5. Reflection and Persistence
Reflection
Recall the abstraction principle from chapter one:
The implementation of a module should be independent of its interface.
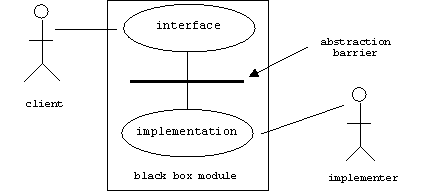
Next to modularity, abstraction is probably the most important principle in engineering for controlling the complexity of large systems. A module that hides its implementation from its clients is called a black box module, because it's like an impermeable black box with lights and buttons on the outside, but offering no clues about the wires and chips inside. Everyone knows that black box modules are easier to use and easier to replace.
But if this is true, then why is a group of heretics at Xerox PARC beginning to question abstraction? (See [WWW 2], [WWW 3], [WWW 4], and [WWW 11].)
The implementer of a module is usually faced with several possible implementations. He must choose which implementation to map the interface onto. This is called a mapping dilemma. For example, how will we implement a function that must sort text files:
void sort(string fileName) { ??? }
Heap sort? Quick Sort? Insertion Sort? The implementer will probably choose an implementation that will give his clients the best average performance. This is called a mapping decision. For example, we would probably choose quick sort because it has the best average behavior. However, the choice of implementation may impose performance penalties on the occasional application that isn't average. This is called a mapping conflict. For example, heap sort might be better suited for an application that must sort large files. Now the client must either introduce awkward workarounds into his code, or build his own supporting module.
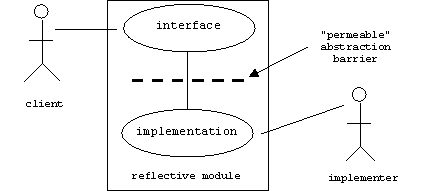
Unlike a black box module, a reflective module (sometimes called a glass box module) reduces mapping conflicts by allowing clients to inspect and alter some aspects of its implementation.
Reflective Systems
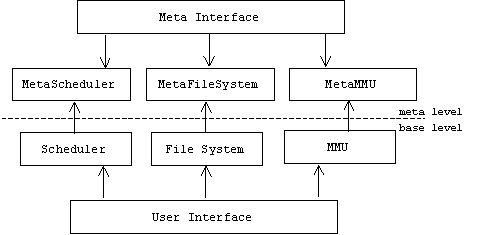
A reflective or open implementation (OI) system has two levels, a base level and a meta level. Base-level objects provide application services through the system's normal user interface. The policies, structures, and strategies used by a base-level object to implement these services (i.e., the mapping decisions) are encapsulated in an associated meta-level object, which the base-level object consults at runtime when its services are invoked.
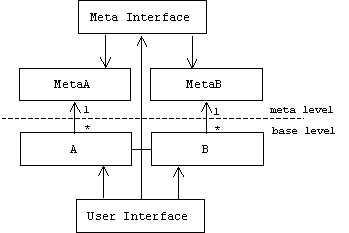
A meta interface or meta object protocol (MOP) allows clients- users and base-level objects -to access meta-level objects. Through the meta interface a client can inspect, modify, or replace a meta-level object, thus dynamically changing the behavior of the associated base-level objects.
Example: Reflective Interpreters and Compilers
Unlike C++ programs, which must be compiled into machine language programs that are subsequently executed by a CPU, LISP programs are executed directly by programs called interpreters. (Even Java programs are compiled into byte code programs that are executed by byte code interpreters called virtual machines.) Executing a program involves many policies that determine the semantics of the language. These policies determine things such as how parameters are passed (reference, value, name, etc.), how assignments are made (shallow or deep copy), how non-local variables are located (static or dynamic scoping), procedure call evaluation algorithms (lazy or eager), etc. Adding reflection (i.e., a meta level) to an interpreter allows programs and users to modify these policies to optimize performance:
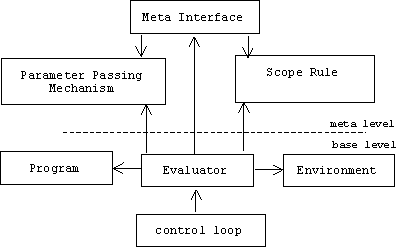
Reflection can be added to compilers, too. This allows programmers to optimize compiler policies such as how calls to overloaded functions are resolved (statically or dynamically), argument evaluation order, type checking, optimization, linking, etc. Many development environments already offer such controls. CLOS, Tiny CLOS, EuLISP, Java, STk, Dylan, Dynace, Smalltalk, and Open C++ are examples of reflective languages, while C++ keywords such as virtual, inline, and register can be seen as part of the C++ compiler's meta interface.
