedious but routine. It should seem plausible that skeleton and stub definitions could be automatically generated from the server's interface. (CORBA and Java RMI provide such code generators). Such a tool almost completely hides the underlying communication technology from programmers. Of course, the client still needs to provide the server's address to the stub's constructor.
Brokers
Messages are carried across networks using prescribed formatting and addressing protocols. The Socket API partially hides these details from programmers. We can complete the cover up by abstracting the network into an object called a message broker. A message broker is like a virtual network. It provides a name resolution service to hide network-dependent addresses, and it provides functions for sending and receiving messages.
There are many kinds of brokers that allow us to create interesting types of network services. A call back broker is similar to a publisher. It allows subscribers to register functions that should be called when a certain type of message for the subscriber is received by the broker. This is similar to the event manager discussed in the problem section of Chapter 2. Recall that an event manager is a notification mechanism that calls a registered subscriber function when a certain type of event occurs.
Technically, a dispatcher isn't really a broker, it is simply a name server similar to the table server implemented earlier, only it stores associations between names of servers and their current locations. A location might be a pointer, OID, IP address, port number, or URL. A dispatcher is comparable to the white pages in a telephone directory— a client that knows the name of a server, but not its location, so it asks a dispatcher to look up the location. After that, it's up to the client to establish a connection to the server. Port mapper daemons and domain name servers are examples of dispatchers.
If a dispatcher is analogous to the white pages of a telephone directory, then a trader system is analogous to the yellow pages. A client knows the name of the service it wants performed, so it contacts a trader system to get the location of a convenient server that currently provides this service. "Convenient" might mean "nearby" or "not busy".
Here is the basic Broker design pattern:
Broker [POSA], [Go4]
Other names
Object request broker, ORB, ORB Architecture. Brokers are similar to mediators, dispatchers, message pumps, component containers.
Problem
A client needs to communicate with multiple servers. Server locations can change. Server implementation languages are unknown. We also want to avoid dependence on a particular IPC mechanism.
Solution
A broker is the software-equivalent of a bus or the transport layer of a network. Correspondent's (which are analogous to ICs or host nodes) can use a broker to send and receive messages. The broker provides a naming service, so correspondents can refer to each other by name rather than location. The broker hides the IPC mechanism from correspondents. We can use remote broker proxies to hide language differences.
Structure
An in-process broker is used to pass messages between local objects:

For example, every MFC program is driven by a controller called theApp:
CWinApp theApp;
This controller is essentially an active message broker (see Problem 7.11). It perpetually monitors a message queue. When a message arrives, theApp extracts it and forwards it to its target. This design is useful for communication between threads. It also promotes looser coupling between objects.
An out-of-process broker might use remote proxies to create the illusion that each correspondent has an in-process broker implemented in the correspondent's language:

ORB architectures such as CORBA and Java RMI combine brokers with remote server proxies:

Brokers may also use the Chain of Command design pattern to forward messages to other brokers. For example, each computer on a network may have a broker that knows about all servers running on its machine. Requests for other servers are forwarded to a broker running on another machine according to some routing algorithm. (See Problem 7.13.)
A Simple Message
Passing Broker
Our message passing broker is basically a post office: senders drop messages off, receivers pick messages up. We can turn it into a message broker server by placing a remote proxy in front of it. This idea is explored in Problem 7.9. Turning it into an active broker that delivers messages to their targets is explored in Problem 7.11. We can also extend it with derived classes to create call back brokers (Problem 7.10) and trader systems (Problem 7.14).
