1 Foundations
1.1 Software Engineering
1.1.1 Stakeholders
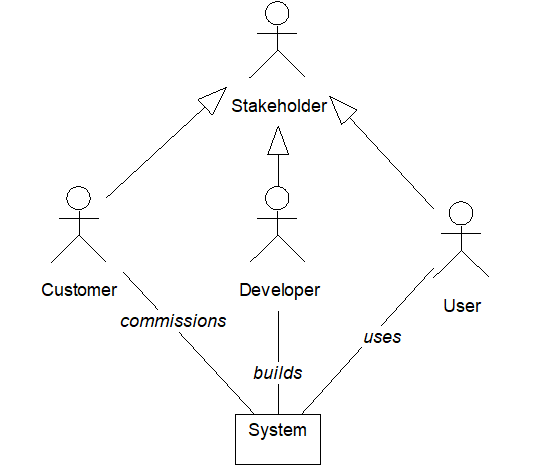
Stakeholders are the people or organizations interested in the outcome of a software project. The customer commissions the system. The developer builds the system. The users use the system.
1.1.2 Phases/Artifacts/Tools
1.1.2.1 Analysis/Specification/CASE
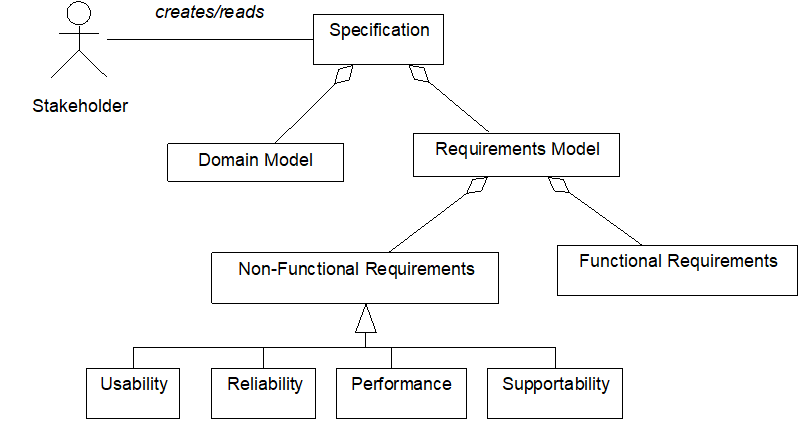
The specification is a document contains the requirements model and the domain model. The requirements model includes functional requirements (capabilities) and non-functional requirements (constraints).
Functional requirements are often described with UML use case and sequence diagrams. Here's an example of an initial use case diagram for an email client:

Non-functional requirements include:
Usability
Impedence mismatch with
existing workflows
UI conventions
online help
documentation
Reliability
mean-time between
failures
fault tolerance/robustness
safety
Performance
Response time
Throughput
Availability
Accuracy
Supportability
How easy will it be to add new features? fix bugs?
The application domain is the real-world context of the application. This includes the various systems and users the application interacts with. It also includes important business concepts (roles, events, entities, descriptions), rules, and processes that the application must know about. UML class, object, deployment, sequence, and activity diagrams are used to describe the application domain. For example, here's an initial model of a hospital domain:

Analysis patterns are reusable fragments of application domain models.
Computer Aided Software Engineering (CASE) tools are often used to create UML diagrams during the analysis and design phases.
1.1.2.2 Design/Architecture/CASE
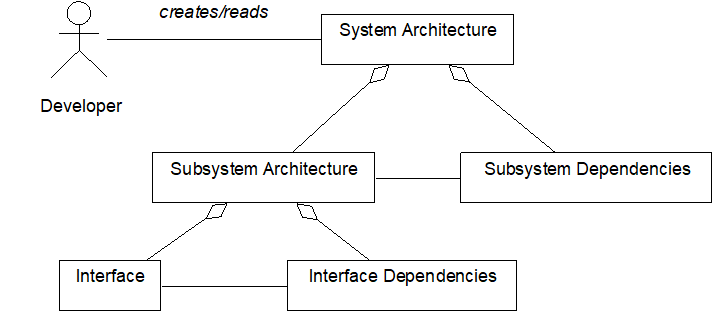
Following the specification, the system architecture is developed during the design phase. This document describes the major subsystems and their dependencies. Within a subsystem important interfaces, global functions, classes, and sub-subsystems are described as well as the relationships between them. Package, class, and sequence diagrams are used to model the system architecture.
1.1.2.3 Implementation/Source/IDE & SCCS
The subsystems, functions, classes, and interfaces described in the system architecture are implemented during the implementation phase.
Integrated Development Environments (IDEs) integrate compilers, linkers, editors, and debuggers. Some IDEs can interface with source code control systems (SCCS) that manage different versions of the source code files.
1.1.2.4 Testing/Tests/Testing Frameworks
There are two types of testing: functional and structural. Structural testing often takes the form of a review in which a group of people inspects the source code line by line.