Example: Reflective Operating Systems
Reflective operating systems can provide process meta interfaces to expose scheduling and synchronization policies, memory management meta interfaces like Mach's External Memory-Management Interface (EMMI) to expose page fetch and replacement policies, and file system meta interfaces like AFS to expose buffer management and disk head scheduling policies.
Microkernel Architectures
Microkernel architectures, supposedly used by Windows NT, are related to reflective architectures. Memory and process management policies are encapsulated by components called external servers or personalities. The actual memory, communication, and process management mechanisms are encapsulated in a component called the microkernel. There's even a microkernel design pattern:
Microkernel
[POSA]Problem
Long-lived applications must be adaptable so they can support new policies, standards, and technologies. For example, a word processor may need to be localized for use in new foreign markets, or it may need to support multiple look-and-feel standards.
Solution
Decouple policies and mechanisms. Related policies are encapsulated in objects called external servers or personalities. Mechanisms, which presumably don't need to change that often, are encapsulated in a microkernel, which is used by the personalities to implement their policies. If necessary, adapters can transparently manage interactions between clients, personalities, and the microkernel. The functionality of the microkernel can be extended by internal servers.
Static Structure
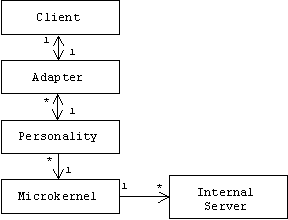
In theory, Windows NT can run applications (clients) designed for OS/2, POSIX, or Windows, because it supplies adapters and personalities for these operating systems. Drivers for monitors, keyboards, and disk drives would be regarded as internal servers.
Example: Database Systems
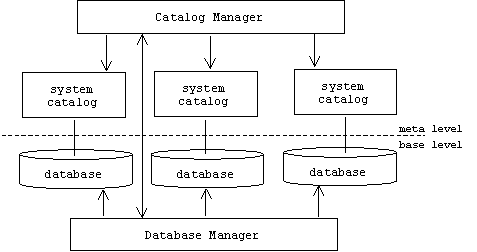
By definition, all database systems are reflective systems. While the data in an ordinary file can and must be interpreted by each program that reads it, possibly in different and inconsistent ways, a database includes a system catalog (also called a data dictionary or a data directory) that contains meta-data, or data about the data in the database. For example, the data in a relational database is organized into tables. The system catalog is a meta-level table that contains a row describing each base-level table. The information in this row might include:
1. Names, types, and sizes of each column of the base-level table.
2. Names of relationships to other base-level tables.
3. Names of users authorized to access the base-level table.
4. Constraints on the data in the base-level table.
5. Usage statistics.
For example, if a database contains a table of employee records, i.e., each row is a record that describes an employee, and if each employee record consists of five fields (i.e., columns): employee identification number, name, address, salary, and office, then the system catalog might include a table of the form:
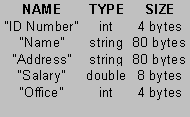
In addition, the system catalog might also tell us that salaries must be non-negative, every employee must have a unique identification number, the "Office" field is the identification number of a row in another table describing the company's branch offices, only certain managers may access the employee table, and the table was last modified on August 8, 1999.
Applications and users query a database through a database management system (DBMS). The DBMS uses a component called the catalog manager to consult the database's system catalog to determine how to answer the query. The catalog manager also provides a meta interface to the database administrator, who is responsible for creating and maintaining all databases.
Strategies
The simplest example of a meta-level object is a strategy. A strategy encapsulates some application-wide policy or algorithm. For example, a strategy object for a network might encapsulate a buffering policy, a routing algorithm, or a congestion control algorithm. A strategy object for a database management system might encapsulate a search strategy or an update policy. The external servers used by the microkernel architecture are strategy objects that determine process scheduling and page replacement policies. The ET++ application framework uses strategy objects to encapsulate text formatting policies such as line breaking algorithms. IBM's San Francisco framework uses strategy objects to encapsulate volatile business policies such as marketing strategies, investment strategies, or strategies for evaluating potential customers. Base-level objects maintain references to relevant strategy objects, which are called upon to make policy-level decisions. Therefore, changing a strategy object changes the behavior of all base-level objects that reference it. Strategy objects are formalized by the strategy design pattern:
Strategy [Go4], [WWW 5]
Other Names
Policy
Problem
An application domain policy may affect the behavior of application objects belonging to many different classes. For example, a government taxation policy affects the behavior of consumers, investors, and firms. The policy may change often, or the policy may be different for different instances of the same class.
Solution
Encapsulate the policy in a separate meta-level object. Each application (i.e., base-level) object maintains a reference to a policy object. Changing the policy object changes the behaviors of all associated application objects.
