Serialization
Serialization is the process of saving an object to a file.
Deserialization is the reverse process: creating an object from data in a file.
On first glance serialization sounds easy, the writer program simply writes each field to some file:
outfile.write(object.field1);
outfile.write(object.field2);
outfile.write(object.field3);
Deserialization is a bit more problematic because the reader program must first create the object that has fields of the appropriate type. For example, if the object is an instance of class CCC the process might look like this:
CCC newObject = new CCC();
infile.read(newObject.field1);
infile.read(newObject.field2);
infile.read(newObject.field3);
But what if the reader program doesn't know the type of the object to be read?
Prototyping
One solution is for the writer program to write the name of the class to the file before writing the fields:
outfile.write("CCC");
outfile.write(object.field1);
outfile.write(object.field2);
outfile.write(object.field3);
But in this case the reader program needs to be able to create the new instance of the object from the name of the class. This can be done using the Prototype Design Pattern. Recall that in this pattern a prototype table associates class names with prototypical instances of the class. The reader simply uses the class name to look up the prototype, then clones the prototype:
String className;
infile.read(className);
SerializableObject prototype = prototypeTable.get(className);
SerializableObject newObject = prototype.clone();
infile.read(newObject.field1);
infile.read(newObject.field2);
infile.read(newObject.field3);
The Transitive Closure of an Object
Object a depends upon object b if a has a field that contains a pointer or reference to b. The dependency relationship is transitive. In other words, if a depends upon b and b depends upon c, then a also depends upon c. The dependency relationship is also reflexive: every object depends upon iteself.
The transitive closure of a, TC(a), is the set of all objects that a depends upon.
We can represent TC(a) as a directed dependency graph in which nodes represent objects and arrows represent pointers.
Here's an example:
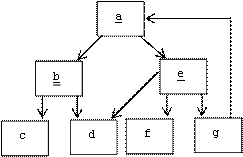
Clearly:
TC(a) = {a, b, c, d, e, f}
Our example shows that the dependency graph of TC(a) may contain cycles and may contain multiple references to the same object.
Obviously, if object a is to be serialized, then every object in TC(a) must also be serialized.
If object a is to be deserialized, then every object in TC(a) must also be deserialized. In particular, the reader program must recreate the dependency graph of TC(a).
OIDs and Pointer Swizzling
Serializing a pointer is problematic because a valid address for the writer program will not be valid for the reader program. To overcome this problem we use the trick of pointer swizzling.
In pointer swizzling both the reader and writer programs maintain translation tables. The writer program maintains a table that translates pointers to object identifiers (OIDs). An OID consists of the name of the class of the object together with a unique identification number:
OID = ("ClassName", IDNUM)
When the writer program serializes a pointer, it consults the translation table. If an OID already exists for that pointer, then the OID is written to the output file, not the pointer. Otherwise the writer program generates a new OID, places it in the table, then writes the OID, together with the referenced object, to the output file.
Assume p is a pointer of type CCC*:
oid = table.get(p);
if (oid == null) {
oid = new OID("CCC", NEXT_ID++);
table.put(p, oid);
outFile.write(oid);
// now serialize *p
} else {
outFile.write(oid);
}
When the reader program encounters an OID in the input file, it consults its translation table that translates OIDs into valid pointers. If the translation is found, then the corresponding pointer is assigned to the object's field, otherwise the type of the OID is used to generate a new object, the oid is associated with the address of this new object, and the new address is written to the field:
inFile.read(object.field);
if (object.field containd an oid) {
SerializableObject* p = table.get(oid);
if (p == null) {
SerializableObject prototype =
prototypeTable.get(oid.className);
SerializableObject
newObject = prototype.clone();
p = &newObject;
table.put(oid, p);
// now deserialize newObject
}
object.field = p;
}
Serialization in Java
In Java all of the above details are hidden. Programmers merely declare a class to implement the empty Serialzable interface:
class Customer implements java.io.Serializable { ... }
Of course all objects in the transitive closure of a serializable object must also be serializable.
Serializable objects are written to ObjectInputStreams and read from ObjectOutputStreams. These are binary files. The details can be found here.
Serialization in C++
Serialization in C++ follows the outline given above. A framework for serialization in C++ is given in here.