Our message broker maintains a table of mailboxes indexed by the names of their owners. The subscribe() and unsubscribe() member functions allow servers to create and delete entries in this table:
class Broker
{
public:
void subscribe(string peer) {
boxes[peer] = new MailBox(); }
void unsubscribe(string peer)
{
delete boxes[peer];
boxes.erase(peer);
}
bool post(Message msg);
bool receive(string name, Message&
msg);
protected:
map<string, MailBox* > boxes;
};
The post() function uses the find() function defined in util.h (see Appendix 3) to determine if a given message's destination owns a mailbox. If not, false is returned, otherwise, the message is posted to the mailbox and true is returned. This form of message passing is asynchronous, because the sender doesn't wait for an acknowledgement from the recipient:
bool Broker::post(Message msg)
{
MailBox* b;
if (!find(msg.dest, b, boxes)) return
false;
b->post(msg);
return true;
}
The receive() function is non-blocking, because it returns false if there are no messages in the indicated mailbox. Otherwise, the first message found is placed in the variable indicated by the reference parameter:
bool Broker::receive(string name, Message& msg)
{
return boxes[name]->receive(msg);
}
For now, a message encapsulates the name of the destination, the name of the source, and the text of the message:
struct Message
{
string dest, // receiver
source, // sender
text; //
content
};
A mailbox encapsulates a queue of messages and a lock:
class MailBox
{
public:
void post(Message msg);
bool receive(Message& msg);
private:
queue<Message> messages;
Lock myLock;
};
At the mailbox level, the post() function performs a thread-safe push() operation on the message queue:
void MailBox::post(Message msg)
{
myLock.lock();
messages.push(msg);
myLock.unlock();
}
A mailbox's non-blocking receive() function returns false if the mailbox is empty. Otherwise, the first message is de-queued and placed in the variable indicated by the reference parameter:
bool MailBox::receive(Message& msg)
{
myLock.lock();
if (messages.empty())
{
myLock.unlock();
return false; // no mail
}
msg = messages.front();
messages.pop();
myLock.unlock();
return true;
}
Conclusion
We began this chapter with a discussion of threads, locks, and the Master-Slave design pattern. This was the architecture we subsequently used for our server framework, which we subsequently specialized into the command server framework.
Our clients and servers communicated through awkward, transceiver-like devices called sockets. We were able to hide sockets inside remote proxies on both the server side (skeletons) and the client side (stubs). Remote proxies created the illusion that clients and servers were communicating using ordinary method call and return mechanisms. By introducing brokers we were able to further decouple clients from servers. Now clients only needed to know the name of a server, not its location.
Remote method invocation completes the merger of object-oriented programming with client-server programming, the two great programming paradigms of the 1990s. By adding a sophisticated persistence mechanism such as an object-oriented database, the location of an object (local, remote, or in storage) becomes irrelevant.
Programming Notes
Programming Note
7.1: Implementing Threads
The System
Interface
We can mitigate platform dependence to a large extent by introducing a system interface that declares common system services. Of course the implementation of the interface will vary from one platform to the next, but applications that depend on the interface will be platform independent.

More concretely, when an application begins, it instantiates the System implementation class. A pointer to this instance is assigned to a public, static System member variable:
ifdef WINDOWS
System* System::impl = new
Win32System();
endif
ifdef UNIX
System* System::impl = new
UNIXSystem();
endif
ifdef MAC
System* System::impl = new MACSystem();
endif
Application functions can request platform services by delegating to the implementation pointer:
System::impl->serviceX();
System::impl->serviceY();
System::impl->serviceZ();
System Threads
Of course the System interface will require implementers to provide basic functions for creating, running, and stopping threads. Typically, these services will be implemented by the underlying system's thread manager. Like most resource managers, the thread manager probably won't allow clients to directly access the threads it manages. Instead, clients will refer to these threads using some form of object identifiers (OIDs) supplied by the thread manager. To be as general as possible, we define thread OIDs to be void pointers:
typedef void* ThreadOID;
The System interface specifies a thread factory method that creates a thread and returns its corresponding OID. Subsequently, clients will use this OID to refer to the thread:
class System
{
public:
// thread stuff:
virtual ThreadOID makeThread(Thread*
thread) = 0;
virtual void resume(ThreadOID oid) = 0;
virtual void suspend(ThreadOID oid) =
0;
virtual void sleep(int ms) = 0;
// etc.