Functional testing focuses on system behavior rather than system structure. Each function/method has an associated function test that feeds the function a set of inputs, and then compares the outputs with the expected outputs. The expected outputs are provided by a table called an oracle. The test fails if one or more of the actual outputs differs significantly from the expected output.
Running a class test runs the function tests for each method. The class test fails if any of the method tests fails.
Running a subsystem test runs the class tests for each class in the subsystem. The subsystem test fails if any of the class tests fail.
Running a system test runs each subsystem test. The system test fails if any of the subsystem tests fail.
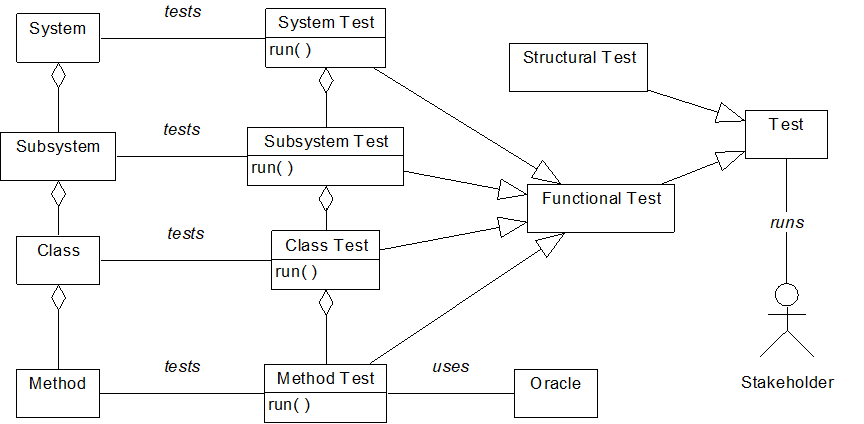
Testing frameworks are often used to automate the organization and running of tests.
Structural testing reveals many more bugs than functional testing.
Functional testing is good for regression testing.
1.1.2.5 Maintenance/Releases/CM
During the maintenance phase releases or builds are produced and distributed to the users. Configuration management tools such as make and ant are used to manage the configurations and versions of various releases.
The main types of maintenance include corrective maintenance (fixing bugs), adaptive maintenance (interfacing with or porting to new systems), and perfective maintenance (adding new features).
Studies show that the maintenance phase is the most expensive. Perfective maintenance is the most expensive type of maintenance.
1.1.3 Processes
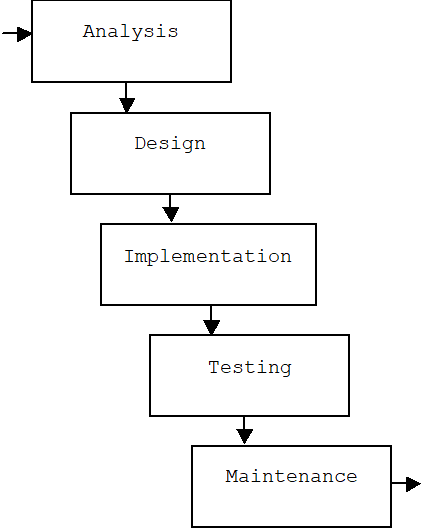
1.1.3.1 The Waterfall
In the traditional waterfall method one phase follows another. Returning to a phase after it is complete is not allowed. This prevents feature creep-- the tendency for customers to add new requirements late in the development process.
1.1.3.2 Iterative-Incremental Development
There are two flaws with the Waterfall model. First, change is inevitable. It's nearly impossible to anticipate all of the system requirements before design and implementation. Second, the riskiest phase, testing, occurs late in the process.
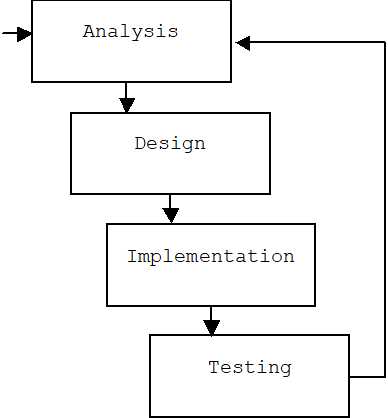
Iterative-Incremental processes such as Model-Driven Development (MDD) and Rational Unified Process (RUP) are organized into short 2 - 3 week development cycles called iterations. During an iteration each artifact is extended. The extension is called an increment.
During early iterations the riskiest requirements can be specified, designed, implemented, and tested. This places risk near the beginning of the process.