It's interesting to contrast the strategy pattern with the decorator pattern. In the decorator pattern the base-level object is a body, while decorators are handles that add some behavior, then delegate to their bodies, which may be the base-level object or still other decorators:
![]()
In the strategy pattern the base-level object is a handle that delegates to its body, a strategy that determines the base-level object's behavior:
![]()
Gamma, et. al. [Go4] express the comparison more colorfully:
"A decorator lets you change the skin of an object, a strategy lets you change the guts."
It's also interesting to compare the strategy pattern with the generic algorithm pattern. Recall that in the generic algorithm pattern the details of a class method were implemented in an extension class, while in the strategy pattern the details are determined by an associated strategy class.
Static Structure
The strategy pattern is structurally similar to the state pattern. A base-level object plays the role of the context, which delegates to a strategy object that plays the role of the state. All strategies are instances of classes derived from an abstract strategy base class, which specifies the meta interface. However, the strategy pattern is different from the state pattern, because many objects, possibly instantiating different classes, may share the same strategy object.
The strategy pattern is used in Java to layout containers. Recall that every container (in awt or in Swing) has an add method that allows programmers to add panels and controls to the container's content pane:
class GUI extends JFrame {
public GUI() {
Container contentPane = getContentPane();
contentPane.add(new Button("STOP")):
contentPane.add(new Button("GO"));
// etc.
}
}
How does the add() method know where to add the controls? Recall that this is determined by a layout manager associated with awt's Container class:
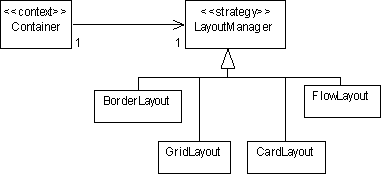
Programmers can set the layout manager using the setLayout method:
setLayout(new FlowLayout());
As another example, a financial application might represent investments as objects encapsulating the initial amount of the investment (i.e., the principle). A value() member function computes the future value of the investment after n months, but of course this function depends on the risk and yield of the selected investment strategy:
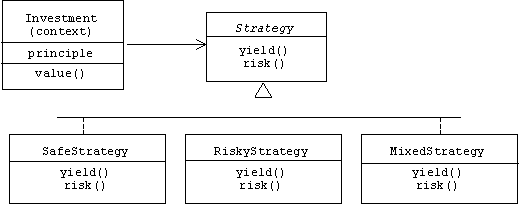
Runtime Classes
A more general example of a meta-level object is a runtime class. A runtime class is an object that represents a class. At first the idea seems strange, but we represent events, places, and items in the application domain as objects, why not represent classes as objects?
What class would a runtime class be an instance of? The class of all classes, of course:
class Class { ... }
Where would a runtime class come from? We could always explicitly construct a runtime class:
Class rtc = new Class(...);
or
Class rtc = Clas.forName(...);
But to be really useful, we want to be able to obtain a runtime class from a base-level application object. For example, assume Refrigerator is a concrete class derived from the abstract base class of all kitchen appliances, and assume app points to an instance of the Refrigerator class:
Appliance app = new Refrigerator(...)
Ideally, all objects would have a getClass() member function:
Class rtc = app.getClass();
At this point rtc points to an instance of Class that represents the Refrigerator class.
Of course this technique for obtaining runtime classes assumes an instance of the class already exists. We shall soon encounter situations where we need a runtime class in order to create instances, so it would be convenient to be able to create a runtime class by passing its name to a global or static function:
String name;
System.out.println("Enter a class name: ");
String name = System.in.readLine();
Class rtc = Class.forName(name);
What is the runtime class of a runtime class?
Class rtc2 = rtc.getClass(); // rtc2 = ???
This is a bit convoluted, but there is no paradox, yet; rtc2 simply points to a runtime class that represents the Class class, as does rtc2.getClass()!
What services would a runtime class provide? Minimally, a runtime class provides runtime type information. This information could be used to perform safe down casts, for example:
Class rtc = app.getClass();
if (rtc.getName() == "Refrigerator")
((Refrigerator)app).getTemperature();
We could also get information about the identity of base classes and meta classes:
Class rtc2 = rtc.getBaseClass();
System.out.println(rtc.getName()); // prints "Appliance"
rtc2 = rtc.getClass();
System.out.println(rtc2.getName()); // prints "Class"
This information could also be used to dynamically alter the behavior of a program in ways that couldn't be anticipated at the time the program was written and compiled. We can think of this as an extreme form of polymorphism that goes beyond virtual functions.
A runtime class might allow us to dynamically create new instances of the class it represents. This is called dynamic instantiation. For example:
Appliance app2 = rtc.newInstance();
returns a reference to a newly created Refrigerator object. We shall see that this is useful for framework factory methods that must construct objects without knowing their identity in advance.