static System* impl; // THE
implementation
};
Implementing the
Thread Class
Starting a thread sets its state to RUNNING and initializes the thread peer member by calling makeThread(). Notice that the lifetime of an application-level thread does not correspond to the lifetime of its associated system-level thread. The system-level thread is created by the call to start(), which must have an implicit parameter that points to an application-level thread that already exists:
inline void Thread::start()
{
if (System::impl && state ==
READY)
{
state = RUNNING;
peer =
System::impl->makeThread(this);
}
}
Most Thread member functions manage the thread's state and delegate to the appropriate system implementation member function (this is just another instance of the Handle-Body pattern):
inline void Thread::suspend()
{
if (System::impl && state ==
RUNNING)
{
state = BLOCKED;
System::impl->suspend(peer);
}
}
inline void Thread::resume()
{
if (System::impl && state ==
BLOCKED)
{
state = RUNNING;
System::impl->resume(peer);
}
}
inline void Thread::sleep(int ms)
{
if (System::impl && state ==
RUNNING)
{
state = BLOCKED;
System::impl->sleep(ms);
state = RUNNING;
}
}
inline void stop() { state = TERMINATED; }
Programming Note
7.2: Implementing Locks
When a thread attempts to lock a locking mechanism such as a semaphore or mutex, several things must happen. If the lock is in an unlocked state, then it must be put into a locked state. If the lock is already in a locked state, then the thread must be blocked and placed on a queue associated with the lock. Furthermore, the lock() operation must be indivisible. This means interrupts must be disabled while the operation is in progress. (Why?)
Because locks have special needs, we will require implementations of our System interface to provide methods for creating, locking, and unlocking locks. Naturally, locks will be managed by the operating system. At the application level locks will be identified by a special object identifier:
typedef void* LockOID;
This identifier is returned by the lock factory method. Subsequent lock operations will use this identifier to refer to the lock:
class System
{
public:
// lock stuff:
virtual LockOID makeLock() = 0;
virtual void lock(LockOID oid) = 0;
virtual void unlock(LockOID oid) = 0;
// etc.
};
Instances of the Lock class encapsulates the lock oid, which is initialized by the constructor. Lock member functions delegate to the system-level lock through this identifier:
class Lock
{
public:
Lock()
{
if (System::impl) peer =
System::impl->makeLock();
}
void lock()
{
if (System::impl)
System::impl->lock(peer);
}
void unlock()
{
if (System::impl)
System::impl->unlock(peer);
}
private:
LockOID peer;
};
Programming Note
7.3: System Exceptions
A lot can go wrong when we request a platform service: requested files may be missing or locked, network connections may go down, applications may attempt to start a thread that doesn't exist or lock a lock that doesn't exist. We can create a hierarchy of exceptions to report these situations:
class SysException: public runtime_error
{
public:
SysException(string gripe =
"system error")
:runtime_error(gripe)
{}
};
class ThreadException: public SysException
{
public:
ThreadException(string gripe =
"thread error")
:SysException(gripe)
{}
};
class LockException: public SysException
{
public:
LockException(string gripe = "lock
error")
:SysException(gripe)
{}
};
class SockException: public SysException
{
public:
SockException(string gripe =
"socket error")
:SysException(gripe)
{}
};
Programming Note 7.4:
An MS Windows Implementation of System
All Windows platforms must implement the Win32 API, which, fortunately, includes a good supply of C functions for manipulating threads and locks. These functions are declared in:
#include <windows.h>
Here is our implementation:
class Win32System: public System
{
public:
// thread stuff:
ThreadOID makeThread(Thread* thread);
void resume(ThreadOID oid)
{
if (ResumeThread(oid) < 0)
throw ThreadException("can't
resume thread");
}
void suspend(ThreadOID oid)
{
if (SuspendThread(oid) < 0)
throw ThreadException("can't
suspend thread");
}
void sleep(int ms) { Sleep(ms); }
// lock stuff:
LockOID makeLock();
void lock(LockOID oid);
void unlock(LockOID);
//etc.
};
Win32System::makeThread() feeds the required arguments to the global, Win32 API CreateThread() function, which returns the OID of the thread it creates:
ThreadOID Win32System::makeThread(Thread* thread)
{
unsigned long threadID; // not used
ThreadOID oid =
CreateThread(
0, // default thread attributes
0, // default stack size
(LPTHREAD_START_ROUTINE) // barf!
threadStarter, // run this in
thread
thread, // starter param
0, // creation flags
&threadID); // thread id
if (!oid)
throw ThreadException("can't
create thread");
return oid;
};
A Windows thread begins executing as soon as it's created. But what does it execute? The third argument passed to CreateThread() is a pointer to the function that is executed by the created thread. This function can't be any type of function. It must be a function of type LPTHREAD_START_ROUTINE, basically, any function that expects a void pointer as input and returns an unsigned long as output.