There is no need for a maintenance phase because there is no preset limit to the number of iterations that can be performed; new features can be added in new iterations:
1.1.3.3 Agile Development
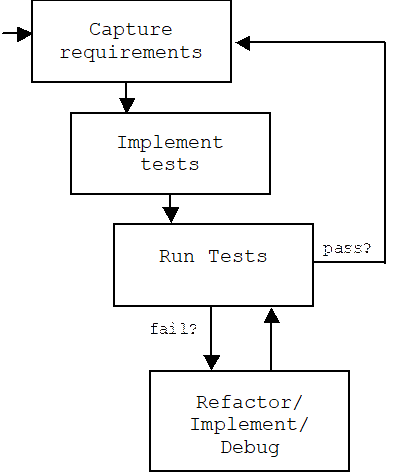
Agile methodologies such as Extreme Programming (XP), Test-Driven Development (TDD), and Agile Model-Driven Development (AMDD) are iterative-incremental processes that de-emphasize big up front designs. Instead, design comes late in the process in the form of refactoring (techniques for redesigning existing code).
1.2 Modeling
In model-driven methodologies the primary analysis and design artifacts are models. In MDD the models are so detailed that code can be automatically generated from them. In AMDD the models are only good enough to support the implementation phase.
Models are almost always diagrams. In most cases the models are UML diagrams.
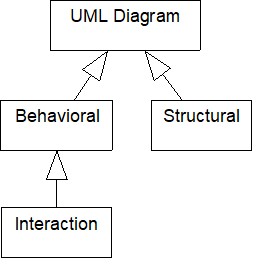
The UML 2.0 (Unified Modeling Language) is now an Object Management Group (OMG) standard. It specifies two classes of diagrams: behavioral and structural. Interaction diagrams are a special subset of behavioral diagrams:
There are currently 13 types of diagrams:
Behavior diagrams. A type of diagram that depicts behavioral features of a system or business process. This includes activity, state machine, and use case diagrams as well as the four interaction diagrams.
Interaction diagrams. A subset of behavior diagrams that emphasize object interactions. This includes communication, interaction overview, sequence, and timing diagrams.
Structure diagrams. A type of diagram that depicts the elements of a specification that are irrespective of time. This includes class, composite structure, component, deployment, object, and package diagrams.
1.3 Packages
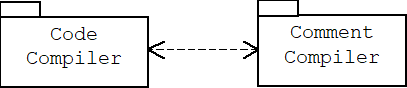
A package is a named set of related global functions, classes, interfaces, and sub-packages. A UML package diagram shows a system's important packages and their dependencies. Packages appear in these diagrams as labeled folders called package icons. A dependency is a dashed arrow pointing from an importer package to an exporter package, and indicates that changes to the exporter package may force changes to the importer package.

For example, the following package diagram indicates that components in the Business Logic package import (use) components defined in the Database package, while components in the User Interface package import components defined in the Business Logic package. Of course some of these components may have been imported by the Business Logic package, so the dependency relationship is transitive.

In a unidirectional dependency the exporter is also called the provider or server, while the importer is called the client. In a bi-directional dependency both packages are called peers:
1.3.1 Packages in C++
Packages can be implemented in C++ using names spaces:
namespace Database
{
class Query { ... };
class Table { ... };
// etc.
}
namespace BusinessLogic
{
using namespace Database;
class Transaction { ... };
class Customer { ... };
// etc.
}
namespace UserInterface
{
using namespace BusinessLogic;
class DialogBox { ... }
class Menu { ... };
// etc.
}
1.3.2 Packages in Java
Java programmers place a package declaration at the top of every .java file that contains declarations of classes that are to be included in the package:
package NAME;
For example, the Query class is defined in the file Query.java and is part of the dbase package. The first non-comment line of Query.java is the package declaration:
// file: myApp\dbase\Query.java
package dbase; // package declaration
public class Query {
public Query() {
System.out.println("Constructing
a query");
}
public void execute() { /* etc. */ }
// etc.
}
As the folder-shaped package icon suggests, there is a close correspondence between packages and file system directories. This correspondence is made explicit in Java. All .java files (and corresponding .class files) that belong to the dbase package reside in a directory called dbase. On my (Windows ME) system, dbase is a subdirectory of a directory called myApp, which will contain all of the packages of a mythical application called App.
The Transaction class is defined in a file called Transaction.java and belongs to the business package:
// file: myApp\business\Transaction.java
package business;
public class Transaction {
public Transaction() {
System.out.println("Constructing
a transaction");
}
public void commit() { /* etc. */ }
// etc.
}
Naturally, Transaction.java and Transaction.class belong to the business subdirectory of the myApp directory.
The user interface package (ui) is more interesting. In addition to classes, it contains two sub-packages: view and control. The view package contains classes that deal with system output, while the control package contains classes that deal with system input. The name of a Java sub-package is always qualified by the name of its super-package:
PACKAGE.SUB-PACKAGE.SUB-SUB-PACKAGE.SUB-SUB-SUB-PACKAGE
For example, the Window class belongs to the ui.view package:
// file: myApp\ui\view\Window.java
package ui.view;
public class Window {
public Window() {
System.out.println("Constructing
a window");
}
public void show() { /* etc. */ }
// etc.
}
While the (Message) Broker class belongs to the ui.control package:
// file: myApp\ui\control\Broker.java
package ui.control;
public class Broker {
public Broker() {
System.out.println("Constructing
a message broker");
}
public void pumpMessages() { /* etc. */
}
// etc.
