4
Delegation
4.1
Overview
A programming language is a toolkit containing tools designed to solve different types of problems. Of course no toolkit provides a tool for every occasion. When these occasions arise we need to improvise, perhaps by using available tools but in an unusual way. We see the same phenomenon in natural language. New concepts arise for which we lack words. Old words are pressed into service, but with cool new meanings that squares don't often dig. Over time these improvisations become institutionalized, and we call them idioms: words and phrases used in ways that differ from their original meanings. Following this idea, programmers refer to their institutionalized improvisations as programming idioms. Since programming idioms are language-specific, we can also think of them as implementation patterns.
Inheritance is the primary reuse mechanism provided by C++ and Java. It allows programmers to create a new class from an existing class. New features can be added to the new class and inherited features can be modified. But what if we want to add or modify the features of an existing object? Neither C++ nor Java provides an object-level reuse mechanism. Over the years programming idioms have evolved that formalize tricks programmers use to solve this problem. Most of these tricks are based on the idea of delegation: one object forwards client requests to a second object, which is hidden from the client's view. The forwarding object can add or modify the behavior seen by the client.
The chapter introduces delegation through four design patterns: State, Adapter, Strategy, and Decorator. Unfortunately, memory management can be an issue in C++ programs that use delegation. We introduce the Canonical Form Pattern to solve these problems. Smart Pointers, Vectors, Virtual Bodies, and Reference Counting are provided as examples that use Canonical Form.
4.2
Delegation
Generally speaking, a handle-body pair is a pair of objects collaborating to appear to the client as a single object. One object, called the handle, manages the interface with the client, while another object, called the body, provides all or some of the application logic.
![]()
Here is an idealized outline of a handle-body declaration:
class Body
{ // no client access, handles only!
friend class Handle;
void serviceA();
void serviceB();
// etc.
};
class Handle
{
public:
Handle(Body* b = 0) { myBody = b? b:
new Body(); }
void serviceA() { if (myBody)
myBody->serviceA(); }
void serviceB() { if (myBody)
myBody->serviceB(); }
// etc.
private:
Body* myBody;
};
Notice how the handle simply forwards the client requests to the body. This is called delegation.
The dictionary definition of delegation is:
To entrust a power or responsibility to an agent.
In our case the handle is entrusting the responsibility to perform services A, B, etc. to its agent, the body.
4.2.1 Applications
In this chapter we will discuss many design patterns that are based on delegation. State, Adapter, Strategy, Decorator, are examples of Handle-Body pairs. There are many more applications.
4.2.1.1
The
Body is a Shared Object
The body might be a shared object, such as a large CAD-CAM model or a representation of a unique resource such as an Active X control, a file, or hardware device. Although there is only a single body, there may be multiple handles, one for each client, creating the illusion that each client has its own copy of the shared object.
4.2.1.2
The
Body is a Remote Object.
In distributed client-server applications, client and server objects reside in different processes possibly running on different machines connected by a network. We want to shield client objects from the details of remote communication (sockets, IP addresses, pipes, ports, protocols, etc.) and instead allow clients to communicate with server objects (bodies) using ordinary method invocations. We can achieve this by introducing a client-side proxy (the handle) that encapsulates the low-level communication details.[1]
4.2.1.3
Division
of Labor
Sometimes the responsibilities of an object naturally divide into two categories. In these situations it is often a good idea to separate these responsibilities into two associated objects. In the Canonical Form Pattern (see below), for example, the handle performs memory management duties while the body implements application logic. In the Model-View-Controller Pattern (see Chapter 6) a view object (the handle) is responsible for displaying application data, while a model object (the body) stores and manipulates application data.
4.2.1.4
The
Body is not a C++ Object.
How do we integrate objects from other languages into a C++ program? Naturally, clients want to be shielded from the syntax and semantics of the foreign object. The idea is to encapsulate a reference to the foreign object (the body) in a C++ object called a wrapper (the handle), which also encapsulates the syntax and semantics of the body. Clients only see and use the wrapper. This technique is used in the MFC application framework. Many MFC objects are C++ objects that encapsulate references to C objects that are created, managed, and destroyed by the Windows operating system.
4.2.1.5
The
Body is a Data Structure
Object oriented programming doesn't simplify the task of implementing data structures such as linked lists or 2-3 trees. As in non object-oriented implementations, such structures are composed of many "cells" that are delicately linked together by pointers. Clients must exercise care when inserting or removing items from these structures. Often complicated re-balancing or re-linking operations are required. In many cases new cells must be allocated while old cells must be deleted.
However, object oriented programming can provide objects that encapsulate and manage these data structures. In this case we can think of the data structure as a body and the manager as a handle. A manager provides clients with member functions for inserting, removing, and retrieving items stored in the data structure, which is otherwise inaccessible to them. The complicated administrative duties that accompany inserting and removing items are automatically performed by the manager. Eventually, clients come to identify the manager with the data structure it manages. For example, STL containers such as lists and vectors are really managers of linked lists and dynamic arrays.
4.2.2 Delegation versus Inheritance
Both delegation and inheritance provide a means for a new class to use the services provided by an existing class. But how are these two mechanisms different?
Assume Job is an abstract base class that specifies a function called work():
class Job
{
public:
virtual void work() = 0;
};
Assume Carpenter, Plumber, and Electrician are three concrete classes derived from Job:
class Carpenter: public Job
{
public:
void work() { /* build a hutch */ }
};
class Electrician: public Job
{
public:
void work() { /* change a light bulb */
}
};
class Plumber: public Job
{
public:
void work() { /* plunge a toilet */ }
};
Now assume a Handyman class is to be defined. Handymen often find jobs as carpenters, so it might make sense to define Handyman as a subclass of Carpenter:
class Handyman: public Carpenter {};
Thanks to inheritance, all handymen can immediately begin sawing boards and hammering nails:
Handyman earl, gus;
earl.work(); // earl builds a hutch
gus.work(); // now gus builds a hutch
But what happens if a handyman finds work as a plumber? We could re-declare Handyman as a subclass of Plumber:
class Handyman: public Plumber {};
but then all handymen would behave like plumbers (and gus and earl would become obsolete).
We could use multiple inheritance, instead:
class Handyman: public Plumber, public Carpenter, public
Electrician
{
public:
void plunge() { Plumber::work(); }
void build() { Carpenter::work(); }
void wire() { Electrician::work(); }
};
This is a bit awkward in this example, because Handyman inherits three functions with identical signatures, but the real problem is that Handyman objects will become too bulky. For example, suppose each Job-derived class declared several tool attributes:
class Plumber: public Job
{
public:
void work() { /* plunge a toilet */ }
private: // tool kit:
Plunger myPlunger;
Wrench myWrench;
// etc.
};
This means every handyman must carry around the tools of all three professions, even though some may never find work as plumbers, while others may never find work as carpenters or an electricians.
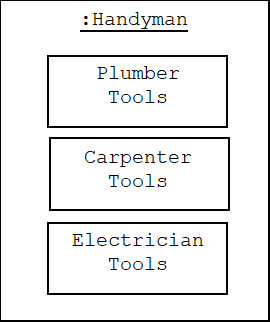
By contrast, suppose Handyman uses delegation in the form of the State Pattern. In this situation Handyman is the context, while Job is the state:
class Handyman
{
public:
Handyman(Job* j = 0) { myJob = j; }
void work() { if (myJob)
myJob->work(); }
void setJob(Job* j) { if (myJob) delete
myJob; myJob = j; }
private:
Job* myJob;
};
Note that the new Handyman class no longer needs job-specific work functions.
Now suppose we create several handymen that perform different jobs:
Handyman gus(new Electrician());
Handyman earl(new Plumber());
Although gus and earl belong to the same class, each does something different when told to get to work:
gus.work(); // gus changes
a light bulb
earl.work(); // earl plunges a toilet
We can also dynamically alter the behavior of an existing handyman:
earl.setJob(new Carpenter());
earl.work(); // now earl builds a hutch
While inheritance allows us to provide the services of a base class to all instances of a derived class, delegation allows us to provide different services to different instances of the same class. In other words, inheritance provides services at the class level, while delegation provides services at the level of individual objects.
4.3
Delegation
Styles
There are two common styles of delegation. The non-dedicated style assumes a pointer to the context will be passed to the body's member functions:
class Body
{
public:
virtual void serviceA(Context* c) = 0;
virtual void serviceB(Context* c) = 0;
virtual void serviceC(Context* c) = 0;
};
In the dedicated style the body maintains a pointer to its context:
class Body
{
public:
State(Handle* h = 0) { myHandle = h; }
virtual void serviceA();
virtual void serviceB();
virtual void serviceC();
protected:
Handle*
myHandle;
};
By declaring the handle pointer to be protected, it becomes visible to the implementations of the derived class member functions. Of course the derived class constructors must remember to call the base class constructor in their initializer lists:
class SpecialBody: public Body
{
public:
SpecialBody(Handle* h = 0): Body(h) { ... }
void serviceA();
void serviceB();
void serviceC();
};
Notice that the services no longer need a Handle* parameter. They can simply refer to their calling contexts using the inherited myHandle pointer:
void SpecialBody::serviceC()
{
// perform service C
myHandle->setState(...);
}
Notice that the dedicated style assume that a Body object is only ever the body of one Handle object, the one pointed at by the myHandle variable. We say that the Body object is dedicated to performing services for this particular Handle object.
By contrast the non-dedicated style allows for the possibility that several Handle objects could employ the services of a single Body object. From the Body object's point of view, it provides services to whichever Handle object it's argument happens to point to. It isn't dedicated to a single Handle object.
4.4
The
Delegation Operator
Inheritance-lovers never hesitate to point out that inheritance has one advantage over delegation. Assume a class has many member functions:
class Body
{
public:
void serviceA() { ... }
void serviceB() { ... }
// C, D, E, F, etc.
void serviceZ() { ... }
protected:
Handle* myHandle;
};
If a class is derived from the Body class:
class Handle: public Body { ... };
then the Body member functions are automatically inherited by the Handle. On the other hand, if the Handle delegates to the Body class, then it must implement lots of member functions that simply delegate to their counterparts in the associated body:
class Handle
{
public:
void serviceA() { if (body)
body->serviceA(); }
void serviceB() { if (body)
body->serviceB(); }
// C, D, E, F, etc.
void serviceZ() { if (body)
body->serviceZ(); }
private:
Body* body;
};
This can be a real nuisance. One way around this is the delegation operator. Instead of implementing functions corresponding to each function in the associated Body class, the Handle class simply redefines the arrow operator:
class Handle
{
public:
Body*
operator->() { return body; }
private:
Body* body;
};
Handle clients must explicitly perform the delegation by using the arrow operator instead of the dot operator:
Handle c;
c->serviceA();
c->serviceB();
// C, D, E, F, etc,
c->serviceZ();
Note that c is a Handle, not a pointer to a Handle. The compiler translates the statement
c->serviceA();
into the statement:
body->serviceA();
Using the dot operator instead of the arrow operator:
c.serviceA();
causes the compiler to complain that serviceA() is not a member function of Handle. If c is declared as a pointer to a Handle:
Handle* c = new Handle();
then using the arrow operator:
c->serviceA();
causes the same error. To perform the delegation in this case the client must first dereference c:
(*c)->serviceA();
4.5
Adapters
Have you ever fried a hair dryer or electric shaver while traveling in a foreign country? The problem is that in some countries a walloping 220 volts comes out of the outlets, while most appliances made in the US expect a meager 110 volts. There are three solutions to the problem: grow a beard and sun dry your hair, use battery powered appliances, or put an adapter (a device that turns a 220 volt input into a 110 volt output) between the foreign outlet and your hair dryer.
Programmers can also face this problem. Assume a client expects a server to conform to a specific interface. As implementers of the server, our first duty is to shop around to see if there are any servers that can be reused. Assume we find one, but that its interface doesn't quite conform to the interface expected by the client. This is analogous to the problem with the foreign electrical outlet that provides electricity, but doesn't conform to the interface expected by the electric razor. Our solution is analogous, too:
Adapter [Go4]
Other Names
Wrapper
Problem
An existing server class implements the functions required by a client, but the interface doesn't match the expected interface.
Solution
Insert an adapter between the client and the server. The adapter implements the interface required by the client by calling the corresponding server functions.
4.5.1 Static Structures
The pattern is instructive because it can be implemented using delegation or inheritance. The adapter can inherit the functions of the adaptee (i.e., the server with the wrong interface,) and call them directly:
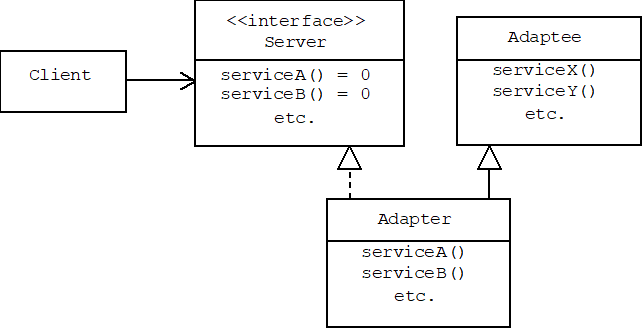
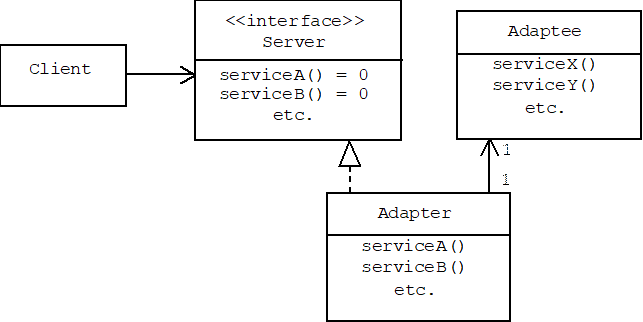
Alternatively, the adapter can access the adaptee services by delegation:
4.5.2 Implementations
Both structures assume the interface expected by the client is specified by an abstract server base class:
class Server
{
public:
virtual void serviceA() = 0;
virtual void serviceB() = 0;
// etc.
};
and the misnamed implementations are provided in the adaptee class:
class Adaptee
{
public:
void serviceX();
void serviceY();
// etc.
};
The client invokes the server's services through a pointer:
class Client
{
public:
Client(Server* s = 0) { myServer = s; }
void doSomething()
{
if (myServer)
{
myServer->serviceA();
myServer->serviceB();
// etc.
}
}
// etc.
private:
Server* myServer;
};
In the inheritance solution the adapter implements the server interface by calling the privately inherited Adaptee functions:
class Adapter: Adaptee, public Server
{
public:
void serviceA() { serviceX(); }
void serviceB() { serviceY(); }
// etc.
};
Why private inheritance? Assume some client learned that serviceX() and serviceY() could also be invoked through the myServer pointer:
void Client::doSomething()
{
((Adapter*)myServer)->serviceX(); //
Look what I discovered!
// etc.
}
Now our implementation of the Server interface can't be changed without breaking this client's code or forever continuing to support service X.
In the delegation solution the adapter implements the server interface by forwarding calls to serviceA() and serviceB() to calls to serviceX() and serviceY():
class Adapter: public Server
{
public:
Adapter(Adaptee* a = 0) { myAdaptee =
a; }
void serviceA() { if (myAdaptee)
myAdaptee->serviceX(); }
void serviceB() { if (myAdaptee)
myAdaptee->serviceY(); }
// etc.
private:
Adaptee* myAdaptee;
};
As before, the delegation method is preferred if there are different types of Adaptees that might need to be changed often or dynamically.
4.5.3 Example: MS Windows Message
Queues
Each running Microsoft Windows application (such as MS Word or MS Excel) has an associated message queue where the Windows operating system places messages such as "left mouse button down" or "arrow key pressed". Messages can also be placed there by the application's user interface controls, such as "OK button clicked" or "Save selected from File menu". The interface used by applications to manipulate and inspect their message queues looks something like this:
class MSGQueue
{
public:
virtual bool GetMessage(MSG* msg) = 0;
virtual void PostMessage(MSG* msg) = 0;
// etc.
};
where MSG is the type of all Windows messages:
struct MSG { ... };
Suppose we are trying to simulate an MS Windows message queue. How can we implement this interface? The C++ standard template library (STL) provides a queue template. Naturally, the queue doesn't have member functions called PostMessage() and GetMessage(). (In fact, whoever named the member functions must have been sleep walking, push() is used instead of enqueue() and pop() is used instead of dequeue()! No matter, only PostMessage() and GetMessage() will be useful to our clients.)
Our first implementation demonstrates the inheritance implementation of the Adapter Pattern. Instances of MSGQueueImpl1 are adapters that implement the MSGQueue interface and privately inherit from queue<MSG*> adaptees:
class MSGQueueImpl1: public MSGQueue, queue<MSG*>
{
public:
bool GetMessage(MSG* msg)
{
if (empty()) return false;
msg = front();
pop();
return true;
}
void PostMessage(MSG* msg) { push(msg); }
// etc.
};
Here's a second implementation based on the delegation solution:
class MSGQueueImpl2: public MSGQueue
{
public:
bool GetMessage(MSG* msg)
{
if (messages.empty()) return false;
msg = messages.front();
messages.pop();
return true;
}
void PostMessage(MSG* msg) { messages.push(msg); }
// etc.
private:
queue<MSG*>
messages; // the adaptee
};
4.5.4 Example: STL Adapters
STL stacks, queues, and priority queues are themselves adapters for STL lists and deques(doubly ended queues). Here is a simplified, partial declaration of the deque template; the list template is almost the same:
template <typename T>
class deque
{
public:
void push_front(const T& x); //
lists & deques only
void pop_front(); // lists & deques
only
void push_back(const T& x);
void pop_back();
T& front();
T& back();
// etc.
};
STL stacks and queues delegate client requests to a deque (the default) or list adaptee:
template <typename T, typename C = deque<T> >
class queue
{
protected:
C
c; // the adaptee
public:
void pop() { c.pop_front(); }
void push(const T& s) { c.push_back(s); }
T& front() { return c.front(); }
// etc.
};
STL vectors don't provide pop_front(), so they can't be queue adaptees. (See Programming Note A.3.1 in Appendix 1 for an overview of STL.)
4.6
Stateful
Objects
4.6.1 State and Identity
We normally identify the state of an object with the current contents of its member variables and the behavior of an object with its public member functions. Naturally, behavior depends on state.
If the state of an object can change, we say the object is stateful, otherwise we say it is stateless. Stateful objects are more difficult to use because behavior depends on state, but state can change and therefore behavior can change. Stateful objects can also raise thorny philosophical issues about identity. Is an object's identity independent of its state?
For example, the state of an object representing a bank account is the account's balance. Clearly balance can change over time. Sometimes withdrawing money from an account is successful, but sometimes we get an "insufficient funds" error. Also, the identity of the account isn't dependent on the balance. It's still our account no matter what the balance is.
By contrast, the state of an object, p, representing the two dimensional point (3, 4) is its x and y coordinate. If points are stateful, then a user might change the x-coordinate from 3 to 5. Has the identity of p changed? The answer seems to be yes. It now represents the point (5, 4).
In the case of stateless objects we often need to override the equality operator to reflect that state and identity are the same:
class Point
{
public:
bool operator==(Point other)
{
return xc == other.xc && yc
== other.yc;
}
// etc. but no mutators
private:
double xc, yc;
};
4.6.2 State Space
Not all possible states are legitimate. A class invariant is some condition that must be satisfied by a possible state before it can be considered a legitimate state. The set of all legitimate states of an object is called the object's state space.
For example, the state space for the Point class defined earlier is the product space:
double x double
However, suppose our points are points on a virtual canvas used by a graphics library. If the height and width of the virtual canvas are fixed to say 2500 pixels and 1000 pixels, respectively, then the invariant condition for class Point is:
(0 <= x < 1000) and (0 <= y < 2500)
and the state space is:
{(x, y) | (0 <= x < 1000) and (0 <= y < 2500)}
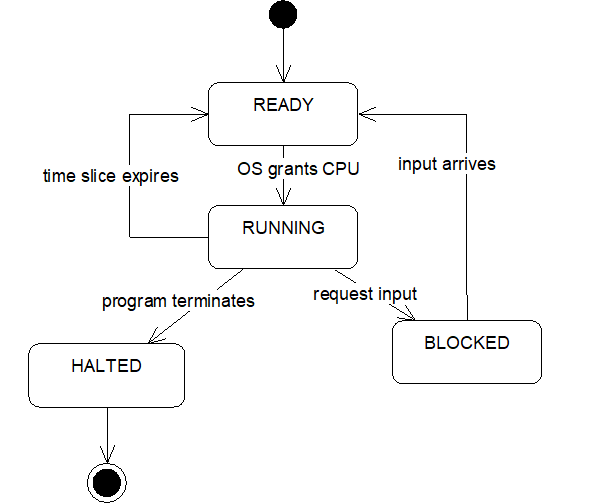
4.6.3 State Diagrams
In some cases state space might be relatively small and the legal transitions between states might be constrained.
For example, assume an object-oriented operating systems will represent records of running processes as instances of a Process class. Assume a process can be in one of the following states:
class Process
{
public:
static const int READY; // = 0, waiting for the CPU
static const int RUNNING; // = 1, using
the the CPU
static const int BLOCKED; // = 2,
waiting for input
static const int HALTED; // = 3, program terminated
void changeState();
// etc.
private:
int state;
};
Not all state transitions make sense or should be allowed. For example, a process shouldn't be able to jump from the BLOCKED state back to the RUNNING state. Some other process may have been granted the CPU. We can use a UML state diagram to model the legal transitions.
4.6.4 States as Objects
Normally, a function that operates on a stateful object will depend on the current state of that object. A multi-way conditional such as a switch statement might be used to implement such a function:
switch(object.state)
{
case state1: doSomething1(object);
break;
case state2: doSomething2(object);
break;
case state3: doSomething3(object);
break;
// etc.
default: throw AppError("unrecognized
state");
};
Although object-oriented programmers generally avoid complicated multi-way conditionals, this one poses no real problem provided the state space is completely known at compile time, and subsequent changes will be rare.
Unfortunately, the state space of a class often isn't completely known at compile time. For example, suppose our drawing program allows users to display read-only labels on virtual canvases. A label is represented by an object that encapsulates a string and a font:
class Label
{
public:
Label(string s, Font f): text(s) { font
= f; }
void setFont(Font f) { font = f; }
Font getFont() const { return font; }
string getLabel() const { return text;
}
void display(int x, int y);
private:
const string text;
Font font;
};
The state space of Label is simply Font:
STATES(Label) = Font
We don't include text as a state space component because it isn't a changeable attribute.
But what is the definition of Font? We might try:
Font = all fonts currently available on the user's computer
The problem is that at the time we declare the Label class we can't possibly anticipate which fonts will be available on the user's computer. Indeed, a user may add and remove fonts all of the time, and of course different users will have different fonts.
Even if we redefine Font as:
Font = all fonts currently available on a typical computer
we will still need to occasionally add fonts as our definition of "typical" changes.
To see why this is a problem, assume we temporarily define font as follows:
enum Font { Times, Roman, Helvetica, Courrier };
Consider the implementation of the display() method:
void Label::display(int x, int y)
{
switch(font)
{
case Helvetica:
// display text in Helvetica at
position (x, y);
break;
case Times:
// display text in Times at position
(x, y);
break;
case Roman:
// display text in Roman at position
(x, y);
break;
case Courrier:
// display text in Courrier at
position (x, y);
break;
default:
throw AppError("font
unavailable");
}
}
Now suppose we want to add a new font called Dingbats to our "typical" computer. Of course we need to modify the definition of Font:
enum Font { Times, Roman, Helvetica, Courrier, Dingbats };
We also need to add a new case clause to the display() method:
case Dingbats:
// display text in Dingbats at position
(x, y);
break;
But we will also need to add this case clause to all other functions that depend on the state of a text object. There could be many functions like this. Failing to add the case clause to just one of them introduces a bug into existing code.
In situations where the state space of a class is open ended, it is sometimes useful to decouple an object from its current state. This is the idea behind the State Pattern:
State [Go4]
Other Names
States as Objects
Problem
When the state space of a class, C, is modified, then all member functions of C that depend on the current state of their implicit parameter must also be modified. Failing to modify any one of these functions introduces a bug into the program. This can be especially hazardous if there are many member functions that need to be modified or if the state space changes frequently.
Solution
If the state space of C is relatively small, then we can associate with each state a distinct subclass of an abstract State base class. If x is an instance of C, then the state of x is given by an associated instance of one of these classes. Each state-dependent member function of C simply forwards client requests to the associated state object. Of course the behavior of these functions will vary according to the type of the associated state object, but that's the point. Modifying the state space of C is simply a matter of adding, removing, or modifying classes derived from the State base class. No changes to C are necessary.
4.6.4.1
Static
Structure
Assume the state space of a class named Context (i.e., the Handle) consists of three states:
STATES(Context) = {X, Y, Z}
Also assume that Context provides three state-dependent services: A, B, and C. In other words, if we ask a Context object to perform one of these services, then the behavior we observe will depend on the current state of this object: X, Y, or Z, and as a side effect, a state transition might occur.
Following the State Pattern, we define an abstract State base class (the Body class) that specifies virtual services A, B, and C. These services are actually implemented in the StateX, StateY, and StateZ subclasses of State. Of course the implementations will vary. Instead of encapsulating its current state, each Context object is linked to an instance of one of these derived classes.