Every thread we create will execute our global threadStarter() function. But the void* argument passed to this function will always be a pointer to a Thread. Internally, threadStart() calls this thread's run() member function:
unsigned long threadStarter(void* threadObj)
{
Thread* thread = (Thread*) threadObj;
thread->run();
return 0;
}
Locking Methods
The Win32 API provides a variety of synchronization objects including critical sections, mutexes, and semaphores. Our locks are based on mutexes:
Win32System::makeLock() calls feeds the appropriate arguments to the global, Win32 API CreateMutex() function:
LockOID Win32System::makeLock()
{
LockOID oid =
CreateMutex
(
0, // No security attributes
false, // Initially not owned
"Lock"); // Name of mutex
if (!oid)
throw LockException("can't
create lock");
return oid;
}
Win32System::lock() passes the oid returned by CreateMutex() to the global, Win32 API WaitForSingleObject() function. This will cause the caller to suspend either until the mutex is unlocked, or until an INFINITE amount of time elapses:
void Win32System::lock(LockOID oid)
{
unsigned long status =
WaitForSingleObject(oid,
INFINITE);
switch (status)
{
case WAIT_OBJECT_0:
// everything's okay
break;
case WAIT_TIMEOUT:
throw LockException("timed
out");
case WAIT_ABANDONED:
throw LockException("mutex
abandoned");
}
}
Win32System::unlock() passes the oid returned by CreateMutex() to the global, Win32 API ReleaseMutex() function to unlock the associated mutex:
void Win32System::unlock(LockOID oid)
{
if (!ReleaseMutex(oid))
throw LockException("can't
release mutex");
}
Programming Note
7.5 Implementing Sockets
Fortunately, there are only minor variations in the implementation of the Socket API from one platform to the next. We can manage the differences in the Windows and UNIX implementations using global identifiers UNIX and WINDOWS, that are defined or undefined in our socket header file:
// socket.h
#ifndef SOCK_H
#define SOCK_H
#ifndef UNIX
#define WINDOWS
#include <windows.h>
#else // UNIX includes
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#endif
#include <iostream>
#include <string>
#include <stdexcept>
using namespace std;
#define PacketSize 125
typedef char Packet[PacketSize];
typedef SOCKET SocketOID;
class Socket { ... };
#endif
Note: On Windows platforms the oldnames.lib and ws2_32.lib libraries need to be linked into programs that use sockets.
send() and
receive()
The Socket::send() function invokes the global send() function from the Socket API:
void Socket::send(string msg)
{
int status =
::send(peer, msg.c_str(), msg.size(), 0);
if (status == SOCKET_ERROR)
throw(SockException("send
failed"));
}
The Socket::receive() function is trickier, because we need to allocate space for the received message without knowing how long it will be. In socket.h we arbitrarily defined a packet to be an array of 125 characters:
#define PacketSize 125
typedef char Packet[PacketSize];
Socket::receive() uses the global recv() function from the Socket API to fill a packet, p, with received characters. The packet is converted into a C++ string and returned to the caller:
string Socket::receive()
{
Packet p;
int bytes // # of bytes received
= recv(peer, p, PacketSize, 0);
if (bytes == SOCKET_ERROR)
throw(SockException("receive
failed"));
string msg(p, bytes);
return msg;
}
The Socket destructor uses the global closesocket() function from the Socket API to close the socket:
Socket::~Socket() { closesocket(peer); }
Socket::Socket()
The Socket constructor is messy. The steps are:
1. Using the IP address or DNS name of the server that we want to connect to, create a "host entry" system level object.
2. Using the host entry from step 1 and the port number of the server, create a "server location" system level object.
3. Create a system level socket object with the desired protocol (UDP, TCP, etc.). This object will be the peer of the application level socket object created by the constructor.