}
All of the ui.view files reside in the view subdirectory of the myApp\ui directory. All of the ui.control files reside in the control subdirectory of the myApp\ui directory.
The entry point for App is the main() method of the App class, which is defined in the App.java file. This class is not part of any named package. Instead, it belongs to the default package:
// file: myApp\App.java
import dbase.*;
public class App {
private Query q;
private business.Transaction t;
private ui.view.Window w;
private ui.control.Broker b;
public App() {
w = new ui.view.Window();
b = new ui.control.Broker();
t = new business.Transaction();
q = new Query();
w.show();
b.pumpMessages();
}
public static void main(String[] args)
{
App a = new App();
}
}
Notice that all references to classes outside of the default package must be qualified by the full names of their packages. For example we must write:
private ui.view.Window w = new ui.view.Window();
The exception is the Query class. This appears without qualification because of the import statement at the top of App.java:
import dbase.*;
In effect, this directs javac (the Java compiler) and java (the Java VM) to search the dbase package for all classes not found in the default package.
Of course the translation from a qualified package name to a Windows or Unix path name is trivial (replace '.' by '\' or '/'), but the resulting path name is relative. How do java and javac translate a relative path name into an absolute path name? The answer is that they search for these relative paths in all directories listed in the CLASSPATH and PATH environment variables. Thus, if the absolute paths p1, p2, and p3 appear in the CLASSPATH variable, and if q is a relative path corresponding to a package name, then Windows versions of javac and java will search p1\q, p2\q, and p3\q for the corresponding .class files it requires. Usually ., the working directory is listed in PATH or CLASSPATH, so the default package will automatically be searched, too.
1.4 Class Diagrams
A class diagram shows classes and their relationships. In the context of a domain model, classes correspond to application domain concepts such as roles, entities, events, and descriptions. In the context of an architectural model classes represent internal representations of domain concepts as well as supporting components such as controllers and user interface components.
The following class diagram shows four classes: Organization, Employee, SalariedEmployee, and HourlyEmployee.
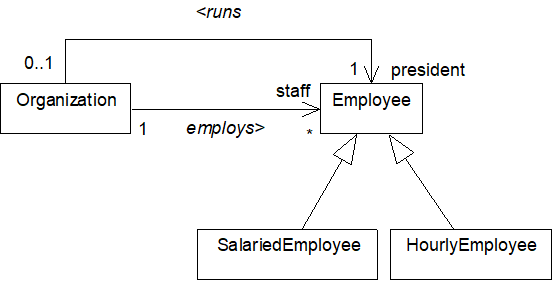
The generalization/specialization arrows (triangular head) indicate that SalariedEmployee and HourlyEmployee are derived from or extend Employee and hence are subclasses of Employee. In other words, references to hourly or salaried employees can appear in contexts where references to employees are expected. To facilitate this interpretation a subclass automatically inherits the features of a super class.
A code generator (human or computer) might generate the following Java code from this diagram:
class Employee { ... }
class HourlyEmployee extends Employee { ... }
class SalariedEmployee extends Employee { ... }
Here is the corresponding C++ code:
class Employee { ... };
class HourlyEmployee: public Employee { ... };
class SalariedEmployee: public Employee { ... };
1.4.1 Associations
The two association arrows (barbed head or headless) model the relationships:
X employs Y
and
Y runs X
where X is an instance of the Organization class and Y is an instance of the Employee class.
The employs relationship is a one-to-many (1:*) relationship. In other words, an organization employs many employees, but an employee is employed by only one organization. The runs relationship is one-to-at-most-one relationship (1:0..1). In other words an organization has one president, and an employee is president of zero or one organizations.
The arrowhead indicates that an organization knows the identity of its employees and president. The absence of a reverse arrowhead tells us that an employee may not know the identity of the organization he works for or runs. Navigational arrowheads are often drawn during the design phase for pragmatic reasons.
A code generator might produce the following Java implementation of Organization:
class Organization {
private static final int CAPACITY =
100;
private Employee[] staff = new
Employee[CAPACITY];
private int size = 0; // = # of
employees
private Employee president;
public Organization() { }
public void add(Employee e) {
if (size < CAPACITY)
staff[size++] = e;
}
public Employee getEmployee(int i) {
if (i <= 0 || CAPACITY <= i)
return null;
return staff[i];
}
public void remove(Employee e) {
boolean found = false;
for(int i = 0; i < size; i++) {
if (found) staff[i-1] = staff[i];
if (e.equals(staff[i])) found =
true;
}
if (found) size--;
}
public Employee getPresident() { return
president; }
public void setPresident(Employee e) {
president = e; }
// etc.
}
Notice that our code generator generated lots of bookkeeping member functions to support the member variables. This includes getter and setter methods for non-collections and add, remove, and access methods for collections. Bookkeeping methods also include constructors and a destructor.