Here's how the abstract State
class might be declared:
class State
{
public:
virtual void serviceA(Context* c) = 0;
virtual void serviceB(Context* c) = 0;
virtual void serviceC(Context* c) = 0;
};
StateX, StateY, and StateZ are concrete classes derived from State:
class StateX: public State { ... };
class StateY: public State { ... };
class StateZ: public State { ... };
The Context class maintains a pointer called state that points to an instance of a class derived from State. We don't need to be more specific about this other than to say that state is of type State*. Each Context member function simply calls the corresponding member function of the current state, forwarding its implicit parameter as an argument:
class Context
{
public:
Context(State* s = 0) { state = s; }
void serviceA() { if (state)
state->serviceA(this); }
void serviceB() { if (state)
state->serviceB(this); }
void serviceC() { if (state) state->serviceC(this);
}
void setState(State* s) { if (state)
delete state; state = s; }
// etc.
private:
State*
state; // current state
// etc.
};
Clients or any of the State member functions might change the state of a Context object using the Context::setState() function. This will instantly change the behavior of the Context object's services. For example, assume service C causes a Context object in state X to transition to state Y. Here is how this might be implemented:
void StateX::serviceC(Context* c)
{
// perform service C
c->setState(new StateY());
}
Note that by executing this function, a StateX object, s, commits "suicide". This is because of the call to setState(), which deletes the Context object's current State object, s.
4.6.4.2
Example
Continued
Let's apply the State Pattern to our Label class. First, we define Font as the abstract base class of all fonts. By declaring display() as a pure virtual method, we guarantee that all Font objects will know how to display themselves:
class Font
{
public:
virtual void display(Label* t, int x,
int y) = 0;
};
The Label class is modified so that it contains a pointer to its font state:
class Label
{
public:
Label(string s, Font* f): text(s) {
font = f; }
void display(int x, int y)
{
if (font) font->display(this, x,
y);
}
void setFont(Font* f) { if (font)
delete font; font = f; }
// etc.
private:
const string text;
Font* font;
};
Fonts such as Roman and Times are simply concrete classes derived from Font. For example:
class Times: public Font
{
public:
void display(Label* t, int x, int y)
{
// display t->getLabel() in Times
at position (x, y)
}
};
Now suppose we want to add the new Dingbats font to our drawing application. Of course we must declare a Dingbats class derived from Font:
class Dingbats: public Font
{
public:
void display(Label* t, int x, int y)
{
// display t->getLabel() in
Dingbats at position (x, y)
}
};
Notice, however, that no change the Label class is necessary. We can even change the font of an existing label to the new font:
myLabel.setFont(new Dingbats());
4.7
Strategies
A strategy is an object that encapsulates some policy or algorithm used by one or more classes in an application. For example, a strategy object for a network might encapsulate a buffering policy, a routing algorithm, or a congestion control algorithm. A strategy object for an operating system might encapsulate a page replacement policy or a process scheduling algorithm. The ET++ application framework uses strategy objects to encapsulate text formatting policies such as line breaking algorithms. IBM's San Francisco framework uses strategy objects to encapsulate volatile business policies such as marketing strategies, investment strategies, or strategies for evaluating potential customers.
Strategy [Go4], [WWW 5]
Other Names
Policy
Problem
The algorithm used by a particular member function may need to vary from one instance of the class to the next. Or, we may need to change this algorithm for a particular instance of the class. This can happen when the appropriate algorithm is determined by volatile conditions within the environment. For example, a government taxation policy affects the behavior of consumers, investors, and firms. The policy may change often, or the policy may be different for different instances of the same class.
Solution
Encapsulate the algorithm in a separate strategy object. Different algorithms are encapsulated by different strategy classes. Each object in the application-level class is linked to an appropriate strategy object that determines the algorithm currently used by that object.
4.7.1 Static Structure
Assume a Context (i.e., Handle) class provides a member function called serviceA(). Further assume that this function calls a helper function declared as a pure virtual function in an associated Strategy (i.e., Body) class. Of course different implementations of the helper function are provided by different classes derived from the Strategy base class:
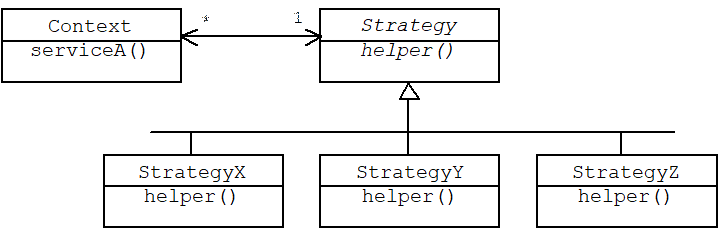
Here is a sketch of our Context class:
class Context
{
public:
void serviceA();
void setStrategy(Strategy* s) {
strategy = s; }
Strategy* getStrategy() const { return
strategy; }
// etc.
private:
Strategy* strategy;
};
The abstract Strategy base class is shared by maintains a protected pointer back to its context:
class Strategy
{
public:
Strategy(Context* c) { context = c; }
virtual void helper() = 0;
protected:
Context* context;
};
The implementation of serviceA() involves a call to the helper function of the associated strategy object:
void Context::serviceA()
{
if (strategy)
{
step1();
step2();
strategy->helper();
step3();
step4();
}
}
Assume a client creates several instances of the Context class, each linked to a different type of strategy:
Context c1, c2;
c1.setStrategy(new StrategyX(&c1));
c2.setStrategy(new StrategyZ(&c2));
Next, servceA() is invoked from each of the Context instances:
c1.serviceA();
c2.serviceA();
Although c1 and c2 are instances of the same class, and although we are invoking the same function in both cases, we can expect to observe different behavior due to the differences in strategies used by c1 and c2. Furthermore, the strategy used by c1 can be changed dynamically:
c1.setStrategy(new StrategyY(&c1));
4.7.1.1
Parameterized
Strategies
The previous implementation of the Strategy pattern uses parameterless delegation. The disadvantage of this implementation is that it requires a Strategy object to be dedicated to a single Context object. If a Strategy object needs to be shared by several Context objects, then parameterless delegation should be used:
class Strategy
{
public:
virtual void helper(Context* c)
= 0;
};
4.7.2 Example: Investment
Strategies
An on-line trading application might represent a portfolio as an account with a list of investments. Adding a new investment to the portfolio involves decrementing the balance to provide funds for the new investment. An object representing the investment is then added to the portfolio's list. Of course how much money should be spent on the new investment depends on the investment strategy used. For example, a safe strategy might invest smaller amounts on high risk investments such as lottery tickets and larger amounts on low risk investments such as real estate and blue chip stocks.
Here's the static structure of our financial application:
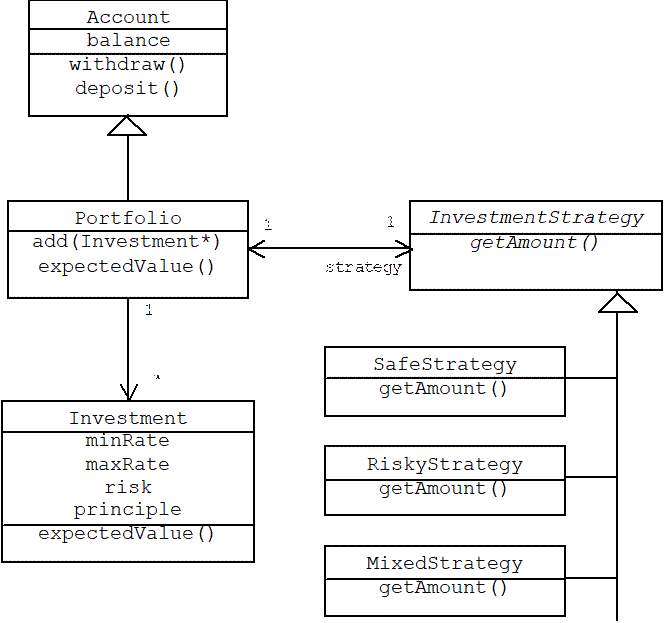
Four attributes describe an investment: the principle ( i.e., the amount initially invested); the maximum rate of return; the minimum rate of return (this is a number between -100% and the maximum rate of return); and the risk (this is a number between 0 and 1 indicating the probability of the lower rate of return). The expected value of an investment is simply the weighted sum of the maximum and minimum returns:
double Investment::expectedValue()
{
double value =
principle * (maxRate * (1 - risk) +
minRate * risk);
return value;
}
Of course the expected value of a portfolio is its balance plus the expected values of its investments:
double Portfolio::expectedValue()
{
list<Investment>::iterator p;
double value = getBalance();
for(p = investments.begin(); p !=
investments.end(); p++)
value += (*p).expectedValue();
return value;
}
Before adding a new investment to a portfolio, the associated investment strategy is consulted to determine the amount that should be invested:
void Portfolio::add(Investment inv)
{
double amt =
strategy->getAmount(inv);
if (0 < amt && amt <=
getBalance())
{
inv.setPrinciple(amt);
withdraw(amt);
investments.push_back(inv);
}
}
class InvestmentStrategy
{
public:
virtual double getAmount(Investment
inv) = 0;
void setPortfolio(Portfolio* p) { pf =
p; }
protected:
Portfolio* pf;
};
The actual implementation is specified in derived classes, and of course one derived class might implement this function quite differently from another.
For example, suppose a client defines the following investments. (The Investment constructor arguments specify the maximum rate of return, minimum rate of return, and risk, respectively. The principle is initially $0.)
Investment lotteryTicket(50000,
-1, .99999),
bond(1.2, 1.1, .1),
hiTechStock(4, -.5, .6),
blueChipStock(1.5, 0, .6),
junkBond(2, -1, .4),
realEstate(2, -.1, .2);
Next, two portfolios are created, one that uses a safe investment strategy, another that uses a risky strategy:
Portfolio p1(1000, new SafeStrategy());
Portfolio p2(1000, new RiskyStrategy());
Copies of the same investments are added to each portfolio:
p1.add(lotteryTicket);
p1.add(hiTechStock);
p1.add(blueChipStock);
p1.add(junkBond);
p1.add(realEstate);
p2.add(lotteryTicket);
p2.add(hiTechStock);
p2.add(blueChipStock);
p2.add(junkBond);
p2.add(realEstate);
However, the expected value of p1 is larger than the expected value of p2. This difference arises because p2 invested heavily in lottery tickets, junk bonds, and high-tech stocks according to its risky strategy, while p1 invested more heavily in real estate and blue chip stocks according to its safe strategy. (Of course the actual values of the portfolios will depend on fate, karma, and luck.)
4.7.3 Example: Layout Strategies in
Java
A typical Java control panel might consist of a framed window containing a couple of buttons. Java's Abstract Windows Toolkit package (AWT) provides the necessary Frame and Button classes:
Frame gui = new Frame();
gui.add(new Button("ON"), "West");
gui.add(new Button("OFF"), "East");
Here's what the control panel looks like on the desktop:

Notice that the "ON" button occupies the left or western end of the frame, while the "OFF" button occupies the right or eastern end of the frame.
Java frames use the strategy pattern to determine where controls should be positioned when they are added to the frame using the add() method. In this situation the frame is the context, while strategies are called layout managers. Java provides several layout managers:

When a frame is created, it's provided with a BorderLayout layout manager. This strategy allows programmers to add controls to the Northern, Eastern, Western, Southern, and Central regions of the frame. If this isn't acceptable, a programmer can specify a different layout manager using the setLayout() method.
For example, a GridLayout strategy allows programmers to partition a frame into any number of rows partitioned into any number of columns. Here we partition our frame into a single row consisting of two columns:
Frame gui = new Frame();
gui.setLayout(new GridLayout(1, 2));
gui.add(new Button("ON"));
gui.add(new Button("OFF"));
Here's what the control panel looks like on the desktop:

A FlowLayout strategy attempts to horizontally center all of the controls in the frame, creating new rows as needed. Again, we use the setLayout() method to change the layout strategy:
Frame gui = new Frame();
gui.setLayout(new FlowLayout());
gui.add(new Button("ON"));
gui.add(new Button("OFF"));
Here's how the control panel appears on the desktop:

Naturally, Java programmers can define custom layout managers, if they wish.
4.8
Decorators
The State and Strategy Patterns provide two ways to change the behavior of an object: change its state, or change its strategy. Both of these techniques involve an internal change, a change of guts. Alternatively, we can leave the guts in tact, and change the object's skin. To do this, we wrap the object with another object that implements the same interface, hence is indistinguishable from the original object in the client's view. The wrapper object intercepts messages passed between the client and the wrapped object, adding additional behaviors as needed. Of course we can wrap the original object with an indefinite number of wrappers (i.e., layers of skin) to get any combination of behaviors we want. This is the essential idea behind both the Proxy Pattern (discussed in Chapter 7) and the Decorator Pattern:
Decorator [Go4]
Other Names
Wrapper, Proxy (a special type of decorator)
Problem
Suppose we want to add all possible combinations of n features to a class, C. If we introduce a new subclass for each combination, then we will end up with a very large hierarchy of classes. (How large?) The number is even greater if the features are order-dependent. (Now how large?) Adding yet another feature to the mix will require extending every class in the hierarchy. This is especially wasteful if some combinations of features are rarely or never used.
Solution
Suppose class C implements interface I. For each new feature, create a "decorator" class that implements interface I by delegating to another object. This object may be an instance of C or it may be yet another decorator. A decorator implements a particular feature by adding behavior either before or after the delegation.
To add a combination of m features to an instance, x, of C, we simply place x at the end of a chain of m decorators, one for each feature. Since decorators implement the same interface as C, clients (and decorators) never know if they are requesting service from an instance of C or from a decorator.
4.8.1 Static Structure
Assume a class called Component implements an interface called IComponent, and suppose we want to use the Decorator Pattern to allow users to add all possible combinations of n features to a component (i.e., a Component object). We begin by introducing a Decorator class that implements the IComponent interface, and serves as the base class for all other decorator classes. In the following diagram we show two Decorator-derived classes. Presumably, each adds behavior to one or more of the services defined in the interface:
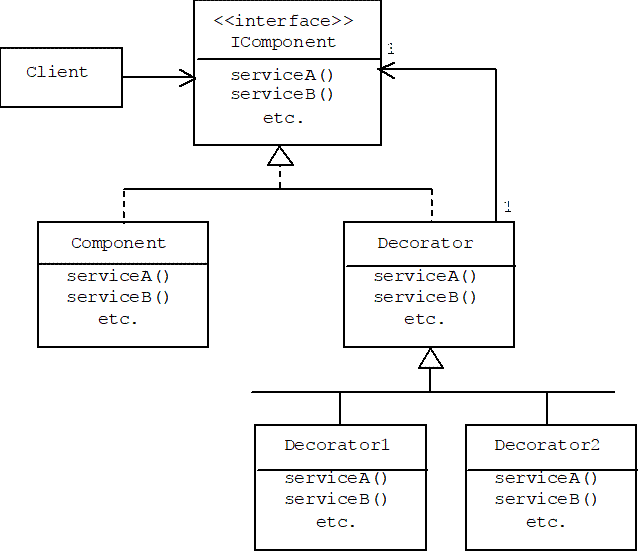
Translating the diagram into C++, IComponent specifies component services as pure virtual functions:
class IComponent // interface
{
public:
virtual void serviceA() = 0;
virtual void serviceB() = 0;
// etc.
};
These services are implemented in the Component class:
class Component: public IComponent
{
public:
void serviceA() { ... }
void serviceB() { ... }
// etc.
};
The Decorator base class simply delegates to another component:
class Decorator: public IComponent
{
public:
Decorator(IComponent* c = 0) {
component = c; }
virtual void serviceA() { if
(component) component->serviceA(); }
virtual void serviceB() { if (component)
component->serviceB(); }
// etc.
private:
IComponent* component;
};
Suppose Decorator1 enhances serviceA() with some added behavior, then it only needs to re-implement serviceA() (the Decorator class provides default implementations for the other services). The added behavior can take the form of pre or post processing:
class Decorator1: public Decorator
{
public:
Decorator1(IComponent* c = 0):
Decorator(c) {}
void serviceA()
{
// pre-processing goes here
Decorator::serviceA(); // delegate to
component
// and post-processing goes here
}
};
Here is how a client might create a pointer, z, to an object that implements the basic IComponent interface, but with the features added by Decorator1 and Decorator2:
IComponent* x = new Component();
IComponent* y = new Decorator1(x);
IComponent* z = new Decorator2(y);
Of course the original component and the Decorator1 instance can be anonymous, so we can create z in a single line:
IComponent* z = new Decorator2(new Decorator1(new Component()));
Here is a sequence diagram showing the chain of delegations that occur when the client calls z->serviceA():