4. Connect the system level socket object to the system level server location object.
Here's our implementation:
Socket::Socket(int port, string name)
{
int status;
#ifdef WINDOWS
WSADATA wsaData;
status =
WSAStartup(0x202,&wsaData);
if (status == SOCKET_ERROR)
throw(SockException("WSAStartup()
failed"));
#endif
// create a host entry object
hostent*
hp = 0; // host entry pointer
if (isalpha(name[0])) // convert domain
name
hp = gethostbyname(name.c_str());
else
{ //
convert IP address
int addr = inet_addr(name.c_str());
hp = gethostbyaddr((char
*)&addr, sizeof(&addr), AF_INET);
}
if (!hp)
throw(SockException("gethostbyxxx()
failed"));
// create a location object
sockaddr_in
serverLoc; // IP address & port
of server
memset(&serverLoc, 0,
sizeof(serverLoc));
memcpy(&(serverLoc.sin_addr),
hp->h_addr, hp->h_length);
serverLoc.sin_family =
hp->h_addrtype;
serverLoc.sin_port = htons(port);
// get a socket oid
int protoFamily = AF_INET; // TCP/IP
int qos = SOCK_STREAM; // reliable
& connection-oriented
int protocol = 0;
peer
= socket(protoFamily, qos, protocol);
if (peer < 0)
throw(SockException("socket()
failed"));
// connect to server
status =
connect(peer,
(sockaddr*)&serverLoc, sizeof(serverLoc));
if (status == SOCKET_ERROR)
throw(SockException("connect()
failed"));
}
Programming Note
7.6: Servers
Programming Note
7.6.1: Implementing the Server Constructor
Servers communicate through a special type of system-level socket called a server socket. We begin by creating a system-level "server location" object from the specified port number. (The IP address is implicitly understood to be the IP address of the machine that creates the server socket.) Next, we create a system-level socket that realizes a given protocol (TCP in our case). Finally, instead of connecting the socket to the location, we bind the socket to the location using the Socket API bind() function:
Server::Server(int port)
{
int status;
#ifdef WINDOWS
WSADATA wsaData;
status =
WSAStartup(0x202,&wsaData);
if (status == SOCKET_ERROR)
throw(SockException("Startup()
failed"));
#endif
int protoFamily = AF_INET; // TCP/IP
int qos = SOCK_STREAM; // reliable
& connection-oriented
int protocol = 0;
sockaddr_in
serverLoc;
memset(&serverLoc, 0,
sizeof(serverLoc));
serverLoc.sin_family = protoFamily;
serverLoc.sin_addr.s_addr = INADDR_ANY;
serverLoc.sin_port = htons(port);
// creating descriptor
peer
= socket(protoFamily, qos, protocol);
if (peer == INVALID_SOCKET)
throw(SockException("socket()
failed"));
// binding
status =
bind(peer,
(sockaddr*)&serverLoc, sizeof(serverLoc));
if (status == SOCKET_ERROR)
throw(SockException("bind()
failed"));
}
Programming Note
7.6.2: Implementing Server::listen()
Server::listen() calls the global listen() function from the Socket API. This function associates a request queue with the server socket. The request queue holds pending client requests waiting for service. Each time through the while loop the server extracts a client request from this queue and creates a server-side socket connected to the client side socket. All of this is accomplished by calling the global accept() function from the Socket API. If the request queue is empty, then accept() blocks the server until a request arrives.
The socket created by the call to accept(), together with a pointer to the server, is passed to the virtual factor method that creates slave threads. The slave is started, and the loop repeats.
void Server::listen()
{
bool more = true;
sockaddr_in from;
int fromlen = sizeof(from);
int queueSize = 5;
int status = ::listen(peer, queueSize);
if (status == SOCKET_ERROR)
throw(SockException("listen()
failed"));
while(more)
{
cout << "\nthe server is
listening ... \n";
SOCKET client;
client
= accept(peer, (sockaddr*)&from, &fromlen);
if (client == INVALID_SOCKET)
throw(SockException("accept()
failed"));
cout << "\n\nconnection
accepted!\n";
cout << "client IP = " << inet_ntoa(from.sin_addr)
<< endl;
cout << "client port =
" << htons(from.sin_port) << "\n\n";
ServerSlave* slave = makeSlave(new
Socket(client), this);
slave->start();
}
cout << "The server is
shutting down!\n";
}
Problems
7.1 Problem
Let P(m) be the statement:
For all n > 0 and for all k > 0, it takes k * (n + m – 1) steps to process a length m sequence of messages by a length n pipeline, assuming each filter in the pipeline is active, runs on its own processor, and processes a single message in k steps.