Alternatively, the code generator might take advantage of the Java Collections Framework:
class Organization {
private Set<Employee> staff = new
HashSet<Employee>();
private Employee president;
public Organization() { }
public void add(Employee e) {
staff.add(e); }
public void remove(Employee e) { staff.remove(e);
}
public Iterator iterator() { return
staff.iterator(); }
public Employee getPresident() { return
president; }
public void setPresident(Employee e) {
president = e; }
// etc.
}
Here is a C++ implementation that takes advantage of STL:
class Organization
{
private:
set<Employee*> staff;
Employee* president;
public:
typedef set<Employee*>::iterator
iterator;
Organization() { }
virtual ~Organization() { }
void add(Employee* e) {
staff.insert(e); }
void remove(Employee* e) { staff.erase(e);
}
iterator begin() { return
staff.begin(); }
iterator end() { return staff.end(); }
Employee* getPresident() const { return
president; }
void setPresident(Employee* e) {
president = e; }
// etc.
};
Here is how a client might display each staff member of an organization
Organization acme;
for(int i = 0; i < 1000; i++)
acme.add(new Employee());
Organization::iterator p;
for(p = acme.begin(); p != acme.end(); p++)
cout << **p << '\n';s
Of course this code assumes cout << e is defined for e an instance of Employee.
1.4.2 Aggregation
Aggregation is a special type of association that can be used to model whole-part relationships:
X is part of Y
An aggregation arrow has a hollow diamond on the whole end:
![]()
For example:
![]()
In C++ we face the issue of whether assemblies should contain components by value or by reference:
class Car
{
Engine* engine; // containment by
reference
};
class Engine
{
Piston piston[8]; // containment by
value
};
In general, value/copy semantics can raise sticky implementation issues. For example, it's possible that several copies can be made of an object in a program that represents some object in the application domain. If this object has a modifiable state, then it's possible that the copies eventually disagree about the state of the domain object that they represent. This leads to synchronization and consistency problems.
1.5 Attributes and Operations
In UML we can also specify attributes and operations for a class. The following class icon tells us that an instance of the Account class has two attributes: balance and password. In addition, there are four operations deposit(), withdraw(), authorized(), and test(). The underline indicates that test() is a static operation:

We can even specify the types and visibilities of the attributes and operations:

The visibility qualifiers are:
+ = public
# = protected
~ = package
- = private
The attribute and association access constraints I use are:
{+r/+w} = read/write = the default
{+r/-w} = read-only
{-r/+w} = write only
{-r/-w} = no read, no write
These constraints control the generation of getter and setter methods for non-collections and add, remove, and iterate methods for collections.
Here is the C++ implementation our code generator might produce:
class Account
{
private:
float balance;
string password;
protected:
bool authorized(string pwd);
public:
Account(float balance = 0.0, string pwd
= "?")
{
this->balance = balance;
this->password = password;
}
float getBalance() const { return
balance; }
void deposit(float amt);
void withdraw(float amt);
static bool test();
};
Notice that C++ doesn't support members with package or namespace scope.
Of course the implementations of the operations are empty:
bool Account::authorized()
{
// stub
return true;
}
Notice that balance is a read-only attribute, while password is totally hidden from clients.
Here is a Java implementation:
class Account {
private float balance = 0;
private String password =
"?";
protected boolean authorized(String
pwd) {
// stub
return true;
}
public Account(float balance, String
password) {
this.balance = balance;
this.password = password;
}
public Account(float balance) {
this(balance, "?"); }
public Account(String password) {
this(0.0f, password); }
public Account() { this(0.0f); }
public float getBalance() { return
balance; }
public void deposit(float amt) { /*
stub */ }
public void withdraw(float amt) { /*
stub */ }
static boolean test() {
// stub
return true;
}
}
Notice that test uses the default package visibility. Also notice how the absence of default arguments in Java requires us to implement many constructors.