Be careful, a decorator derives from the IComponent interface and delegates to an instance of the IComponent interface. We need decorators to be derived from the IComponent interface so they can be treated like components by clients and other decorators. However, a decorator must never use any functions or attributes it inherits from the IComponent interface. Instead, only the functions and attributes of the delegate component must be used. This is no problem if IComponent is a proper interface that only specifies member functions, but assume IComponent is an abstract class that declares an attribute called state:
class IComponent
{
public:
virtual void serviceA() = 0;
virtual void serviceB() = 0;
// etc.
protected:
State state; // this will be inherited
};
The true state of a decorator, d, is the state of its component, (d.component)->state, not its inherited state, d.state.
4.8.2 Example: I/O Filters in Java
File I/O in a Java program is performed by objects called streams. There are file input streams and file output streams. Let's examine file output streams; a similar story can be told for file input streams.
Unfortunately, a file output stream only knows how to write a single byte (i.e., an unsigned integer below 256) to an associated file. This might limit programmers interested in writing more complex data such as integers, floats, doubles, characters, and Booleans to a file. Also, the basic file output stream doesn't buffer its output, it doesn't guard against transmission errors, and it doesn't translate Java's 16-bit UNICODE characters to the character encoding scheme used by the underlying computer. (Of course not all programmers want all of these features.)
To solve these problems Java uses the Decorator Pattern to add features to file output streams. In this context file output streams are components, the role of component interface is played by the abstract OutputStream class, and decorators are called filters:
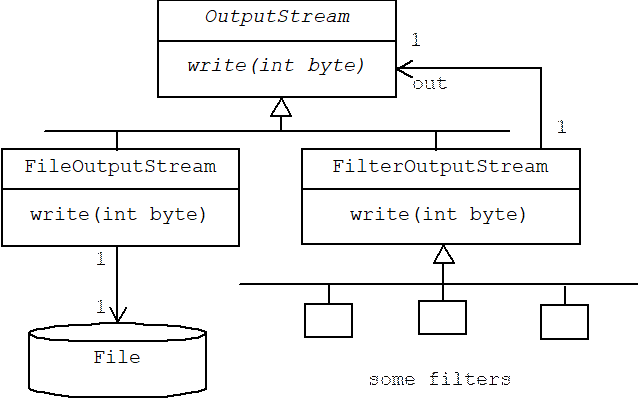
Most of these classes are declared in the java.io package. The abstract OutputStream class specifies several abstract write() methods:[2]
public abstract class OutputStream {
// write one byte to a file:
public abstract void write(int byte)
throws IOException;
// write an array of bytes to a file:
public abstract void write(int[] bytes)
throws IOException;
// etc.
}
The FileOutputStream class extends the OutputStream class and implements the write() method by actually writing its argument to an associated file:
public class FileOutputStream extends OutputStream {
public void write(int byte) throws
IOException {
// write byte to an associated file
}
public void write(int[] bytes) throws
IOException {
// block transfer bytes to an
associated file
}
// etc.
}
The FilterOutputStream class (this is the Decorator base class) also extends the OutputStream class. It implements the write() methods by delegating to another OutputStream object called out:
public class FilterOutputStream extends OutputStream {
protected OutputStream out;
public FilterOutputStream(OutputStream
os) {
out = os;
}
public void write(int byte) throws
IOException {
out.write(byte); // delegate to out
}
public void write(int[] bytes) throws
IOException {
out.write(bytes); // delegate to out
}
// etc.
}
4.8.2.1
Some
Pre-Defined Filters
Java provides several pre-defined filters (decorators). A data output stream provides methods for writing Java primitive values such as ints, doubles, chars, and booleans. Each method breaks its argument into a sequence of bytes, then forwards each byte to the associated delegate output stream:
public class DataOutputStream extends FilterOutputStream {
public void writeInt(int x) throws
IOException {
// write x in Big Endian order:
super.write(most significant byte
of x);
super.write(second most significant
byte of x);
super.write(third most significant
byte of x);
super.write(least significant byte
of x);
}
// etc.
}
Note: super.write() calls the write() method inherited from the super class. In this case the super class is FilterOutputStream, which implements write() as out.write(). Thus, calling super.write() asks the super class to perform the necessary delegation.
A buffered output stream stores bytes in a buffer. When the buffer is full, the stored bytes are forwarded to the associated delegate output stream as a block:
public class BufferedOutputStream extends FilterOutputStream {
private final int size = 256; // buffer
capacity
protected int[] buf = new int[size]; //
buffer = byte array
protected int count = 0; // # of bytes
in buffer
public void write(int byte) throws
IOException {
buf[count++] = byte;
if (size <= count) { // if buffer
full
super.write(buf); // write
buffer to out
count = 0; // empty buffer
}
}
// etc.
}
Buffering output allows the operating system to write blocks of bytes to a file, which is far more efficient than writing bytes to a file one at a time.
The check sum of a byte or an array of bytes is simply the sum of all of the bits. For example, the check sum of 10101011 is five. We can guard against transmission errors by remembering the check sum of the bytes written to a file. If this doesn't agree with the check sum of the bytes read from this file, then a transmission error has occurred. (Of course this technique fails in the unlikely event that the number of 1 bits accidentally changed to 0 exactly equals the number of 0 bits that were accidentally changed to 1.)
A checked output stream (defined in the java.util.zip package) maintains a check sum for all bytes forwarded to the associated delegate output stream:
public class CheckedOutputStream extends FilterOutputStream {
private Checksum cksum;
public CheckedOutputStream(OutputStream
os, Checksum cs) {
super(os); // out = os
cksum = cs;
}
public void write(int byte) throws
IOException {
super.write(byte);
cksum.update(byte); //cksum += sum
of bits in byte
}
public void write(int[] bytes) throws IOException
{
super.write(bytes);
cksum.update(bytes); //cksum += sum
of bits in bytes
}
// etc.
}
4.8.2.2
Writing
Data to a File
Instead of writing data directly to a file output stream, a Java programmer might place the stream at the end of a chain of filters, then write data to the first filter in the chain. For example, the following Java code creates a sequence of three filters in front of a file output stream:
try {
// create filter chain:
FileOutputStream fout =
new
FileOutputStream("myData");
BufferedOutputStream bout =
new BufferedOutputStream(fout);
CheckedOutputStream cout =
new CheckedOutputStream(bout, new
CRC32());
DataOutputStream dout =
new DataOutputStream(cout);
// write data:
dout.writeInt(42);
dout.writeDouble(3.14);
dout.writeChar('x');
dout.writeBoolean(true);
dout.writeChars("Hello,
World");
// etc.
} catch (IOexception e) {
// handle e
}
Of course the decorator chain could have been created by a single declaration:
DataOutputStream dout =
new DataOutputStream(
new CheckedOutputStream(
new BufferedOutputStream(
new
FileOutputStream("myData")), new CRC32()));
The following object diagram depicts the filter chain:

Note that the myData file contains Java data, and therefore can only be read by another Java program using a decorated file input stream.
4.8.3 Example: Graphical Contexts
Computer graphics programs try to avoid dependencies on a particular type of monitor or graphical output device. This can be done by specifying an interface all graphical output devices are assumed to implement, then writing the application on top of the interface rather than a device-specific graphics library. Implementations of the interface are commonly called graphical contexts, hence we call our interface GC. It specifies functions for plotting points, lines, and text on an implicit virtual canvas using a virtual pen, as well as functions for clearing and displaying the canvas.
A GC decorator can add behavior to these functions before or after forwarding client requests to the next graphical context in a decorator chain. For example, a shaded GC is a GC decorator that re-implements clear() so that it paints its canvas gray instead of white. A bordered GC is a GC decorator that re-implements display() so that it displays a border around its canvas.
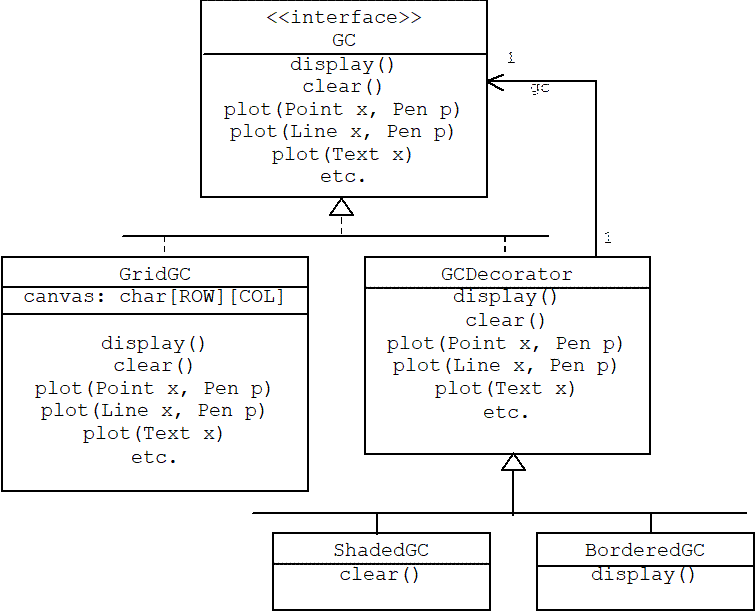
Unfortunately, the standard C++ library doesn't support graphics, so to test our decorators we will implement GC with a class called GridGC. A GridGC's virtual canvas is simply a two-dimensional array of characters. (This is called "Poor Man's Graphics".)
4.8.3.1
Static
Structure
The structure of our example is given by the following class diagram:
4.8.3.2
Some
Utility Types
The GC interface assumes a virtual canvas is endowed with a two-dimensional integer coordinate system. The interface further assumes the origin of this coordinate system is located in the upper left corner of the canvas, the positive x-axis runs along the top edge of the canvas, and the positive y-axis runs down the left edge of the canvas. As we mentioned before, these assumptions are common in graphics libraries.

A Point object groups the x and y integer coordinates of a point in this coordinate system:
struct Point
{
Point(int x = 0, int y = 0) { xc = x;
yc = y; }
int xc, yc;
};
A Line object groups the start and end points of a line segment in this coordinate system:
struct Line
{
Line(Point p1, Point p2) { start = p1;
end = p2; }
Point start, end;
};
A Text objects groups a string and the position in this coordinate system of it's first character:
struct Text
{
Text(string s, Point p) { text = s;
start = p; }
string text;
Point start;
};
We defer the definition of Pen:
class Pen; // forward reference
But we assume that commonly used pens have already been created:
extern Pen whitePen;
extern Pen blackPen;
extern Pen grayPen;
extern Pen strokePen;
extern Pen dashPen;
4.8.3.3
A
Test Program
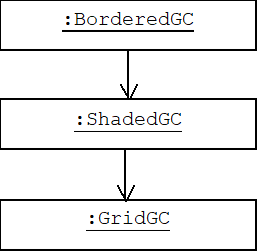
Our test program, main(), begins by creating a GridGC wrapped by a shaded GC decorator, which in turn is wrapped by a bordered GC decorator:
GC* gc = new BorderedGC( new ShadedGC( new GridGC()));
The following object diagram depicts this decorator chain:
Next, we calculate the coordinates of the top center, bottom center, left center, and right center points of the canvas:
int height = gc->getHeight();
int width = gc->getWidth();
Point topCenter(width/2, 0);
Point bottomCenter(width/2, height);
Point leftCenter(0, height/2);
Point rightCenter(width, height/2);
The vertical center line of the canvas connects its top and bottom center points. The horizontal center line connects its left and right center points.
Line vCenter(topCenter, bottomCenter);
Line hCenter(leftCenter, rightCenter);
gc->plot(vCenter);
gc->plot(hCenter);
Once plotted, the horizontal and vertical center lines divide the canvas into four quadrants, which we label I, II, III, and IV, in counter-clockwise order:
Point q1Center(3 * width/4, height/4);
Text q1("I", q1Center);
gc->plot(q1);
Point q2Center(width/4, height/4);
Text q2("II", q2Center);
gc->plot(q2);
Point q3Center(width/4, 3 * height/4);
Text q3("III", q3Center);
gc->plot(q3);
Point q4Center(3 * width/4, 3 * height/4);
Text q4("IV", q4Center);
gc->plot(q4);
Finally, we display the canvas:
gc->display();
Here is the output produced:
|---------------------------------|
|////////////////*////////////////|
|////////////////*////////////////|
|///////II///////*////////I///////|
|////////////////*////////////////|
|////////////////*////////////////|
|////////////////*////////////////|
|*********************************|
|////////////////*////////////////|
|////////////////*////////////////|
|////////////////*////////////////|
|///////III//////*////////IV//////|
|////////////////*////////////////|
|////////////////*////////////////|
|---------------------------------|
Note that GridGC uses space for white, forward slash for gray, star for black, and pipes and hyphens for borders.
4.8.3.4
The
Graphical Context Interface
The graphical context interface, GC, specifies functions for plotting points, lines, and text on a virtual canvas using a virtual pen. It also specifies a function for filling (i.e., repainting) a virtual canvas using a virtual pen. The clear() function fills the canvas using a white pen, and the display() function causes the canvas to be displayed in a window:
class GC // interface
{
public:
virtual void display() = 0;
virtual void clear() = 0;
virtual void fill(const Pen& p) =
0;
virtual int getWidth() const = 0;
virtual int getHeight() const = 0;
virtual void plot(const Point& x,
const Pen& p = blackPen) = 0;
virtual void plot(const Line& x,
const Pen& p = blackPen) = 0;
virtual void plot(const Text& x) =
0;
// etc.
};
4.8.3.5
GC
Decorators
GCDecorator, the base class for all GC decorators, simply delegates client requests to the next graphical context in the chain:
class GCDecorator: public GC
{
public:
GCDecorator(GC* g = 0) { gc = g; }
void display() { if (gc)
gc->display(); }
void clear() { if (gc) gc->clear();
}
void fill(const Pen& p) { if (gc) gc->fill(p);
}
int getHeight() const { return gc?
gc->getHeight(): 0; }
int getWidth() const { return gc?
gc->getWidth(): 0; }
void plot(const Point& x, const
Pen& p = blackPen)
{
if (gc) gc->plot(x, p);
}
void plot(const Line& x, const
Pen& p = blackPen)
{
if (gc) gc->plot(x, p);
}
void plot(const Text& x)
{
if (gc) gc->plot(x);
}
private:
GC* gc;
};
4.8.3.6
Shaded
GC Decorators
A shaded GC decorator redefines the inherited clear() function so that it fills in the canvas using a gray pen:
class ShadedGC: public GCDecorator
{
public:
ShadedGC(GC* g = 0): GCDecorator(g) {
clear(); }
void clear() { fill(grayPen); }
};
This example hides the delegation operation. Instead of calling GCDecorator::clear(), it calls fill(grayPen), which is the function inherited from the GCDecorator class that delegates to the fill() function of the next graphical context in the decorator chain.
4.8.3.7
Bordered
GC Decorators
A bordered decorator redefines the display() function inherited from the GCDecorator base class. The new function first plots a border around the canvas, then delegates:
class BorderedGC: public GCDecorator
{
public:
BorderedGC(GC* g = 0): GCDecorator(g)
{}
void display()
{
plotBorder();
GCDecorator::display(); // delegate
}
private:
void plotBorder();
};
See Programming Note 4.17.1 for the implementations of plotBorder() and GridGC.
4.9
Canonical
Form
Delegation is not as natural in C++ as it is in languages based on reference semantics like Java, C#, and LISP. There are many pitfalls and programmers must know how to work around them.
Recall the idealized outline of a handle-body declaration:
class Body
{ // no client access, handles only!
friend class Handle;
void serviceA();
void serviceB();
// etc.
};
class Handle
{
public:
Handle(Body* b = 0) { myBody = b? b:
new Body(); }
void serviceA() { if (myBody)
myBody->serviceA(); }
void serviceB() { if (myBody)
myBody->serviceB(); }
// etc.
private:
Body* myBody;
};
Assume we create two handles:
Handle h1, h2;
The default constructor for Handle, defined above, will automatically create two new bodies for these handles. Let's call them b1 and b2, respectively. The picture in memory looks like this:
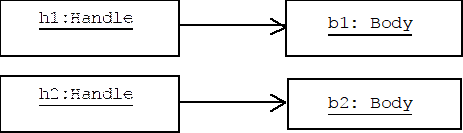
Now assume we change our minds and reassign h2 to be like h1:
h2 = h1;
The default assignment algorithm in C++ is called member-wise copy. Each field of h1 is copied to the corresponding field of h2, including the pointer to b1. The new picture looks like this:
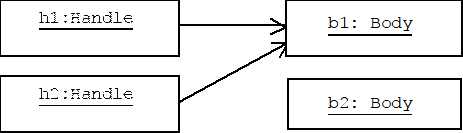
There are two problems with this picture. First, we have a memory leak because b2 was not properly deallocated (remember, the one and only pointer to b2 was encapsulated by h2, so there are no more active references to b2.) Second, we have a potential aliasing problem because h2 and h1 both reference the same body. Changes to the body made through h2 will be reflected in h1.
We summarize these problems, with their standard solution, as the Canonical Form Pattern. Since this pattern is specific to C++, it is more properly designated as an implementation pattern rather than a design pattern:
Canonical Form [COPE], [HORST1]
Other Names
Orthodox Canonical Form, OCF
Problem
Copying a handle does not make a copy of its body, and deleting a handle does not delete its body. This can lead to aliasing problems and memory leaks.
Solution
Provide a copy constructor and assignment operator that make copies of the body; also provide a destructor that deletes the body.
The new assignment operator does nothing if its right- and left-hand sides are the same. Otherwise, the old body is deleted by calling a private supporting function, free(), and a copy of the body belonging to the handle on the right-hand side of the assignment operator is created. The address of this new body is assigned to the myBody variable of the handle on the left-hand side of the assignment operator. All of this is accomplished by a private supporting function called copy():
Handle& Handle::operator=(const Handle& h)
{
if (&h != this) // x = x is a no-op
{
free(); // delete myBody
copy(h); // point myBody to a copy
of *(h.myBody)
}
return *this;
}
After the h2 = h1 assignment the picture will now look like this:

Handles can also be copied by copy constructors, again the default algorithm is member-wise copy, hence we must redefine the copy constructor to call the private copy() function described above:
Handle::Handle(const Handle& h)
{
copy(h); // point myBody to a copy of
*(h.myBody)
}
Whenever we define a constructor, we must also define a default constructor, otherwise we will loose the default constructor provided by C++. The default constructor is important because it is always used to initialize arrays of class instances. Also, derived class constructors automatically call their base class' default constructor (unless a different constructor is specified in the initializer list).
Handle::Handle(Body* b /* = 0 */)
{
myBody = (b? b: new Body());
// initialize any other fields
}
We must also provide a destructor that automatically deallocates the body when the handle is deallocated. Our destructor calls free(), the private supporting function mentioned earlier:
Handle::~Handle()
{
free(); // delete myBody
}
The copy() and free() functions are private member functions that encapsulate the details of copying and deleting bodies. If the body is a properly defined C++ object, then a simple implementation might be:
void Handle::free() { if (myBody) delete myBody; }
void Handle::copy(const Handle& h)
{
myBody = new Body(*(h.myBody));
// copy any other fields of h
}
But in most cases the implementations will depend on the details of the body. The new declaration of the Handle class looks like this:
class Handle
{
public:
Handle(Body*
b = 0);
Handle(const
Handle& h) { copy(h); }
~Handle() { free(); }
Handle& operator=(const Handle&
h);
void serviceA() { if (myBody)
myBody->serviceA(); }
void serviceB() { if (myBody)
myBody->serviceB(); }
// etc.
private:
Body *myBody;
void
free();
void copy(const Handle& h);
};
The members shown in bold face are required by the Canonical Form pattern for every handle class.
4.10
Virtual
Bodies
Canonical Form runs into a special problem when the handle isn't sure what class its body instantiates. This happens in the State Pattern, for example, where the context (the handle) only knows that its state (the body) instantiates some class derived from the abstract State base class. Without knowing the actual class of the body, how can the body be properly deallocated by the handle's free() function? More vexingly, how can the body be copied by the handle's copy() function?
We can express the solution to these problems as an implementation pattern:
Virtual Body
Other Names
Clonable body
Problem
If a handle only knows the abstract base class of its associated body, then how can the body be properly deallocated or copied?
Solution
The first problem is easily solved by supplying the abstract Body class with a virtual destructor. The second problem is solved by supplying the abstract Body class with a virtual cloning method. Derived classes redefine these functions accordingly.
For example, assume the services provided by our Body class are pure virtual functions that will be implemented in various derived classes. We must add a virtual destructor and a pure virtual factory method, usually called clone(), to the Body class:
class Body
{
protected:
// access restricted to handles and
derived classes:
friend class Handle;
virtual void serviceA() = 0;
virtual void serviceB() = 0;
// etc.
virtual
~Body() {}
virtual Body* clone() const = 0;
};
In addition to implementing the basic services, each concrete derived class may define a destructor and must define a clone() function. Fortunately, the implementation of the clone() function is routine, and could probably be generated by a clever macro:
class Body1: public Body
{
void serviceA() { ... }
void serviceB() { ... }
~Body1() { ... }
Body*
clone() const { return new Body1(*this); }
};
The handle's free() function can simply delete the body:
void Handle::free() { if (myBody) delete myBody; }
If myBody points at an instance of Body1, then the Body1 destructor will be called. For this reason it's a good idea to supply all base classes with a virtual destructor.
The handle's copy() function uses its body's clone() function to create a new body from the body of another handle:
void Handle::copy(const Handle& h)
{
myBody = h.myBody->clone();
// copy any other fields of h
}
4.10.1 Example: Clonable Strategies
As an application of the Clonable Body Pattern, let's return to the investment portfolio application we sketched as a demonstration of the Strategy Pattern. Recall that a portfolio is a special type of financial account that includes a list of investments as well as a pointer to an investment strategy. Each time a proposed investment is added to a portfolio, its associated strategy object is consulted to determine how much money should be spent on the investment.
In the present context portfolios are handles, while investment strategies are bodies. Following the Canonical Form Pattern, we add a copy constructor, destructor, and assignment operator to the Portfolio class, as well as free() and copy() helper functions:
class Portfolio: public Account
{
public:
Portfolio(double bal = 0,
InvestmentStrategy* s = 0);
Portfolio(const Portfolio& p) {
copy(p); }
~Portfolio() { free(); }
Portfolio& operator=(const
Portfolio& p);
void add(Investment inv);
double expectedValue();
// etc.
private:
InvestmentStrategy* strategy;
list<Investment> investments;
void free();
void copy(const Portfolio& p);
};
InvestmentStrategy is simply the abstract base class for all concrete investment strategies. Following the Clonable Body Pattern, we add a virtual destructor and a pure virtual clone() function to this class:
class InvestmentStrategy
{
public:
void setPortfolio(Portfolio* p) { pf =
p; }
virtual double getAmount(Investment
inv) = 0;
virtual ~InvestmentStrategy() {}
virtual InvestmentStrategy*
clone() = 0;
protected:
Portfolio* pf;
};
Each concrete investment strategy must implement the clone() function, although the implementations are completely routine:
class SafeStrategy: public InvestmentStrategy
{
public:
double getAmount(Investment inv);
InvestmentStrategy* clone()
{
return new SafeStrategy(*this);
}
};
class RiskyStrategy: public InvestmentStrategy
{
public:
double getAmount(Investment inv);
InvestmentStrategy* clone()
{
return new RiskyStrategy(*this);
}
};
Freeing the memory of a portfolio involves deleting the strategy as well as erasing the investments:
void Portfolio::free()
{
if (strategy) delete strategy;
investments.erase(investments.begin(),
investments.end());
}
The Portfolio copy() function clones its argument's strategy, copies its balance, then uses the copy() template function defined in the standard C++ library to copy its argument's investments:
void Portfolio::copy(const Portfolio& p)
{
strategy = p.strategy->clone();
strategy->setPortfolio(this);
setBalance(p.getBalance());
std::copy(p.investments.begin(),
p.investments.end(),
investments.begin());
}
4.11
Smart
Pointers
Pointers are dangerous creatures. It seems like programmers are always accidentally dereferencing uninitialized pointers, which usually produces the infamous "core dump" error message and crashes the program. Also, programmers often forget to recycle the memory their pointers point at by calling the delete operator, this leads to memory leaks: heap space that can't be reclaimed. Eventually, if the heap becomes exhausted, the program will crash.
One way to avoid dealing with pointers is to encapsulate them in objects that manage their initialization, access, and deletion. The manager is called a smart pointer, while the encapsulated pointer is often called a C pointer, or, more disparagingly, a dumb pointer. The idea can be summarized as a design pattern:
Smart Pointers [HORST1]
Other Names
Safe pointers
Problem
Pointers are error prone. Programmers commonly forget to initialize pointers before they use them, and they commonly forget to delete pointers after they use them. Attempting to dereference an uninitialized pointer can lead to data corruption and program crashes. Failing to delete a pointer can lead to memory leaks, which can ultimately lead to program crashes.
Solution
A smart pointer is an object that encapsulates and manages a real pointer. A smart pointer automatically initializes its real pointer and deletes it after use. A smart pointer only allows its real pointer to be dereferenced after it has been initialized. Smart pointers can be made to resemble real pointers by overloading all pointer dereferencing operators.
4.11.1 A Test Program
Our test driver, main(), begins by creating five smart pointers. It's obvious from the syntax that smart pointers are template instances and that our five smart pointers will point to integer variables:
Pointer<int> p1(3), p2(4), p3(p2), p4, p5;
Here's what memory looks like at this point:

Notice that although p3 was initialized by passing p2 to a copy constructor, p3 points to a distinct variable containing 4, the identical value that p2's variable contains. p4 and p5 were initialized using the default constructor. Consequently, they do not currently have associated variables.
Thanks to operator overloading, smart pointers can be dereferenced using the dereferencing operator, just like C pointers:
cout << "*p1 = " << *p1 << endl;
cout << "*p2 = " << *p2 << endl;
cout << "*p3 = " << *p3 << endl;
Here's the output produced by these three lines:
*p1 = 3
*p2 = 4
*p3 = 4
We can verify that p2 and p3 point to distinct variables by reassigning p2 to p1, then re-displaying p2 and p3:
p2 = p1;
cout << "*p2 = " << *p2 << endl;
cout << "*p3 = " << *p3 << endl;
Here's the output produced:
*p2 = 3
*p3 = 4
The picture in memory shows the variable formally pointed at by p2 has now been deleted, and p2 now points at a new variable with the same content as p1's variable:

In addition to main(), our test program defines two other global functions that differ only in the type of their parameter:
void test1(int* p)
{
*p = *p + 1;
cout << "*p = "
<< *p << endl;
}
void test2(Pointer<int> p)
{
*p = *p + 1;
cout << "*p = "
<< *p << endl;
}
After creating an ordinary C pointer, main() calls each function. However, the C pointer is passed to test2(), while a smart pointer is passed to test1():
int* p = new int(57); // a dumb pointer!
test1(p1);
test2(p);
Here is the output produced:
*p = 4
*p = 58
Notice that the type mismatch didn't seem to matter. test1() was apparently happy to receive a smart pointer, while test2() seemed content to receive a dumb pointer. This is good news. If we have a large library of C functions that work with C pointers, we don't need to discard it. These functions will also accept smart pointers, even though the original authors of the library probably had never heard of smart pointers.
Now we assign p3 to p4, store 0 in p3, then dereference both:
p4 = p3;
*p3 = 0;
cout << "*p3 = " << *p3 << endl;
cout << "*p4 = " << *p4 << endl;
Here's the output produced:
*p3 = 0
*p4 = 4
Notice that changing p3 had no impact on p4. Obviously the assignment operator automatically created a new variable for p4. Here's the memory picture:

Finally, main() attempts to dereference p5:
cout << "*p5 = " << *p5 << endl;
Ordinarily, dereferencing an uninitialized pointer would cause the program to crash with a mysterious error message like "access violation" or "core dump". In some cases the pointer might accidentally contain a pointer to some variable, just not the right one. This might cause the wrong answer to be produced or it may delay the crash, creating the impression that the bug is beyond this point in the program.
Dereferencing a smart pointer can either throw an exception or, in our case, cause the program to gracefully terminate with a helpful error message:
Error, null pointer dereferenced!
4.11.2 Implementing Smart Pointers
We can think of a smart pointer as a handle and the heap variable it manages as its body. (This is perhaps the simplest example of a data structure body.) As a handle-body instance, we'll have to employ Canonical Form. Also, smart pointer will need to be a template, so the entire implementation must be contained in a header file:
// pointer.h
#ifndef POINTER_H
#define POINTER_H
#include "d:\pop\util.h" // needed for error()
template <typename Storable> class Pointer { ... };
// etc.
#endif
The Canonical Form members are shown in bold face. The template parameter, Storable, refers to the type of variable pointed at by the encapsulated C pointer, ptr:
template <typename Storable>
class Pointer
{
public:
Pointer(Storable*
p = 0) { ptr = p; }
Pointer(const
Pointer<Storable>& p) { copy(p); }
~Pointer() { free(); }
Pointer<Storable>& operator=(const
Pointer<Storable>& p);
Pointer(const Storable& s);
operator Storable* () { return ptr; }
Storable& operator*();
Storable* operator->();
bool isNull() const { return !ptr; }
private:
Storable *ptr; // the dumb pointer
void
copy(const Pointer<Storable>& p);
void free() { delete ptr; }
};
When a C pointer is used in a context where a smart pointer is expected, C++ will automatically use the first constructor to encapsulate the C pointer in a smart pointer:
Pointer(Storable* p = 0) { ptr = p; }
Thus, in our test program the call:
test2(p);
was converted into:
test2(Pointer<int>(p));
When a smart pointer is used in a context where a C pointer is expected, C++ will automatically use the casting operator to extract the encapsulated C pointer.
operator Storable* () { return ptr; }
Thus, in our test program the call:
test1(p1);
was converted into:
test1((int*) p1);
Which at run time becomes:
test1(p1.ptr);
Smart pointers can be constructed from the item they point to. Notice that memory is automatically allocated using the new operator:
template <typename Storable>
Pointer<Storable>::Pointer(const Storable& s)
{
ptr = new Storable(s);
}
Dereferencing a null smart pointer prints a useful error message, then gracefully terminates the program or throws an exception:[3]
template <typename Storable>
Storable& Pointer<Storable>::operator*()
{
if (!ptr) error("null pointer
dereferenced");
return *ptr;
}
template <typename Storable>
Storable* Pointer<Storable>::operator->()
{
if (!ptr) error("null pointer
dereferenced");
return ptr;
}
Of course Canonical Form assignment is always the same:
template <typename Storable>
Pointer<Storable>&
Pointer<Storable>::operator=(const Pointer<Storable>& p)
{
if (&p != this)
{
// p = p is a no-op
free();
copy(p);
}
return *this;
}
Finally, the copy member function automatically allocates memory:
template <typename Storable>
void Pointer<Storable>::copy(const Pointer<Storable>& p)
{
ptr = new Storable(*(p.ptr));
}
4.12
Containers
A container (also called a collection) is an object that stores data. In a sense, containers are virtual memory devices that can be structured in radical ways to allow efficient or interesting read, write, erase, and search operations.
Containers can be grouped into two categories: sequences and sets. The order of elements in a sequence is significant, while the order of elements in a set is not. For example, the sequence (a, b, c) is different from the sequence (c, b, a), while the set {a, b, c} is the same as the set {c, b, a}. Sequences also allow multiple copies of the same element, while sets do not (although a special type of set called a multiset does allow this.) For example, the sequence (a, a, b, c) is different from the sequence (a, b, c), but the set {a, a, b, c} is the same as the set {a, b, c}. Finally, a container template specifies the type of data it stores using a template parameter.
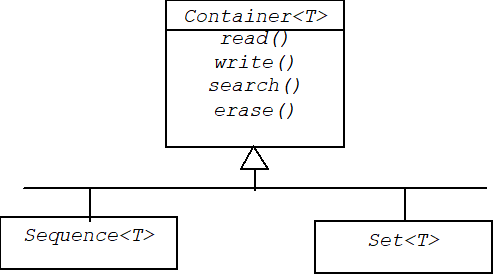
STL, the standard template library of C++, provides the following container templates:
Sequences
vector<Storable>
list<Storable>
deque<Storable>
stack<Storable>
queue<Storable>
priority_queue<Storable>
pair<Key, Storable>
Sets
map<Key, Storable>
multimap<Key, Storable>
set<Storable>
multiset<Storable>
How are these containers related to the delicate, elaborately linked structures described in data structure books? The doubly linked lists, AVL trees, and hash tables are all still there, but clients don't access them directly anymore. Instead, the container mediates between the client and the data structure. The client doesn't need to worry about memory management, broken links, re-balancing trees, or hash collisions. All of these concerns become the responsibility of the container. We can think of the container as a handle and the data structure as a body:
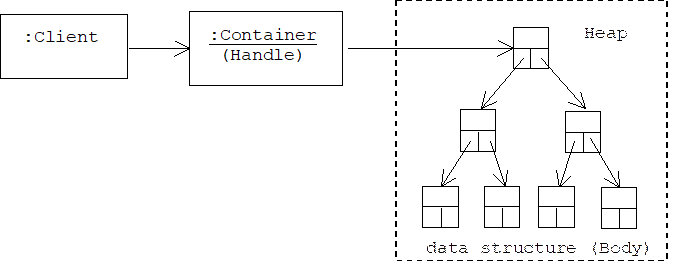
4.13
Vectors
Accessing an element of an array is more efficient than accessing an element of a linked list, while inserting or removing elements from the middle of a linked list is more efficient than inserting or removing elements from the middle of an array. Arrays have several other disadvantages. In languages like C and C++, no range checking is done on index numbers. Attempting to access an array element using an index that is out of range can lead to data corruption and program crashes. Also, unlike linked lists, the capacity of an array is fixed at compile time. For example, if we decide to represent an telephone book as an array of Person objects, then we must decide in advance the maximum size of the book:
#define MAX_FRIENDS 500 // too big? too small?
Person phoneBook[MAX_FRIENDS];
One solution to the fixed capacity problem is to use dynamic arrays. A dynamic array is allocated in the heap:
#define BLOCK_SIZE 100 // = growth increment
Person* phoneBook = new Person[BLOCK_SIZE];
If a dynamic array fills up, the program can allocate a new, larger dynamic array, transfer the elements from the old array into the new array, then delete the old array. Unfortunately, this process is error prone. We can take the responsibility of growing a dynamic array away from clients, and give it to a manager object called a vector:
Vector
Other Names
smart array, safe array, dynamic array, dynamic linear list
Problem
C arrays are error prone because neither C nor C++ provides index range checking. Also, the capacity of an array must be declared in advance, which can restrict program efficiency and usefulness. Dynamic arrays can be declared in the heap. At least they offer the possibility of runtime resizing, but the resizing procedure is error prone.
Solution
A vector is an object that encapsulates and manages a dynamic array. Vectors automatically grow when the user adds more elements than the vector's current capacity. An overloaded subscript operator verifies that indices are in range.

4.13.1 Test Program
Our test program, main() creates two integer vectors, v1 only has an initial capacity of 3 ints, while v2 has the default capacity of 100 ints:
Vector<int> v1(3), v2;
Next, main() adds 16 ints to v1, which should cause it to automatically add an extra block of 100 ints by calling v1.grow():
for(int i = 15; i >= 0; i--)
v1.push_back(i); // v1 should grow
This is verified by a diagnostic message placed in the grow() function that appears at this point during execution:
vector growing!
After assigning v1 to v2, we display v2 using the insertion operator (<<) which apparently has been extended to vectors:
v2 = v1;
cout << "v2 = " << v2 << endl;
Here is the output produced:
v2 = ( 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 )
The two vectors appear to be the same, but removing four elements from v2 has no effect on v1:
for(i = 0; i < 4; i++)
{
v2.erase(i);
cout << "v2 = "
<< v2 << endl;
}
cout << "v1 = " << v1 << endl;
Here is the output produced:
v2 = ( 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 )
v2 = ( 14 12 11 10 9 8 7 6 5 4 3 2 1 0 )
v2 = ( 14 12 10 9 8 7 6 5 4 3 2 1 0 )
v2 = ( 14 12 10 8 7 6 5 4 3 2 1 0 )
v1 = ( 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 )
Finally, our test program inserts an integer into position 1 of v1 and changes the value stored at position 2 of v1 by using the subscript operator:
v1.insert(1, 100);
v1[2] = v1[2] + 1;
cout << "v1 = " << v1;
Here is the output produced:
v1 = ( 15 100 15 13 12 11 10 9 8 7 6 5 4 3 2 1 0 )
4.13.2 Implementation
Of course STL already provides a vector template, but implementing our own is a good exercise. Because it is a template, the entire definition is placed in a header file.
// vector.h
#ifndef VECTOR_H
#define VECTOR_H
#include "d:\pop\util.h" // needed for error()
template <typename Storable> class Vector { ... };
// etc.
#endif
A vector encapsulates and manages a pointer to a dynamic array, so we'll need to use Canonical Form, which is shown in bold face:
template <typename Storable>
class Vector
{
public:
enum {BLOCK_SIZE = 100};
Vector(int
n = BLOCK_SIZE);
Vector(const
Vector<Storable>& v) { copy(v); }
~Vector() { free(); }
Vector<Storable>&
operator=(const Vector<Storable>& v);
void insert(int i, const
Storable& s);
void erase(int i);
void push_back(const Storable& s);
int getSize() const { return size; }
Storable& operator[](int i);
friend
ostream& operator<<(ostream&
os, const Vector<Storable>& vec);
private:
Storable *vals; // the dynamic array
int size; // = number of members
int capacity; // = length of vals
void
copy(const Vector<Storable>& v);
void free() { if (vals) delete[] vals;
}
void grow(); //
grows vector by BLOCK_SIZE, if needed
};
The basic constructor points vals at a newly allocated block of memory:
template <typename Storable>
Vector<Storable>::Vector(int n /* = BLOCK_SIZE */)
{
vals = new Storable[n];
capacity = n;
size = 0;
}
Of course the Canonical Form assignment operator never varies:
template <typename Storable>
Vector<Storable>&
Vector<Storable>::operator=(const Vector<Storable>& v)
{
if (&v != this)
{ // v = v is a no-op
free();
copy(v);
}
return *this;
}
The copy() function allocates a new array the size of v.vals, then performs a component-wise copy:
template <typename Storable>
void Vector<Storable>::copy(const Vector<Storable>& v)
{
capacity = v.capacity;
size = v.size;
vals = new Storable[capacity];
for(int i = 0; i < size; i++)
vals[i] = v.vals[i];
}
The subscript operator performs index bounds checking:
template <typename Storable>
Storable& Vector<Storable>::operator[](int i)
{
if (i < 0 || size <= i)
error("index out of
range");
return vals[i];
}
Notice that a reference to a storable is returned. This means we can call the subscript operator on the left or right side of assignment operators:
vec[i] = vec[i] + 1;
If necessary, grow() creates a new array BLOCK_SIZE larger than the old array, copies the old array into the new array, then deletes the old array:
template <typename Storable>
void Vector<Storable>::grow()
{
if (capacity <= size) // it's full!
{
if (DEBUG_MODE) cerr <<
"vector growing!\n";
capacity += BLOCK_SIZE;
Storable* temp = new
Storable[capacity];
for(int i = 0; i < size; i++)
temp[i] = vals[i];
delete[] vals;
vals = temp;
}
}
New items can be added to a vector using insert() or push_back(). Note that push_back() is much more efficient because insert() must move elements down to make room for the new element:
template <typename Storable>
void Vector<Storable>::insert(int i, const Storable& s)
{
if (i < 0 || size <= i)
error("index out of
range");
size++;
grow();
// move members to the right:
for(int j = size - 1; i < j; j--)
vals[j] = vals[j - 1];
vals[i] = s;
}
template <typename Storable>
void Vector<Storable>::push_back(const Storable& s)
{
size++;
grow();
vals[size - 1] = s;
}
Erase is also inefficient because it must move elements down to fill up the vacancy left by the erased member. It's better to replace items using operator[]() rather than erase them:
template <typename Storable>
void Vector<Storable>::erase(int i)
{
if (i < 0 || size <= i)
error("index out of
range");
// move members to the left:
for(int j = i; j < size; j++)
vals[j] = vals[j + 1];
size--;
}
We also provide a vector printing utility:
template <typename Storable>
ostream& operator<<(ostream& os, const
Vector<Storable>& vec)
{
os << "( ";
for(int i = 0; i < vec.size; i++)
os << vec.vals[i] << '
';
os << ")\n";
return os;
}
4.14
The
Reference Counting Idiom
In some situations handles must share bodies. For example, the body may be a unique resource, or it may be too large to be duplicated. It would seem that we would not want to use Canonical Form in these situations. If a handle deletes its body, then the other handles are left holding dangling pointers, and how can a handle copy the body of another handle if the body is a unique resource? In fact, we can use Canonical Form in this situation. The body simply keeps track of the number of handles, while Handle::copy() and Handle::free() increment and decrement this number, respectively. This is the idea behind the Reference Counting implementation pattern:
Counted Reference [POSE], [COPE]
Other Names
Counted Pointer, Reference Counting
Problem
Canonical Form can be dangerous if the handle ends up deleting a body that is referenced by other handles. This is possible when the body is a shared object. As a general rule, an object should only delete objects it creates. But what if no other objects are referencing the body? How would the handle know this?
Solution
The body can keep count of the number of handles that reference it. Each new handle that references the body should increment this count. Handles should decrement the count just before they disappear. The handle that decrements the count to zero should also delete the body.
4.14.1 Implementation
Each body includes a handle count variable that is initialized to 0. It will be the job of handles to increment and decrement this variable. For testing purposes, we also keep track of the number of bodies through a static body count variable, which is incremented and decremented by body constructors and destructors respectively (see Programming Note A.6.1). The body destructor also displays a message when it is called:
class Body
{
friend class Handle;
Body() { handleCount = 0; bodyCount++;
}
Body(const Body& b) { bodyCount++;
}
~Body() { bodyCount--; }
void serviceA() { "Body is
executing service A\n"; }
void serviceB() { "Body is
executing service B\n"; }
// etc.
int
handleCount; // = current # of handles for this body
static int bodyCount; // = current # of
bodies
};
The static body count must be defined and initialized separately.
int Body::bodyCount = 0;
The big surprise is that the Handle class still uses the Canonical Form Pattern:
class Handle
{
public:
Handle(Body*
b = 0);
Handle(const Handle& h) { copy(h);
}
~Handle() { free(); }
Handle& operator=(const Handle&
h);
void serviceA() { if (myBody)
myBody->serviceA(); }
void serviceB() { if (myBody)
myBody->serviceB(); }
// etc.
void displayCounts(); // for testing
private:
Body *myBody;
void
free();
void copy(const Handle& h);
};
Even the implementation of the assignment operator adheres to the Canonical Form Pattern:
Handle& Handle::operator=(const Handle& h)
{
if (&h != this) // h = h is a no-op
{
free();
copy(h);
}
return *this;
}
void Handle::copy(const Handle& h)
{
myBody = h.myBody;
myBody->handleCount++;
}
The free() function decrements the handle count of its associated body. If this makes the handle count zero, then the body is deleted. We print some diagnostics for testing purposes:
void Handle::free()
{
cout << "deleting a
handle\n";
if (myBody && --myBody->handleCount <= 0)
{
cout << "deleting a
body\n";
delete myBody;
}
}
The general purpose handle constructor must also increment the handle count of its body. If the body is new, this will set its handle count to one:
Handle::Handle(Body* b /* = 0 */)
{
myBody = b? b: new Body();
myBody->handleCount++;
}
For testing purposes we provide a Handle member function that displays the static body count and handle count of its associated body. Could this function be static?
void Handle::displayCounts()
{
cout << "handle count =
" << myBody->handleCount << endl;
cout << "body count = "
<< Body::bodyCount << endl;
}
Note the syntax we must use to refer to bodyCount outside of the scope of the Body class declaration.
4.14.2 Test Program
Initially, our test program, main(), creates two handles, *x and y, then asks *x to display its counts:
Handle *x = new Handle(), y;
x->displayCounts();
Here is the output produced:
handle count = 1
body count = 2
The handles are unrelated, so each has its own body, that's why the body count is two. Although there are two handles, there is only one handle attached to x->body, and that's why the handle count is one. Here's a snapshot of memory at this point:
Inside a statement block three new handles are created by copying *x and again we ask *x to display its counts:
{
Handle u(*x), v(*x), w(*x);
x->displayCounts();
}
At this point the body of *x is shared by four handles. Here's the output produced:
handle count = 4
body count = 2
Here's another snapshot of memory:

When we exit the block, handles u, v, and w are automatically destroyed, producing the output:
deleting a handle
deleting a handle
deleting a handle
After asking x to display its counts, we delete it.
x->displayCounts();
delete x;
Here is the output produced:
handle count = 1
body count = 2
deleting a handle
deleting a body
Notice that when x is deleted, the body of x is also deleted. This is because its handle count has reached 0.
Of course y's body is still undisturbed, so we can ask it to print its counts:
y.displayCounts();
Here is the output produced:
handle count = 1
body count = 1
deleting a handle
deleting a body
Notice that the body count has indeed dropped to one. How do you explain the last two lines?
4.14.3 Aliasing Problems
Sharing bodies raises the specter of the aliasing bug: If a handle modifies its associated body, then this modification is visible to all handles that share the body. In some cases this is exactly what we want. For example, if handles are documents such as company reports, memos, and web pages, and the body is a spread sheet containing the company's budget, then we probably would want changes to the budget to be instantly reflected in all of the documents that refer to it. On the other hand, if one of the documents is an internal report analyzing the effect of a proposed layoff, and if this report makes some speculative changes to the company's budget, then these changes will also be visible in all of the other documents, causing wide-spread errors and panic.
There are two ways to prevent unwanted aliasing problems. The simplest method is to forbid modifications to the body. In this case we think of the body as stateless. For example, this is the approach taken by the Java String class, which provides no methods for modifying characters once a string is created.
But what if the body is stateful? This might be an argument for not using shared bodies, but another solution is to require that each handle operation that modifies the state of its associated body (i.e., each mutator) must first create a new body. For example, let's add an integer state to our body class:
class Body
{
State
state;
State getState() { return state; }
void setState(State s) { state = s; }
Body() { handleCount = 0; bodyCount++;
state = init; }
// etc.
};
For now states are simply integers:
typedef int State;
const State init = 100; // the initial state
We also add functions to the Handle that get and set the state of the body, as well as a private body cloning function, which will be called inside every mutator:
class Handle
{
public:
State getState() const
{
if (!myBody) error("Body not
defined");
return myBody->getState();
}
void setState(State s) // mutator
{
if (!myBody) error("Body not
defined");
cloneBody();
myBody->setState(s);
}
// etc.
private:
void cloneBody(); // clones body if
needed
// etc.
};
If there are multiple handles, the handle's cloneBody() function creates a new body identical to the original body but with handle count equal to one:
void Handle::cloneBody()
{
if (1 < myBody->handleCount)
{
// clone my body
myBody->handleCount--; // release
shared body
myBody = new Body(*myBody); // clone
shared body
myBody->handleCount = 1; // clone
has 1 handle
}
}
Obviously this can be very inefficient if the body is a large structure and state changes are frequent.
4.14.3.1
Test
Program
The test program, main(), creates four handles associated with the same body, then asks x to display its counts:
Handle x, u(x), v(x), w(x);
x.displayCounts();
Here is the output produced:
handle count = 4
body count = 1
Next, x performs a state transition (i.e., it decrements its state), then x and u display their counts:
x.setState(x.getState() - 1);
x.displayCounts();
u.displayCounts();
Here is the output produced:
handle count = 1
body count = 2
handle count = 3
body count = 2
Notice that now there are two bodies. This is because cloneBody() was called. Notice that x's body has one handle, x, while u's body has three handles, u, v, and w.
Finally, main() displays the states of x and u:
cout << "x.getState() = " << x.getState()
<< endl;
cout << "u.getState() = " << u.getState() << endl;
Here is the program output produced:
x.getState() = 99
u.getState() = 100
deleting a handle
deleting a handle
deleting a handle
deleting a body
deleting a handle
deleting a body
We see that in fact the state of x's body differs from the state of y's body. How do you explain the subsequent "deleting a ..." messages?
4.14.4 Example: Garbage Collection
Memory leaks occur because C++ programmers forget to delete the heap objects they create. Memory leaks never occur in languages like Java and LISP because heap objects are automatically deleted when they are no longer needed. This process is called garbage collection. But how does a program know when a heap object is no longer needed? One solution is to use reference counting. In this case each object is regarded as a shared body with a hidden reference count variable which reflects the number of member variables and static variables that currently hold references to the object.
4.14.5 Example: ActiveX Controls
An ActiveX control is an object such as a desktop calculator or calendar that can appear in a variety of Windows applications such as Excel, Internet Explorer, Outlook, or our own custom applications. In fact, an ActiveX control may appear in several applications simultaneously. In this sense, an ActiveX control can be viewed as a server and the applications that use it as clients.
Recall that a component is an object known to its clients only through the interfaces it implements. ActiveX controls are components. In addition to the calculator interfaces our desktop calculator control implements, and in addition to the calendar interface our desktop calendar control implements, all ActiveX controls are expected to implement the IUnknow interface:
QueryInterface() allows clients to ask an ActiveX control about the other interfaces it implements. This allows new controls written by third party vendors to be added to a program dynamically.
When a client application "creates" an ActiveX control, the Windows operating system determines if the control is currently loaded in memory. If so, then a reference to the control is returned to the application. Otherwise, the control is first loaded into memory. This saves memory if many applications try to create the same control.
ActiveX controls use the Reference Counting Pattern to keep track of the number of clients they are currently servicing. When an application receives a reference to an ActiveX control, it calls the AddRef() function to increment the reference count. When it no longer needs the control, it calls the Release() function to decrement the reference count. When an ActiveX control's reference count reaches zero, it is automatically purged from memory.
4.15
Programming
Notes
4.15.1 GridGC
. This programming note provides most of the details we left out of our implementation of the GC interface.
4.15.1.1
Plotting
Borders
Recall that plotBorder() was a private utility function called by the display() method of the BorderedGC decorator:
class BorderedGC: public GCDecorator
{
public:
BorderedGC(GC* g = 0): GCDecorator(g)
{}
void display()
{
plotBorder();
GCDecorator::display(); // delegate
}
private:
void plotBorder();
};
This function simply plots each point on the left and right edges of the canvas using the stroke pen, and plots each point on the top and bottom edge of the canvas using the dash pen:
void BorderedGC::plotBorder()
{
int height = getHeight();
int width = getWidth();
for(int i = 0; i < height; i++)
{
plot(Point(0, i), strokePen);
plot(Point(width - 1, i),
strokePen);
}
for(int j = 1; j < width - 1; j++)
{
plot(Point(j, 0), dashPen);
plot(Point(j, height - 1), dashPen);
}
}
4.15.1.2
Poor
Man's Pens
We were a little vague about the definition of Pen in our description of the graphics utility classes. Normally, Pen, like GC, would be an interface or abstract class that needs to be implemented along with GC:
class Pen
{
public:
virtual ~Pen() {}
};
It would have been easy enough to provide a Poor Man's Pen implementation, but it's even easier to cheat a little and simply declare Pen as another name for char:
typedef char Pen; // Poor Man's Pen
The predefined pens are given by the following declarations:
Pen whitePen = ' ';
Pen blackPen = '*';
Pen grayPen = '/';
Pen strokePen = '|';
Pen dashPen = '-';
4.15.1.3
Poor
Man's Graphics: GridGC
As mentioned earlier, the GridGC implementation of GC defines the implicit canvas as a two dimensional array of characters. Plotting a point, (x, y), on this canvas using a pen is simply a matter of placing the character represented by the pen in row y, column x of the array:
class GridGC: public GC
{
public:
enum {rowSize = 15, colSize = 35};
GridGC()
{
clear();
}
void display();
void fill(const Pen& p);
void clear() { fill(whitePen); }
int getHeight() const { return rowSize;
}
int getWidth() const { return colSize;
}
void plot(const Point& x, const
Pen& p = blackPen)
{
// remember: (xc, yc) = canvas[yc][xc]
canvas[x.yc % rowSize][x.xc %
colSize] = p;
}
void plot(const Line& x, const
Pen& p = blackPen);
void plot(const Text& x);
private:
char canvas[rowSize][colSize];
};
Notice that the point plotting function guarantees its arguments will be within the dimensions of the canvas by taking the coordinates to be the remainder when divided by the row and column size, respectively. This will create a wrap around effect when plotting long lines. Some users may complain that they would rather see an error message when their lines go off the canvas.
4.15.1.4
Filling,
Plotting, and Displaying the Grid
Filling and displaying the canvas are done by nested for loops. The outer loop traverses the rows, while the inner loop traverses the columns:
void GridGC::fill(const Pen& p)
{
for(int i = 0; i < rowSize; i++)
for(int j = 0; j < colSize; j++)
canvas[i][j] = p;
}
void GridGC::display()
{
for(int i = 0; i < rowSize; i++)
{ //
print row i:
for(int j = 0; j < colSize; j++)
cout << canvas[i][j];
cout << endl;
}
}
Plotting text simply plots each character in the specified row beginning in the specified column:
void GridGC::plot(const Text& x)
{
int col = x.start.xc, row = x.start.yc;
for(unsigned i = 0; i <
x.text.size(); i++)
canvas[row % rowSize][col++ %
colSize] = x.text[i];
}
4.15.1.5
Plotting
Line Segments
Plotting lines is difficult. We follow a well known algorithm.
void GridGC::plot(const Line& x, const Pen& p)
{
Calculate x and y coordinates of start and end points. Also calculate the rise and run:
int xstart = x.start.xc,
ystart = x.start.yc;
int xend = x.end.xc, yend = x.end.yc;
int run = xend - xstart, rise = yend -
ystart;
Treat backward, horizontal, and vertical lines as special cases:
if (rise < 0) //
reverse direction
plot(Line(x.end, x.start));
else if (run == 0) // a vertical line
if (ystart < yend)
for(int y = ystart; y <= yend;
y++)
plot(Point(xstart, y), p);
else
for(int y = ystart; y >= yend;
y--)
plot(Point(xstart, y), p);
else if (rise == 0) // a horizontal
line
if (xstart < xend)
for(int x = xstart; x <= xend;
x++)
plot(Point(x, ystart), p);
else
for(int x = xstart; x >= xend;
x--)
plot(Point(x, ystart), p);
If the slope is gentle (i.e. less than 1) then increment by rows:
else if (abs(rise) <
abs(run))
{ //
rises slowly, so increment rows
double slope =
double(rise)/double(run);
double xc = xstart, yc = ystart + .05;
if (xstart < xend)
for( ; xc < xend; xc++, yc +=
slope)
{
//cout << Point(int(xc),
int(yc)) << ".\n";
plot(Point(int(xc), int(yc)),
p);
}
else
for( ; xc > xend; xc--, yc -=
slope)
{
//cout << Point(int(xc),
int(yc)) << endl;
plot(Point(int(xc), int(yc)),
p);
}
}
If the slope is steep, increment by columns:
else
{ //
rises quickly, so increment columns
double slope =
double(run)/double(rise);
//cout << "SLOPE = "
<< slope << endl;
double xc = xstart + .05, yc =
ystart;
if (ystart < yend)
for( ; yc < yend; yc++, xc +=
slope)
{
//cout << Point(int(xc),
int(yc)) << endl;
plot(Point(int(xc), int(yc)),
p);
}
else
for( ; yc > yend; yc--, xc -=
slope)
{
//cout << Point(int(xc),
int(yc)) << endl;
plot(Point(int(xc), int(yc)),
p);
}
}
}
4.16
Problems
4.16.1 Problem
Our drawing program is a bit unrealistic. For example, we don't offer much detail on how a pen or a character knows which virtual canvas its associated with. Using pseudo code or class diagrams, sketch a way that this association could be made more explicit.
4.16.2 Problem
Re-implement Pen::move(Heading dir, int pixels) so that it preserves the Pen class' invariant condition.
4.16.3 Problem
Assume we define the following subclass of the Pen class defined at the beginning of the chapter:
class ColoredPen: public Pen
{
public:
enum Diagonal { POSITIVE, NEGATIVE };
void setColor(int r, int g, int b)
{
red = r; green = g; blue = b;
}
void move(Diagonal diag, int pixels);
private:
int red, green, blue; // color
components
};
where:
0 <= red, green, blue < 256
and where the new move() function moves pens along positively or negatively sloped diagonals:
void ColoredPen::move(Diagonal diag, int pixels)
{
Pen::move(NORTH, pixels);
if (diag == POSITIVE)
Pen::move(EAST, pixels);
else
Pen::move(WEST, pixels);
}
Describe the state space, transitions, and invariant condition for ColoredPen.
How are these related to the state space, transitions, and invariant condition for Pen?
In general, what should be the relationship between the state space, transitions, and invariant condition of a subclass and the state space, transitions, and invariant condition of its super class?
4.16.4 Problem
Recall the Text class defined at the beginning of the chapter:
class Text
{
public:
virtual void display(int x, int y) = 0;
// etc.
protected:
const string text;
};
Instead of thinking of font as a state, suppose we think of it as a subclass of Text. For example, here is how we might define text that uses Roman font:
class RomanText: public Text
{
public:
void display(int x, int y)
{
// display text in Roman at position
(x, y)
}
// etc.
};
Compare this approach with the approach taken in the text using the State Pattern.
4.16.5 Problem
Finish the implementation of the Investment Strategy example. Device a test harness that creates a number of investments and a number of portfolios that use different investment strategies. Compare the expected values of these portfolios.
4.16.6 Problem
Complete the "Poor Man's" implementation of GC. Test your implementation using the same test program used in the book.
4.16.7 Problem
Add an inner class for bi-directional iterators to the Vector template defined earlier:
template <typename Storable>
class Vector
{
class Iterator
{
public:
Iterator(const
Vector<Storable>* v, int j = 0) { ... }
Iterator operator++() { ... }
Iterator operator--(int) { ... }
bool operator==(Iterator it) const {
... }
bool operator!=(Iterator it) const {
... }
Storable operator*() { ... }
private:
const
Vector<Storable>* myVector;
int i; // myVector[i] = selected
member
};
friend class Iterator;
Iterator begin() { ... }
Iterator end() { ... }
// etc.
};
Why is the unused int parameter necessary in operator—()? Create a test driver to test your implementation.
4.16.8 Problem
STL's list template enacpsulates and manages a linked list. But before STL, programmers had to implement their own linked lists!
List
Other Names
linked list
Problem
In some situations random insertion and removal is more common than random access. These operations are very inefficient for arrays and vectors.
Unlike arrays and vectors, linked lists decouple physical and logical order. The items in a linked list are not stored in consecutive memory locations. Instead, a linked list is a collection of cells or nodes. Each cell contains a single data item plus pointers to its logical neighbors. Here's how the sequence ( 22 32 42 52 ) is represented as a doubly linked lists:
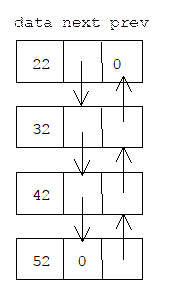
There are other styles of linked lists including singly linked lists, circularly linked lists, lists with header nodes, and sorted linked lists (these are useful for priority queues).
Unfortunately, inserting and removing cells is error prone. Programmers must take care to re-link the list and delete unused cells.
Solution
A list container is a handle that manages a linked list (the body). Actually, the handle has two bodies, the first and last cell of a doubly linked list. Besides managing the linked list, the handle provides erase() and insert() member functions.
Static Structure
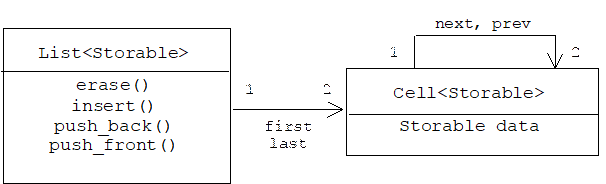
Implement a list template. You'll need to use Canonical Form and you'll need to provide Cell and Iterator inner classes:
template <typename Storable>
class List
{
public:
class Cell { ... };
class Iterator { ... };
Iterator begin() { ... }
Iterator end() { ... }
void erase(Iterator p);
void insert(Iterator p, const Storable
i);
void push_front(const Storable i);
void push_back(Storable i);
bool empty();
// etc.
private:
Cell *first, *last;
// etc.
};
The inner Cell class maintains pointers to its neighbors and a data item:
class Cell
{
friend class List<Storable>;
Storable data;
Cell* next;
Cell* prev;
// etc.
};
4.16.9 Problem
In addition to the Storable type, STL templates are also parameterized by an allocator for allocating and deallocating members of the Storable type. Programmers don't usually see this parameter because STL specifies a default argument, allocator<Storable>, which allocates and deallocates storables from the system heap.
Allocator
Other Names
Magic Memory Idiom
Problem
For some applications the system heap may be inadequate. For example, an application may require garbage collection and heap compactification. Another application may require the efficiency of a first-fit allocation policy, or, if heap fragmentation is a concern, the slower best-fit allocation policy may be needed. Such allocation policies are necessary for heaps that can allocate variable size blocks of memory, but this isn't needed at all for allocating the fixed-size cells of a linked list.
Solution
An allocator encapsulates and manages a heap. An allocator can be provided to a class that requires a special type of heap. By redefining the new() and delete() operator to delegate to the allocator, we can make the custom heap transparent to clients.
Static Structure