Prove that P(1) is true.
Assuming P(m – 1) is true, prove that P(m) is true.
By mathematical induction you may now conclude that P(m) is true for all m > 0.
How would the theorem change if the n filters shared r processors, where 0 < r < n?
7.2 Problem
Review the data-driven pipeline example presented in Chapter 2. (The demand-driven version was presented in problem 2.11.) Redo the example using active filters. You will need to derive Pipe from queue<Msg> so that pipes can hold multiple messages. You will also need to derive Filter from Thread. Of course you won't need to use the Publisher-Subscriber pattern. One problem that needs to be solved is how to shut the pipeline off when the producer runs out of data. In this case each filter needs to be stopped by an external agent. If we regard the filters as slaves and the pipeline as the master, then the producer can inform the master when it runs out of data, and the master can shut down all of the other filters.
7.3 Problem
A calculator slave is a special type of command slave that executes arithmetic commands of the form:
CMMD ::= OPERATOR EXP EXP | define NAME EXP
where:
OPERATOR ::= add | mul | div | sub
EXP ::= NAME | NUMBER
NAME ::= any alpha-numeric string
NUMBER ::= any double
The result of executing an operator command is a number. (Of course division by 0 is illegal.) Executing a define command creates an entry in a table maintained by the slave. The entry binds NAME to the numeric result of executing EXP. This table is used to look up the numbers represented by names.
Implement and test a command server that executes arithmetic commands submitted by clients.
7.4 Problem: A Chat
Room
A chat room consists of an array of recent contributions and a list of contributor pseudonyms. A contribution is simply a contributor pseudonym followed by a message (i.e., a C++ string) typed by the contributor:
Zorro says: Hello everybody.
A chat room server manages a chat room. A contributor uses a chat room client to connect with a chat room server. Once connected, the contributor's pseudonym is added to the chat room's pseudonym list. Now the contributor may type and send messages that the server will post at the end of the recent contributions array. The contributor may also ask to see the recent contributions. (Note: in this version the contributor must explicitly ask to see the recent contributions. An improvement would be to have the client display recent contributions each time the chat room was updated.)
Implement and test a chat room client and server by customizing the command client and command server described in this chapter.
7.5 Problem:
Distributed Producers and Consumers
Redo the shared bank account example, only this time process boundaries separate the bank account, withdrawer, and depositor. The Account class should be a type of command server that accepts commands such as "withdraw 20" and "deposit 60", and the withdrawer and depositor should be command clients.
7.6 Problem:
Distributed Producers and Consumers using RMI
Redo the previous problem, only this time using the original Account, Depositor, and Withdrawer classes. (Use the first Account class that didn't have a lock.) Instead of pointers to a real account, the depositor and withdrawer are given pointers to account stubs that are connected to an account skeleton running in a different process. The account skeleton delegates to a synchronization proxy that delegates to the account.
7.7 Problem:
Protection Proxies
Add a protection proxy between the synchronization proxy and the skeleton in the previous problem. The protection proxy simply adds a password parameter to the withdraw() and deposit() functions. The password itself is a member variable of the protection proxy. Of course this will force changes to the stub, skeleton, withdrawer, and depositor as they will now need to supply an additional password argument to their calls to withdraw() and deposit().
7.8 Problem: Remote
Event Notification
Redo the nuclear reactor example from Chapter 2, only this time assume sensors (alarms, thermostats, thermometers, etc.) and the reactor are separated by process boundaries. (This is a better simulation of a real power plant in which sensors and the reactor are controlled by embedded processors that communicate over a network.) Use remote proxies to shelter the original reactor and sensor code from the underlying communication technology.