If we add meta-level objects representing member variables and functions:
class Method { ... };
class Field { ... };
then a runtime class might be able to tell us about its members:
Method[] funs = rtc.getMethods();
Field[] vars = rtc.getFields();
This information, combined with dynamic creation, can be used to automate the process of reading and writing base-level objects to files and databases. This feature also raises the possibility of meta programs. A meta program is a program that analyzes, manipulates, or creates other programs. Debuggers, optimizers, and visual programming environments such as Visual Basic and Delphi are examples of meta programs. What services and attributes would you imagine MemberFunction and MemberVariable meta-level objects should provide?
Runtime Type Information in LISP
Unlike C++, LISP is a dynamically typed language. Type information is associated with values, not expressions, hence type information is available at runtime. If we want to know if x is a number, we simply ask:
(number? x)
Dynamic typing has advantages and disadvantages. The disadvantages are obvious. Type checking is normally done while the program is running. For example, the LISP interpreter happily accepts the erroneous definition:
// = x + 10?
(define (addTen x) (+ x "10")) // error: 10 not "10"
Even though the + operator expects both of its arguments to be numbers, not strings. We only find out about the error when the function is called:
-> (addTen 42)
Error, bad input to +: "10"
This is a disaster for mission-critical applications such as flight control programs. It also means that type checking is done each time the function is called instead of once, when the function is first defined.
On the bright side, no language is as polymorphic as LISP. The entire behavior of a LISP function can be determined at runtime, when the type of its input is known:
(define (inspect part)
(if (motor? part) (inspectMotor part)
(if (radio? part) (inspectRadio part)
(if (toaster? part) (inspectToaster part)
...))))
Runtime Type Information in Java
Java programmers get the best of both worlds, flexibility and efficiency. The Java byte code compiler uses type information provided by program declarations to check for type errors and select variants of overloaded functions, long before the program runs. But type information isn't discarded after compilation. Like LISP, type information is still available at runtime. (Of course this makes Java programs larger, but at least there is no runtime type checking.)
Recall that all Java classes-user or system defined -specialize the Object base class (see Programming Note A.9.1 in Appendix 1). In addition, Java provides Class, Method, and Field meta classes that correspond to our RuntimeClass, MemberFunction, and MemberVariable meta classes. Every Java object inherits from the Object base class a getClass() function that returns a reference to an appropriate Class meta-level object:
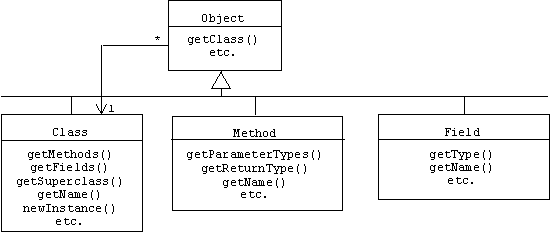
For example, assume the following Java class declarations are made:
class Document { ... }
class Memo extends Document { ... } // Memos are Documents
class Report extends Document { ... } // Reports are Documents
In other words, Memo and Report are specializations of Document:
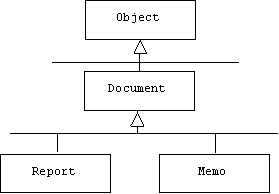
We can think of Document, Report, and Memo as base classes and Class, Method, and Field as meta classes.
Assume x is declared as a Document reference variable:
Document x; // x can hold a reference to a document
Then we can assign references to Memo or Report objects to x (see Programming Note A.9.4 in Appendix 1):
x = new Report(); // x holds a reference to a Report object
x = new Memo(); // now x holds a reference to a Memo object
At some point in time we may be unsure if x refers to a Memo object, a Report object, or perhaps some other special type of Document object (Letter? Contract? Declaration of Independence?) This isn't a problem. Programmers can fetch x's runtime class object by calling the inherited getClass() function:
Class c = x.getClass();
For example, executing the following Java statements:
Document x = new Report();
Class c = x.getClass();
System.out.println("class of x = " + c.getName());
c = c.getSuperclass();
System.out.println("base class of x = " + c.getName());
c = c.getSuperclass();
System.out.println("base of base class of x = " + c.getName());
x = new Memo();
c = x.getClass();
System.out.println("now class of x = " + c.getName());
produces the output:
class of x = Report
base class of x = Document
base of base class of x = java.lang.Object
now class of x = Memo
Notice that the name of the Object class is qualified by the name of the package (i.e., the namespace) that it belongs to, java.lang (see Programming Note A.1.2 in Appendix 1).