Don't confuse attribute, field (member variable), and association. An association is usually represented as a field. An attribute may or may not be represented as a field. For example, a rectangle may have length, width, and area as attributes:
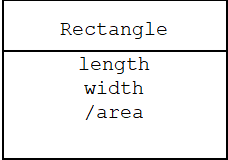
The slash in front of the area attribute indicates that it can be derived from the other attributes:
class Rectangle {
private double length;
private double width;
public double getLength() { return
length; }
public void setLength(double val) {
length = val; }
public double getWidth() { return
width; }
public void setWidth(double val) {
width = val; }
public double getArea() { return length
* width; }
}
1.6 Stereotypes
UML can be extended using stereotypes. A stereotype is an existing UML icon with a stereotype label of the form:
<<stereotype>>
A collaboration is a group of classes that work together to achieve a particular goal. Although a certain collaboration may have wide applicability, the actual classes that appear in this collaboration may have different names and meanings from one application to the next. In this case stereotypes can be used to indicate the role a class plays within the collaboration. For example, suppose Secretary class has a member function called type() that creates Report objects:
Report* Secretary::type(...) { return new Report(...); }
In Chapter 3 we will learn that this type of a member function is called a factory method. The class containing the factory method plays the role of a "factory", the return type of the factory method plays the role of a "product", and the association between the factory and product classes is that the factory class creates instances of the product class. We can suggest these associations by simply attaching stereotypes to the icons in our diagram:
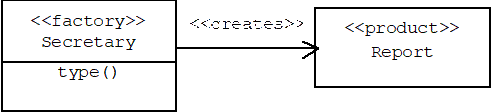
Commonly used UML class stereotypes include:
<<powertype>> = Instances represent subclasses of another class
<<metatype>> = Instances represent other classes
<<active>> = Instances own their own thread of control
<<persistent>> = Instances can be saved to secondary memory
<<control>> = Instance represent system control objects
<<boundary>> = Instance represent system interface objects
<<entity>> = Instances represent application domain entities
<<actor>> = Instances represent external systems or users
In some cases a stereotype is so common that it earns its own icon. For example, in UML actors are sometimes represented by stick figures:
1.6.1 Example: Coad's "Archetypes"
<<entity>>
<<role>>
<<event>>
<<place>>
1.6.2 Example: Jacobson's Stereotypes
<<control>> = Instance represent system control
objects
<<boundary>> = Instance represent system interface objects
<<entity>> = Instances represent application domain entities
1.6.3 Stereotypical Classes
In our discussion of reusability we introduced four reusability scopes:
Level 4: Foundation Scope
Level 3: Architectural Scope
Level 2: Domain Scope
Level 1: Application Scope
Recall that a module has application scope if its purpose is specific to a particular application. A module has domain scope if it can be reused in other applications that belong to the same application area or domain. A module has architectural scope if it can be reused in all applications that require a certain architectural feature. Finally, a module has foundational scope if it can be reused in any application.
If we take modules to be classes, then we can generate lots of examples of common or stereotypical classes.
1.6.3.1 Classes with Application Scope
Objects that handle application-specific events such as mouse button clicks, menu selections, and errors have application scope:
class MenuHandler { ... };
class MouseListener { ... };
class ErrorHandler { ... };
class Error { ... };
Classes that render views of domain objects have application scope:
class EmployeeView { ... };
class AccountView { ... };
class TransactionView { ... };
Classes that represent application specific commands and messages have application scope:
class Command { ... };
class Message { ... };
1.6.3.2 Classes with Domain Scope
Of course domain classes are categorized by their domains. For example:
health care
retail sales
science
government
military
manufacturing
academia
publishing
games
etc.
Domain scope classes usually fall into one of four categories: entity, event, role, and description.
Examples of entities include:
class Person { ... };
class Address { ... };
class Organization { ... };
class Report { ... };
class Inventory { ... };
class Account { ... };
class Invoice { ... };
class PurchaseOrder { ... };
class AccountManager { ... };
class Product { ... };
class LineItem { ... };
class Sprite { ... }; // for games
Examples of events include:
class Sale { ... };
class Transaction { ... };
class Observation { ... };
class ButtonClick { ... };
class Accident { ... };
Examples of roles include:
class Customer { ... };
class Student { ... };
class Employee { ... };
Examples of descriptions include:
class ProductDescription { ... };
class EmployeeType { ... };
class Phenomenon { ... }; // describes an observation
class Unit { ... }; // describes a quantity
1.6.3.3 Classes with Architectural Scope
Classes with architectural scope usually fall into one of two categories: control and interface.
Interface classes manage the interface between a program and users, remote systems, or devices. User interface classes include:
class Window { ... };
class Menu { ... };
class ControlPanel { ... };
class Button { ... };
class TextBox { ... };
class Console { ... }; // for an interpreter
Classes that interface with remote servers include:
class Socket { ... };
class ServerProxy { ... };
class DAO { ... }; // Database Access Object
class Query { ... };
class QueryResult { ... };
class URL { ... };
Classes that interface with devices include:
class File { ... };
class InputStream { ... };
class OutputStream { ... };
Architectural level controllers deal with forwarding messages and managing other objects:
class MessageDispatcher { ... };
class CommandProcessor { ... };
class MessageQueue { ... };
class WindowManager { ... };
class Thread { ... };
1.6.3.4 Classes with Foundation Scope
Almost any application uses these classes:
class String { ... };
class Number { ... };
class Quantity { ... }; // = number + unit
class Date { ... }; // =
month-day-year
class Time { ... }; // = hour:min:sec
class Duration { ... };
Data structures make good classes:
class Stack { ... };
class Queue { ... };
class Tree { ... };
class List { ... };
class Set { ... };
class Vector { ... };
class Graphe { ... };
class Table { ... };
Geometric and graphics classes can be viewed as foundational, architectural, or domain scope:
class Point { ... };
class Line { ... };
class Polygon { ... };
class Sphere { ... };
class Pen { ... };
class Canvas { ... };
1.7 Design Goals/Principals/Metrics
The goal of every program is to be useful (solve the right problems), usable (easy to use), and modifiable (easy to maintain). Two important design principles that help developers achieve the last goal are modularity and abstraction:
The Modularity
Principle
Systems should be decomposed into cohesive, loosely coupled modules.