For example, the reactor's incTemp() function— which is called from the control console— calls the notify() function inherited from the publisher base class. The notify() function calls the update() function of each registered sensor, only the sensors are actually subscriber stubs connected to remote subscriber skeletons. A subscriber skeleton ultimately calls the update() function of an associated sensor.
A sensor needs to learn and perhaps lower the temperature of its associated reactor. In fact, the associated reactor is actually a reactor stub connected to a reactor skeleton, which is associated with the actual reactor:

Notice that Reactor, ReactorSkeleton, and ReactorStub realize the ReactorIntf interface, which extends the PublisherIntf interface. Also notice that only the functions that are actually needed by sensors appear in this extended interface, hence notify() and incTemp() do not appear in ReactorIntf. Also note that ReactorSkeleton::subscribe() is tricky, because an appropriate subscriber stub must be created and added to the list of subscribers inherited by the Reactor class. You may simplify the problem by assuming that update() and decTemp() are parameterless, and by restricting sensors to printing alarms.
Remote event notification is an important service because "devices" and their "monitors" are often separated by machine boundaries. While polling is possible in this situation, if the device doesn't change state often, then polling generates a lot of unnecessary network traffic.
7.9 Problem: A
Message Broker Server
Redefine the Broker class so that it implements the broker interface:
class BrokerIntf // interface
{
public:
virtual void subscribe(string peer) = 0;
virtual void unsubscribe(string peer) =
0;
virtual bool post(Message msg) = 0;
virtual bool receive(string name,
Message& msg) = 0;
};
Following the example of the Table server, create a broker stub and skeleton that also implement the broker interface. The skeleton also specializes the Server class defined in the text:
class BrokerSkeleton: public Server, public BrokerIntf
{
BrokerIntf* myBroker;
// etc.
};
The skeleton implements the broker interface by delegating to an instance of the broker class:
myBroker = new Broker();
The skeleton creates command slaves that respond to commands issued by broker stubs of the form:
subscribe DESTINATION
unsubscribe DESTINATION
post DESTINATION SOURCE TEXT
receive DESTINATION
where DESTINATION, SOURCE, and TEXT are arbitrary C++ strings that don't contain white space.
Test your implementation by creating seekers and oracles. A seeker is similar to a command client. It prompts the user for the name of an oracle and a "question". The seeker uses a message broker stub to post the question to the indicated oracle, then repeatedly calls the stub's receive() function until an "answer" arrives. An oracle is similar to a table server. It perpetually calls the receive() function of a broker stub. When a question arrives, the broker looks up the "answer" in an easily customized table, and sends it back to the seeker.
7.10 Problem:
Call-Back Brokers
Message targets are similar to the controllers discussed in Chapter 6:
class Target // interface
{
public:
virtual string handle(Message msg) = 0;
};
A call back broker maintains a table that associates names and target pointers:
map<string, Target*> targets;
A call back broker implements a function of the form:
string CBBroker::send(string target, Message msg);
This function searches the targets table for the address of the indicated target, then passes the message by calling the target's handle() function:
return targets[target]->handle(msg);
If the indicated target is not registered, then send() returns "fail". The handle() function may return a string indicating its "response" to the message.
In effect, the call back broker's send() function implements a synchronous message passing service, because the sender blocks until the call to send() returns. This only happens when the call to handle() returns.
Implement CBBroker by specializing the Broker class:
class CBBroker: public Broker { ... };
Thus, CBBroker instances provide synchronous and asynchronous message delivery services.
7.11 Problem:
Active Message Brokers
The message broker implemented in the text is passive. It is the job of clients and servers to post and receive messages by calling the broker's member functions. By contrast, an active broker executes a control loop that perpetually monitors a message queue. When a message arrives (placed there by a client thread), the broker either delivers the message immediately (by passing it to the target's handle() function) or places the message into the recipient's mail box. Create an active broker as a derived class of the CBBroker class described earlier:
class ActiveBroker: public CBBroker { ... };
7.12 Problem
The call back broker is somewhat limited because each target must provide a function called handle(). How could we generalize the call back broker to allow targets to specify which of their member functions should be called when a message arrives?