Java reflection goes further by introducing Method and Field meta classes. (In Java member functions are called methods and member variables are called fields.) Let's add some fields and methods to our Document class:
class Document
{
public int wordCount = 0;
public void addWord(String s) { wordCount++; }
public int getWordCount() { return wordCount; }
}
Next, we create a document and add some words to it:
Document x = new Document();
Class c = x.getClass();
x.addWord("The");
x.addWord("End");
Executing the following Java statements:
Method methods[] = c.getMethods();
for(int i = 0; i < methods.length; i++)
System.out.println(methods[i].getName() + "()");
Field fields[] = c.getFields();
try
{
System.out.print(fields[0].getName() + " = ");
System.out.println(fields[0].getInt(x));
}
catch(Exception e)
{
System.out.println("fields[0] not an int");
}
produces the output:
getClass
hashCode
equals
toString
notify
notifyAll
wait
wait
wait
addWord
getWordCount
wordCount = 2
Notice that the methods inherited from the Object base class were included in the array of Document methods. (There are three overloaded variants of the wait() function in the Object class.) If wordCount is declared private, as it normally would be, then its value doesn't appear in the last line:
wordCount =
Dynamic Instantiation
Dynamic instantiation means creating an instance of a class that isn't known until runtime. Thus, we can't simply write a declaration or call a constructor like we would if we knew the identity of the class at the time we were writing our program. This situation frequently occurs when we are developing frameworks that must create instances of classes that will be specified in customizations of the framework. We have already seen a solution to this problem. Recall the factory method pattern from Chapter 3:
Factory Method
[Go4]Other Names
Virtual constructor.
Problem
A "factory" class can't anticipate the class of "product" objects it must create.
Solution
Provide the factory class with an ordinary member function that creates product objects. This is called a factory method. The factory method can be a virtual function implemented in a derived class, or a template function parameterized by a product constructor.
Recall our framework for music applications- our example from Chapter 3 -where products were instruments and the factory was a framework class that couldn't anticipate what types of musical instruments would be introduced in its customizations. We outlined two solutions, virtual factory methods:
abstract class Factory {
abstract Instrument makeInstrument();
// etc.
}
where Instrument was the abstract base class of all instruments.
In situations where product types have unique, definable descriptions, there's another alternative, smart factory methods:
class Factory {
Instrument makeInstrument(Description d);
// etc.
};
where instances of the Description class describe different types of instruments, such as horn, drum, or harp.
For example, Description could simply be an integer code:
final int HORN = 0, HARP = 1, DRUM = 2;
In this case a smart factory method might simply use a multi way conditional to determine the type of instrument to build:
Instrument makeInstrument(int d) {
switch (d) {
case HORN: return new Horn();
case HARP: return new Harp();
case DRUM: return new Drum();
// etc.
}
}
This isn't very satisfactory because we must still place explicit calls to constructors in our framework code. Introducing a new type of instrument will require changes to the framework.
The algorithm of a smarter smart factory method might be guided by the structure of the description. For example, we can regard a parser as a smart factory method. In this context products are various types of parse trees (expressions, declarations, control structures, etc.) and descriptions are sequences of tokens:
ParseTree parser(List tokens) { ... }
Another possibility, which will be discussed below, are table-driven smart factory methods. In this case the factory method uses the description to search a table for a prototype product. The prototype is copied, the copy is customized, and is then returned to the caller. Although the empty table is provided by the framework, it is the job of the customization to create prototypes and place them in the table.
Dynamic Instantiation in Java
Java reflection allows objects to be created dynamically. Assume the following declarations have been made:
String cName; // holds a class name
Object x;
Class c;
Executing the Java statements:
try
{
cName= "Horn";
c = Class.forName(cName); // find & load a class
x = c.newInstance();
c = x.getClass();
System.out.println("class of x = " + c.getName());
cName= "Drum";
c = Class.forName(cName);
x = c.newInstance();
c = x.getClass();
System.out.println("now class of x = " + c.getName());
}
catch(Exception e)
{
System.out.println("Error: " + e);
}
produces the output:
class of x = Horn
now class of x = Drum
Calling Class.forName("Horn") locates the file containing the declaration of the Horn class, compiles it if necessary, then dynamically links it into the program.
Dynamic Instantiation in C++ (The Prototype Pattern)
Unfortunately, C++ doesn't have built-in support for dynamic instantiation, but the prototype pattern provides a standard way to add this feature to our C++ programs:
Prototype
[Go4]Problem
A "factory" class can't anticipate the class of "product" objects it must create.
Solution
Derive all product classes from an abstract product base class that provides a factory method that uses a type description parameter to determine the type of product to create. The type description parameter is used to locate a prototype, which is then copied, customized, and returned by the factory method.