The Abstraction
Principle
The interface of a module should be independent of its implementation.
Both of these principles are valid for several different definitions of module: function, object, class, ADT, or package.[1]
A cohesive module has a unified purpose, while loose coupling implies dependencies on other modules are minimized. Taken together, this makes a module easier to reuse, replace, and understand.
The abstraction principle implies that the external function or purpose of a module (the module's interface) should be separated from its internal structure (the module's implementation). A dependency on such a module is only a dependency on its public interface, not its private implementation. This frees clients[2] from the need to understand implementation details, while implementers are free to modify the implementation without the fear of breaking client code.
1.7.1 Cohesion
The methods of a cohesive class work together to achieve a common goal. Classes that try to do too many marginally related tasks are difficult to understand, reuse, and maintain.
Although there is no precise way to measure the cohesiveness of a class, we can identify several common "degrees" of cohesiveness. At the low end of our spectrum is coincidental cohesion. A class exhibits coincidental cohesion if the tasks its methods perform are totally unrelated:
class MyFuns {
void initPrinter() { ... }
double calcInterest() { ... }
Date getDate() { ... }
}
The next step up from coincidental cohesion is logical cohesion. A class exhibits logical cohesion if the tasks its methods perform are conceptually related. For example, the methods of the following class are related by the mathematical concept of area:
class AreaFuns {
double circleArea() { ... }
double rectangleArea() { ... }
double triangleArea() { ... }
}
A logically cohesive class also exhibits temporal cohesion if the tasks its methods perform are invoked at or near the same time. For example, the methods of the following class are related by the device initialization concept, and they are all invoked at system boot time:
class InitFuns {
void initDisk() { ... }
void initPrinter() { ... }
void initMonitor() { ... }
}
One reason why coincidental, logical, and temporal cohesion are at the low end of our cohesion scale is because instances of such classes are unrelated to objects in the application domain. For example, suppose x and y are instances of the InitFuns class:
InitFuns x = new InitFuns(), y = new InitFuns();
How can we interpret x, and y? What do they represent? How are they different?
A class exhibits procedural cohesion, the next step up in our cohesion scale, if the tasks its methods perform are steps in the same application domain process. For example, if the application domain is a kitchen, then cake making is an important application domain process. Each cake we bake is the product of an instance of a MakeCake class:
class MakeCake {
void addIngredients() { ... }
void mix() { ... }
void bake() { ... }
}
A class exhibits informational cohesion if the tasks its methods perform are services performed by application domain objects. Our Airplane class exhibits informational cohesion, because different instances represent different airplanes:
class Airplane {
void takeoff() { ... }
void fly() { ... }
void land() { ... }
}
Note that the informational cohesion of this class is ruined if we add a method for computing taxes or browsing web pages.
1.7.2 Dependency and Encumbrance
Assume A and B are classes, interfaces, or packages. A depends on B if changes to B could cause changes to A. UML represents dependency using dependency arrows:
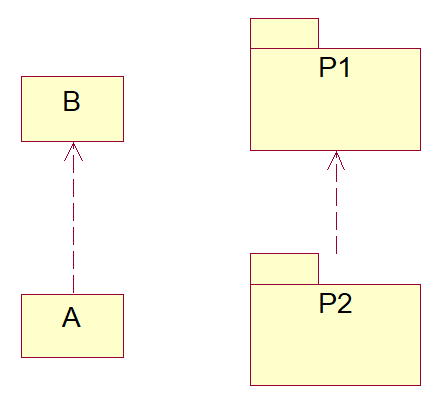
We symbolize this relationship as:
A << B
Dependency is a reflexive, transitive relationship:
A << A
A << B and B << C implies A << C
The dependency relationship extends the idea of one class referencing another:
A references B implies A << B
Where A references B if:
1. A extends or implements B
2. A has a field of type B
3. A has a method that references B
4. B appears as a template parameter in A (C++ only)
5. B is a friend of A (C++ only)
6. A references a B pointer, reference, or array
A method, A.m, references B if:
1. B appears in the signature of A.m
2. A.m has a local variable of type B
3. A.m uses a global variable of type B (C++ only)
One might wonder if there are other, sneaky ways for class A to depend on class B. Certainly any such "hidden" dependencies would make A harder to understand, modify, or reuse. The Transparency Principle[3] suggests that programmers avoid hidden dependencies. We can formalize the Transparency Principle by demanding that the dependency relationship is no more than the transitive closure of the references relationship:
A << B implies A references some C where C << B
The transitive closure of A:
TC(A) = { B | A << B }
gives us an idea of how much support A requires. For example, if A is a stand-alone class, then:
TC(A) = { A }
Clearly, the larger TC(A) is, the harder it is to reuse, understand, or replace A.