Add an allocator to the Cell inner class from the previous exercise:
class Cell
{
void init(Storable i, Cell* cp = 0, Cell*
cn = 0)
{
data = i;
next = cn;
prev = cp;
}
friend class List<Storable>;
friend class Iterator;
Storable data;
Cell* next;
Cell* prev;
void* operator new(size_t bytes) //
size_t defined in <stddef.h>
{
if (bytes != sizeof(Cell))
error("Wrong size!");
return myHeap->allocate();
}
void operator delete(void* p)
{
myHeap->deallocate((Cell*)
p);
}
static
Allocator<Cell>* myHeap;
};
Our allocator will maintain a list of free cells. A free cell is a block of memory that may either hold an unallocated cell or a pointer to the next free cell on the list. We can represent a free cell as a union. Unfortunately, Visual C++ does not allow union members to have programmer-defined constructors. This is why we provided the Cell::init() function to initialize cells.
template <typename Type>
class Allocator
{
public:
enum { NCELL = 100 };
union FreeCell
{
Type item;
FreeCell* next;
};
Allocator(int n = NCELL);
Type* allocate();
void deallocate(Type* c);
private:
FreeCell* freelist;
};
Complete the exercise by implementing allocate() and deallocate(). Be sure to test your implementations.
4.16.10 Problem: Non-Mutable Strings
Java regards strings to be unique, non-mutable objects. For example, if s is a Java string:
String s = "cat";
we can't change its individual characters:
s[0] = 'r'; // error!
Although LISP strings are mutable, LISP provides a separate type called symbols, which are like strings, but which are guaranteed to be unique and non-mutable:
(define s1 'cat)
(define s2 'cat) // s1 & s2 point to the same symbol!
We can use reference counting to represent non-mutable strings in C++. In this case the strings clients manipulate are really handles that encapsulate pointers to string bodies.
class String
{
public:
char operator[](int i);
int getSize();
// etc.
private:
StringBody* myBody;
// etc.
};
A string body encapsulates a C++ string:
class StringBody
{
char getChar(int i); // return char at
position i;
string theString;
// etc.
};
Complete and test the implementations of String and StringBody using the reference counting idiom. getChar() should check the range of the index by catching the exception thrown by theString when i is out of range.
Re-implement String and StringBody assuming StringBody::getChar() and String::operator[] return char&. Be careful, now users can modify characters within a string.
4.16.11 Problem: Generic Numbers
Handles delegate to bodies. When a handle also specializes a body[4] we call the body a letter and the handle an envelope. In this case the Handle-Body idiom is called the Envelope-Letter idiom. (See [COPE].) The envelope defines a generic type (like curve, surface, or complex number). The envelope encapsulates a pointer to a particular representation, called the letter (like conic section, revolute, or polar). Envelope constructors and factory methods deduce the type of letter to create from their parameters and contexts. Envelope member functions are always virtual and always delegate work to member functions of the same name in the letter class. Thus, the typing system does most of the work for us.
There are many types of numbers: integer, rational, real, and complex. Although all types of numbers may be needed by our clients, our clients may only be interested in using generic numbers, leaving the representation details to us on a case by case basis. Here is an example of client code that uses generic numbers:
#include "number.h"
int main()
{
Number n1(3, 4), n2(5.0, 6.0);
cout << "n1 = "
<< n1 << endl;
cout << "n1 = "
<< n2 << endl;
Number n3 = n1 + n2;
cout << "n3 = "
<< n3 << endl;
Number n4(3.1416);
Number n5(42);
cout << "n4 = "
<< n4 << endl;
cout << "n5 = "
<< n5 << endl;
n3 = n1 + n4;
cout << "n3 = "
<< n3 << endl;
n3 = n2 + n5 + n1;
cout << "n3 = "
<< n3 << endl;
return 0;
}
Here is the program output. Notice that n3 started out as the complex number 5.75+6i, the result of adding ¾ and 5+6i, but later n3 became the real number 3.8916, the result of adding ¾ and 3.1416. Finally, n3 becomes a complex number once again, this time 47.75+6i:
n1 = 3/4
n2 = 5+6i
n3 = 5.75+6i
n4 = 3.1416
n5 = 42
n3 = 3.8916
n3 = 47.75+6i
We can use the Envelope-Letter idiom to implement the Number class. In this case Number is the envelope class, while Rational, Complex, Real, and Integer are the letter classes:
The interesting feature of the Envelope-Letter idiom is that the letter classes inherits from the envelope class, while the envelope class delegates to the letter class. Here's an object diagram showing the first two numbers created in the example above:

Assume n1 and n2 are as in the example above. Assume Rational(*(n1.letter)) = r1 is actually an instance of Rational, and Complex(*(n2.letter)) = c2, an instance of Complex. We use the C++ typing system to delegate the calculation of n1 + n2 to c2 + r1:
Note that the actual addition can only be preformed in c2 + r1, where the specific representation of c2 and r1 is known. Also note that our addition operators are not commutative. We use the argument order to determine which variant to call.
The implementation isn't difficult, but involves writing a lot of code. Most of the member functions merely delegate to the corresponding member functions of the letter. To do this, it is important that these functions are virtual and that letter is a pointer. Otherwise, infinite recursions result. You'll need some declarations at the top of number.h:
// number.h
#include <iostream>
using namespace std;
class Token {};
class Rational;
class Complex;
class Integer;
class Real;
The bad news is that each arithmetic operation (+, *, /, -) requires five member functions in the Number base class. (Total = 4 * 5 = 20.) One to be used when *this is the first operand, the others to be used when *this is the second operand. In this case the parameter type tells us the letter type of the first argument. The good news is that the code of each of the five member functions is exactly the same: return *letter + n; This is because operator+() is heavily overloaded in the derived classes.
// the envelope class
class Number
{
public:
// constructors
Number(int n, int d); // letter = a
Rational
Number(double rp, double ip);
Number(int n);
Number(double d);
// addition functions
// hint: all five have the same body!
// used when this is the first operand
virtual Number operator+(const
Number& n) const;
// used these when this is the second
operand
virtual Number operator+(const
Complex& n) const
virtual Number operator+(const
Rational& n) const
virtual Number operator+(const
Real& n) const
virtual Number operator+(const
Integer& n) const
// multiplication
// subtraction
// division
friend ostream&
operator<<(ostream& os, const Number n);
virtual void printNumber(ostream&
os) const
{
letter->printNumber(os);
}
protected:
// Used to init base part of *letter.
Number (Token t) { letter = 0; }
private:
Number* letter; // points to a Complex,
Real, etc.
}; // Number
Note the protected constructor expecting a parameter of type Token, where Token is the bogus empty class defined earlier. This is the constructor used by the derived classes, but never other clients, to create an extension (i.e. not generalization) of type Number. Using the other constructors would result in an infinite regress of specializations creating generalizations, creating specializations, etc.
Each derived class must over ride the 4 * 5 = 20 virtual arithmetic operators defined in the Number base class. (There are four derived classes, which means 4 * 20 = 80 member functions! This is a bit much, but it is still a great exercise in C++. Can you think of any short cuts using macros, templates, etc.?)
class Complex: public Number
{
public:
Complex(double rp, double ip): Number(Token())
{
realPart = rp;
imPart = ip;
}
// used when this is the first operand
Number operator+(const Number& n)
const
{
return n + *this;
}
// used when this is the second operand
// this is where the math is
Number operator+(const Complex& x)
const;
Number operator+(const Rational& x)
const;
Number operator+(const Integer& x)
const;
Number operator+(const Real& x)
const;
// Multiplication
// Division
// Subtraction
void printNumber(ostream& os) const
{
os << realPart << '+'
<< imPart << 'i';
}
double getImPart() const{ return
imPart; }
double getRealPart() const{ return
realPart; }
private:
double realPart, imPart;
};
The other classes are similar. Rational encapsulates two integers representing the numerator and denominator, Real encapsulates a double, and Integer encapsulates an int:
class Rational: public Number { ... };
class Real: public Number { ... };
class Integer: public Number { ... };
Implementation of Number constructors must be separated from their declaration, because at the time of declaration, we didn't know what type of derived class constructors would be available to us. For example, the Number constructor receiving two ints, n and d, must define letter = new Rational(n, d).
#include "number.h"
// define Number constructors here
ostream& operator<<(ostream& os, const Number n)
{
n.printNumber(os);
return os;
}
Recall that the actual mathematics can only be implemented when the derived types of both arguments are known. Here's an example. At this point we know the implicit parameter is complex and the explicit parameter is rational. In this case we must transform the rational x into a double by dividing its numerator by its denominator. The result, x2, is added to the real part of the implicit parameter. The answer is a new complex number made this sum and the imaginary part of the implicit parameter. (Adding a real, rational, or int to a complex number doesn't effect its imaginary part.)
Number Complex::operator+(const Rational& x) const
{
double x2 =
double(x.getNum())/double(x.getDen());
return Number(realPart + x2, imPart);
}
Complete the implementation of generic numbers. You don't have to implement division and subtraction, but do finish addition and multiplication.
Create a test harness (main) to test your implementation. The test harness should only refer to the Number type, never the derived types.
4.16.12 Problem: Printing STL Stacks and Queues
Printing and traversing stacks and queues can be difficult because the adaptee container, always called c, is a protected member.
template <typename T, typename C = deque<T> >
typename queue
{
protected:
C c; // my adaptee
public:
void pop() { c.pop_front(); }
// etc.
};
The only way around this is to subclass queue<Item>, so c becomes visible. We can call our derived class queue<>, too, if we leave the STL queue<> and deque<> names in the std namespace.
Create and test a writer for deques:
template <typename Storable>
ostream& operator<<(ostream& os, const std::deque<Storable>& v)
{ ??? }
Create a queue template class that is derived from the STL queue template. Your template should provide a getContainer() member function that returns the adaptee container:
template <typename Storable>
class queue: public std::queue<Storable>
{
public:
std::deque<Storable>
getContainer() const;
};
If this works, then implement the following function can be used to print the queue:
template <typename Storable>
ostream& operator<<(ostream& os, const queue<Storable>&
s)
{???}
Repeat the exercise for STL stacks.
4.16.13 Problem: Chain of Responsibility
The chain of responsibility pattern, which is similar to the decorator pattern, simplifies the formation of delegation chains:
Chain of Responsibility [Go4]
Problem
A client passes a message to some message handler object. But this message handler may not be able to understand or completely handle the message.
Solution
Each message handler should have a message handler successor to which it can delegate unhandled or partially handled messages. In this way message handlers can be chained together.
4.16.13.1 Static Structure
An abstract handler base class consists of a virtual handleMsg() function and maintains a reference to the next handler in the chain:
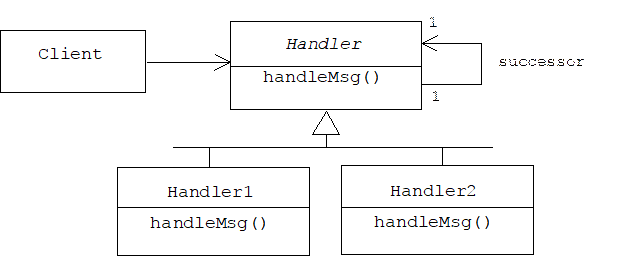
4.16.13.2 Implementation
A C++ handler class maintains a protected pointer to the next message handler in the chain:
class Handler
{
public:
Handler(Handler* s = 0) { successor =
s; }
virtual void handleMsg(const
Message& msg)
{
if (!successor) error(unrecognized +
msg);
successor->handleMsg(msg);
}
protected:
Handler* successor;
};
Where:
typedef string Message; // for now
Message unrecognized = "unrecognized message: ";
Each concrete message handler can partially handle its message, then forward it to its successor. For example:
void Handler1::handleMsg(const Message& msg)
{
// partially handle msg here:
if (msg == msg1) handleMsg1();
else if (msg == msg2) handleMsg2();
else if (msg == msg3) handleMsg3();
// etc.
// then (or else) delegate to
successor:
Handler::handleMsg(msg);
}
We can use the chain of responsibility pattern to create an object system based on delegation rather than specialization. Our system is similar to the Scheme Object System (SOS) developed in [PEA]. First, rename the Handler class the Object class. Our objects communicate by message passing:
send(&object, message);
where send() is a global function:
inline void send(Object* obj, const Message& msg)
{
obj->handleMsg(msg);
}
So the successor of an object serves as its generalization.
Use the chain of responsibility pattern to develop a simplified Grid hierarchy:
send(&grid, "show"); // writes grid to cout
send(&grid "clear"); // clears grid
send(&grid, "plot 3 4 *"); // plots character * in row 3 column 4
send(&grid, "hplot 3 4 hello"); // horizontally plots
"hello"
// starting in row 3 column 4
Build and test your implementation.