The class diagram for the prototype pattern also includes objects, a device we employ to indicate that the associated object is a static variable defined in the class:
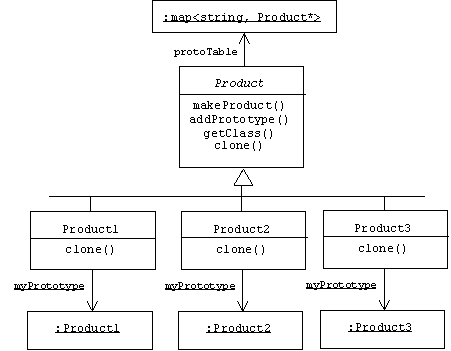
The abstract Product base class has a static variable of type map<string, Persistent> called protoTable (see Programming Note A.3.1.5 in Appendix 1 for a discussion of maps). This is the prototype table, which contains names of types (represented as C++ strings) associated with references to product prototypes. The static addPrototype() member function allows users to add entries to the prototype table. The prototypes themselves are static variables defined in the Product-derived classes. (That way they can all have the same name: myPrototype.) Here's what the prototype table looks like at the moment:
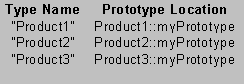
Prototype Table
Of course users are free to add more prototypes later.
In addition to addPrototype(), the Product base class also provides a static factory method, makeProduct(), and a getClass() function that uses RTTI to identify the type of a product:
class Product {
String getClass() const;
abstract Product clone();
static Product makeProduct(String type);
static Product addPrototype(Product p);
private static Table protoTable;
};
The factory method uses the type name to look up the associated prototype in the prototype table, then returns a clone of the prototype:
Product makeProduct(string type) {
Product proto;
if (find(type, proto, protoTable))
return proto->clone();
else
return null;
}
We know every product knows how to clone itself because clone() is an abstract factory method in the Product base class.
Persistence
Business applications create and manipulate objects representing accounts, invoices, and reports; engineering applications create and manipulate objects that model jumbo jets, vending machines, and robots. Often these objects must be shared by many applications (which may not all be C++ applications); when an application terminates (for example at the end of the day when the computers are turned off) these objects must be saved to a file or a database, and when an application restarts, these objects must be restored into the application's memory space. An object that can be saved to and restored from a file or database is called a persistent object. Objects that can't be saved and restored are called transient objects. Not all objects need to be persistent. For example, it's easier to recreate user interface objects such as windows and menus, so these tend to be transient, while semantic objects (i.e., objects that represent objects in the application domain) tend to be persistent.
Databases
A database is a repository of data that is shared by an organization. For example, a school might have a database containing data representing students, teachers, and courses. This database may be shared by administrators and faculty. A database is different from an ordinary file in several ways. First, a database also contains information about its own structure. This is called meta-data or the system catalog. It tells what information the database contains and how it is organized. In other words, a database is self-describing. (Examples of meta-data were discussed earlier in this chapter.) Second, applications and users don't access a database directly. Instead, they send queries and updates to a database management system (DBMS), which first determines if the user is authorized to access the database and if the request is consistent. If so, then the meta-data is used to devise a strategy for retrieving the required data, the data is retrieved and sent back to the user.
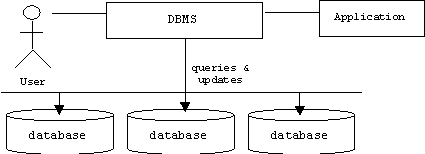
It is important to note that the retrieved data need not be explicitly represented in the database. For example, in response to the query:
"What are the names and grade point averages of all of Professor Smith's calculus students?"
the DBMS might need to perform multiple searches and cross referencing operations:
Find all calculus students.
Eliminate those who are not taking calculus from Professor Smith.
Eliminate all information about these students except name and GPA.
Databases must be carefully designed to maximize the number of types of queries that can be answered while minimizing data duplication and data retrieval time. The database design process is similar to the process for designing a program discussed in Chapter 1.
Relational Databases
The most common type of databases are relational databases. INGRES, ORACLE, Access, FoxPro, Informix, Sybase, and DB2 are examples of relational database management systems (RDBMS).
Conceptually, a relational database is organized into tables or relations. The rows of a table, also called records, represent objects in some application domain class, the columns of a table represent attributes. For example, our school database might consist of three tables representing the classes Student, Teacher, and Course. Assume each student takes exactly three courses per term, and each teacher teaches exactly three courses per term:

Rows in the student table represent students, columns represent student attributes such as identification number, last name, first name, grade point average, first period course, second period course, third period course, etc. An entry in a given row and column is called an attribute value:
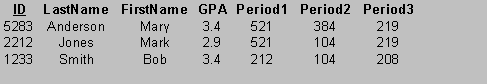
An attribute that is unique for each record is called a candidate key. For identification purposes there must be at least one candidate key for each table. In our example the ID attribute is a candidate key. One candidate key is selected as the primary key. The numbers in the "Period 1", "Period 2", and "Period 3" columns are foreign keys. A foreign key is a candidate key in another table. Foreign keys allow us to express links between records, hence associations between classes. In our example the foreign keys represent the ID numbers of courses in the Courses table:
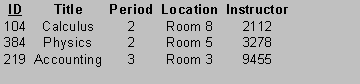
The entries in the Instructor column are foreign keys that represent the ID numbers of teachers in the Teacher table:

SQL
SQL (pronounced "see-quel", and standing for "Structured Query Language") is the ISO standard language for defining and manipulating relational databases. The basic data manipulation commands are:
SELECT ... To query data in a database
INSERT ... To insert rows into a table
UPDATE ... To update rows in a table
DELETE ... To delete rows from a table
Select is the most common command. Its basic format is:
SELECT column, column, ...