7.13 Problem:
Virtual Internets
An internet is a network of networks. Two networks in an internet, N1 and N2, can be connected by a router. A router is a machine that is connected to both networks. It is able to translate the format and destination address of a message from the protocol used by N1 to the protocol used by N2, and vice-versa. Additionally, when a router receives a message, M, from N1, it analyzes the destination address to determine the shortest path of networks through the internet that M must traverse in order to reach its destination. The router then forwards M to the router that connects N2 to the next network along this path, where the process is repeated.
We can form broker "internets" by equipping a message broker with a vector of pointers to neighboring brokers:
vector<BrokerIntf*> neighbors;
Next, we modify the broker's post() function to route messages that can't be delivered locally:
bool Broker::post(Message msg)
{
MailBox* b;
if (!find(msg.dest, b, boxes)) return
route(msg);
b->post(msg);
return true;
}
Where route() is a new function added to the broker interface defined in problem 7.9:
class BrokerIntf // interface
{
public:
virtual void subscribe(string peer) =
0;
virtual void unsubscribe(string peer) =
0;
virtual bool post(Message msg) = 0;
virtual bool receive(string name,
Message& msg) = 0;
virtual
bool route(Message msg) { return false; }
};
Create an implementation of this interface with a non-trivial implementation of route().
7.14 Problem:
Trader Systems
How could the call back broker developed in problem 7.10 be modified to provide a trader system service?
7.15 Problem: Slave
Pools
Recall that the command server described earlier implemented the makeSlave() factory method by invoking the CommandSlave constructor:
class CommandServer: public Server
{
public:
ServerSlave* makeSlave(Socket* cs)
{
return new CommandSlave(cs, this);
}
};
Describe how makeSlave() could be implemented by selecting the next command slave from a pool of available slaves. Remember, when a slave terminates, it must be returned to this pool.
7.16 Problem: A
Game Server
Combine the framework for two-player games discussed in problem 3.1 and the server framework for this chapter to create a framework that allows two people to play a game over the Internet. One problem you will need to solve is how long to make clients wait for an opponent to arrive.
Test your framework by customizing it into a Tic-Tac-Toe game.
7.17 Problem
Re-implement the Server framework as a template parameterized by the type of slaves it will create. Test it by creating a command server.
7.18 Problem
We defined thread and lock object identifiers as void pointers:
typedef void* ThreadOID;
typedef void* LockOID;
// etc.
These definitions anticipated a Windows implementation, because the Window's HANDLE type would automatically be converted into a void*. A better (but more complex) solution would have been to define OIDs as unsigned integers:
typedef unsigned ThreadOID;
typedef unsigned LockOID;
// etc.
Implementations of the System type could construe OIDs as indices into an array of platform specific OIDs. For example:
class Win32System: public System
{
vector<HANDLE> handles;
public:
void resume(ThreadOID oid)
{
if (ResumeThread(handles[oid]) <
0)
throw ThreadException("can't
resume thread");
}
// etc.
};
Re-implement Win32System, ThreadOID, and LockOID as suggested, and test using the Producer-Consumer problem. One problem this implementation faces is the holes created in the handles vector when OIDs are eliminated. Eventually, OIDs will get to be quite large. How can this problem be solved?
7.19 Problem:
Dining Philosophers
Five philosophers seated at a circular table in a Chinese restaurant perpetually eat and argue. Unfortunately, there is only a single chopstick between each place setting, so in order to eat, a philosopher must wait for his right neighbor to lay down his left chopstick and his left neighbor to lay down his right chopstick.
Represent each philosopher as a thread with an update function of the form:
bool Philosopher::update()
{
if (chopsticks are available)
grab them and eat;
else
argue;
}
Figure out a way that no matter how long the program runs, no philosopher starves to death.
7.20 Problem
Add a cache proxy between the table client and the table stub.
7.21 Problem
Modify the table server so that the table holds associations between names of people and Person objects (use the definition of Person and Address from Chapter 5). The skeleton slave will need to serialize the person objects returned to it by its master, the table skeleton, using the techniques of Chapter 5 before sending them through the socket to the client. On the client side, the stub will need to deserialize the strings received from the server before returning them as Person objects to the client.