We can extend the concept of dependence and transitive closure to objects in the obvious way:
TC(obj) = { x | obj << x }
Saving an object to a file or database, or sending this object to a remote object over a network will require saving or sending the entire transitive closure of that object. The size of the transitive closure-- called the encumbrance of a class, package, or object-- is a crude measure of the required set of support:
encumbrance(A) = |TC(A)|
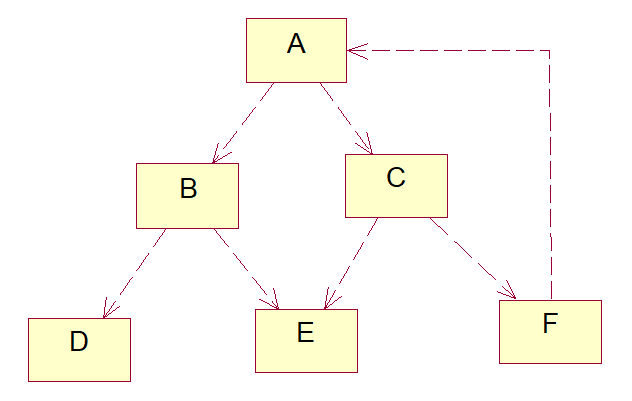
1.7.2.1 Structure of TC(A)
Bi-directional dependencies are possible
A << B AND B << A
In other words, TC(A) doesn't necessarily have a nice tree-like structure. Officially, TC(A) is a directed graph:
1.7.3 Coupling
The concept of coupling refines the notion of dependence by attempting to qualify and quantify the strength of the dependency of one class on another.
Assume A depends on B:
A << B
If A and B are loosely coupled, only major changes to certain methods of B should impact A. If A and B are tightly coupled, then small changes to B can have a dramatic impact on A.
Although there is no precise way to measure how tightly an association couples one class to another, we can identify several common coupling "degrees". For example, assume an E-commerce server keeps track of customers and the transactions they commit:
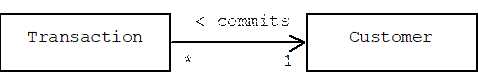
Normally, this would mean that the Transaction class has a member variable that points to a Customer:
class Transaction {
Customer customer;
// etc.
}
Some changes to the Customer class will impact the Transaction class, but some will not. For example, changing the private members of the Customer class should have no impact. This is the most common form of coupling. For lack of a better term, we will call this client coupling.
On the other hand, if a C++ Transaction class is a friend of the Customer class:
class Customer
{
friend class Transaction;
// etc.
};
Then Transaction is content coupled to Customer. Changes to the private members of Customer could impact Transaction. Declaring one class to be the friend of another tightens the coupling between the two classes.
If Customer is an interface for corporate and individual customers:

Then the Transaction class can't even be sure what type of object its customer pointer points at. There is no mention in the Transaction class of corporate or individual customers, only customers. Transactions can call public Corporate and Individual methods that are explicitly declared in the Customer interface. Other public methods such as Corporate::getCEO() or Individual::getSpouse() are not visible to transaction objects. Transaction exhibits interface coupling with the Corporate and Individual classes. Obviously interface coupling is looser than client coupling.
Message passing also helps to loosen the coupling between objects. For example, suppose an object representing an ATM machine mediates between transactions and customers:
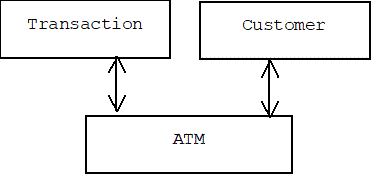
In this case transactions and customers communicate by passing messages through the ATM machine, which means that the transaction doesn't even need to know the location of the customer. We shall call this message coupling. Short of totally uncoupled, we can achieve the loosest form of coupling by combining interface and message coupling.
1.8 Design Patterns
A design pattern can be viewed as a recipe for solving a recurring design problem. In this analogy a pattern catalog can be viewed as a cookbook containing design patterns organized according to the types of problems they solve.
A design pattern describes a group of classes or packages that work together to solve the problem. We call such a grouping a collaboration. Thus, a design pattern describes a recurring collaboration used to solve a recurring problem.
A typical design pattern is organized into four sections:
NAME(S)
The various names given to this
collaboration
PROBLEM
Describes the recurring problem
SOLUTION
STRUCTURE
Describes the collaboration using a
class diagram
Behavior
Describes the interaction between
instances of the
collaboration using a sequence
diagram
Discussion
Describes alternate or related
collaborations, advantages and
disadvantages, where the pattern has
been used, implementation
tips, etc.
The design pattern concept was introduced by Christopher Alexander, a professor in the School of Architecture at UC Berkeley. His book, A Timeless Way of Building should be read by anyone who takes design seriously.
The idea of using pattern catalogs to describe best practices has mushroomed into the Pattern Movement. Many industries have developed pattern catalogs. There are pattern catalogs for each phase of software development.