FROM table, table, ...
WHERE condition
For example, the query:
"What are the names of all students who have at least a 2.0 grade point averange and who take calculus during first period?"
can be expressed in SQL by:
SELECT LastName, FirstName
FROM Students
WHERE Period1.Title = "Calculus" AND 2.0 <= GPA
The result of executing a select command is a new table created from the tables listed in the FROM clause. The columns of the result table are those listed in the SELECT clause. The rows of the result table are those meeting the condition specified in the WHERE clause. If there is no WHERE clause, then no rows are filtered from the result table.
From the user's perspective, the result table appears to be one of the tables in the database, but in fact, the result table is often not explicitly stored in the database. Tables that are explicitly stored in the database are called base tables. Tables constructed from executing queries are called virtual tables or views. The tables listed in the FROM clause might be base tables or virtual tables.
Interfaces to Relational Databases
Humans normally use browsers with graphical user interfaces to interactively query and update databases. But how do applications query and update databases? For example, how do browsers query and update databases? Many database management systems include an API (Application Programmer Interface). This is a library of functions that perform the most common types of database operations and that can be called from an application. Unfortunately, there is no ISO standard governing these APIs, so a program might need to be altered if the DBMS is changed. Open Database Connectivity (ODBC) is a standard RDBMS API being proposed by Microsoft. To implement ODBC, RDBMS vendors provide a driver in the form of a DLL (Dynamic Link Library) that interfaces with the RDBMS API and interprets ODBC function calls.
Another way DBMS vendor-dependency can be eliminated is by using embedded SQL. Embedded SQL allows programmers to embed SQL statements directly into their source code. Subsequently, a preprocessor replaces them with calls to vendor-specific API functions that directly access the RDBMS. There are two styles of embedded SQL: static and dynamic. Static SQL is used if the query doesn't change. Dynamic SQL allows variables to be used in place of table or column names.
Object Oriented Databases and ODMG 2.0
The correspondence between records in a relational database and C++ objects is not as close as one would hope. (For example, C++ concepts like pointer, member function, and derived class don't have obvious RDBMS counterparts.) The rows of a table must still be converted into objects, and this can be a lot of work for the programmer and the CPU. In fact, it has been estimated that as much as 30% of programming effort and code space is devoted to converting data from database or file formats into and out of program-internal formats such as objects [ATK]. The gap between database formats and program-internal formats is called impedance mismatch.
In contrast to relational databases, object databases are collections of objects organized into classes that are related by association and specialization. But what type of objects? C++ objects? Java objects? Smalltalk objects? If an object database contains C++ objects, then impedance mismatch is eliminated between the database and C++ client programs, but not between the database and Java or Smalltalk programs. To resolve this problem a consortium of companies has formed the Object Database Management Group (ODMG) to define standards for object oriented database management systems (OODBMS). Version 2 of the standard (ODMG 2.0) appeared in 1997.
ODMG 2.0 includes specifications of an object model (i.e., language-independent definitions of object oriented concepts such as object, class, inheritance, attribute, method, etc.); OQL, the Object Query Language (a language with SQL-like syntax for searching object oriented databases); and language bindings for C++, Java, and Smalltalk. GemStone, Itasca, Objectivity/DB, Object Store, Ontos, O2, PoetT, and Versant are examples of ODMG 2.0-compliant OODBMSs.
Using an object database, a C++ (or Java or Smalltalk) program may refer to objects without worrying if they are in main memory or secondary memory. If the requested object is in secondary memory, an object fault occurs, and the OODBMS transparently locates the requested object using the object's unique object identifier number (OID), translates the object into a C++ (or Java or Smalltalk) object, then loads the object into main memory. If the program updates an object (and commits to the update), the procedure is reversed: the ODBMS translates the C++ (or Java or Smalltalk) object into an ODMG object, then writes the translated object back to the database.
Data Streams
Java's platform independence means that files created by non-Java programs can't be read by Java programs and vice-versa. Typically, a Java program writes Java primitive values (int, double, etc.) to a data output stream, which is nothing more than a filter that converts Java values into bytes. A Java program reads Java primitive values from a data input stream, which is nothing more than a filter that converts bytes into Java values:
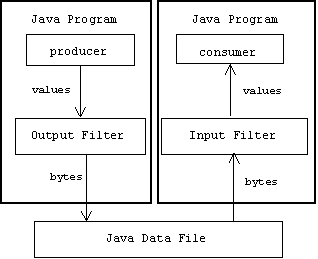
Output Streams
There are many classes of output streams derived from the abstract OutputStream base class. A file output stream is associated with an output file. A filter output stream is associated with the output stream that it filters:
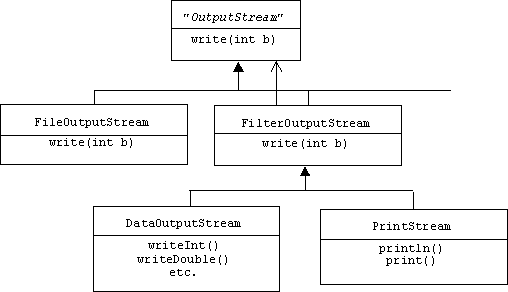
System.out and System.err are instances of the PrintStream class. They should only be used for debugging.
Input Streams
A file input stream is associated with an input file. A filter input stream is associated with the input stream it filters:
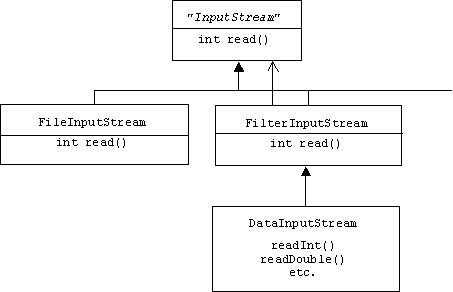
Example: Java File Producer
Let's begin by writing a reusable base class that produces Java data files. The constructor creates a file output stream from a file name; this is used to create a filter output stream, dout. The control loop iteratively calls a produce() function defined in the derived class. Presumably, this function writes Java values into dout. It indicates that it is finished by returning false:
import java.io.*;
import java.util.*;
import pearce.java.util.*;
public class JavaFileProducer
{
protected DataOutputStream dout;
private int count; // size of file produced
public int getCount() { return count; }
public JavaFileProducer(String fname)
{
count = 0;
try
{
FileOutputStream fout = new FileOutputStream(fname);
dout = new DataOutputStream(fout);
}
catch(IOException e)
{
Tools.error("File creation failed: " + e);
}
}
public void controlLoop()
{
boolean more = true;
while(more)
try
{
more = produce();
count++;
}
catch(IOException e)
{
Tools.error("Write failed: " + e);
}
try
{
dout.close();
}
catch(IOException e)
{
Tools.error("File close failed " + e);
}
}
// for testing purposes, redefine in an extension
protected boolean produce() throws IOException
{
if (count > 50)
return false;
else
{
dout.writeInt(2 * count + 1); // write consecutive odds
return true;
}
}
// test driver
public static void main(String[] args)
{
if (args.length != 1)
Tools.error("Usage: java JavaFileProducer OutFile");
JavaFileProducer jfp = new JavaFileProducer(args[0]);
jfp.controlLoop();
System.out.println("done");
}
} // JavaFileProducer
Running the Program
The program seems to run to completion:
C:\pearce\Java\Projects\streams2>javac JavaFileProducer.java
C:\pearce\Java\Projects\streams2>java JavaFileProducer
Usage: java JavaFileProducer OutFile
C:\pearce\Java\Projects\streams2>java JavaFileProducer aaa
done
But when I examine the file using type or cat, I only see gibberish:
C:\pearce\Java\Projects\streams2>type aaa
☼ ◄ ‼ § ↨ ↓ ← ↔ ▼ ! # % ' ) + - / 1 3 5
7 9 ; = ? A C E G I K M O Q S U W Y [ ]
_ a c e
C:\pearce\Java\Projects\streams2>
What happened? The file created, aaa, contains bytes representing Java integers, which can't be understood as ASCII codes by the DOS type command.
Example: Java File Consumer
Our next program is a reusable base class that consumes Java files. The constructor creates a data input stream, din, from a file input stream constructed from an input file name. The control loop iteratively calls a consume method defined in a derived class. The consume method throws an end-of-file exception, which is caught by the control loop and used to set the loop control variable to false:
import java.io.*;
import pearce.java.util.*;
public class JavaFileConsumer
{
protected DataInputStream din;
public JavaFileConsumer(String fname)
{
try
{
FileInputStream fin = new FileInputStream(fname);
din = new DataInputStream(fin);
}
catch(FileNotFoundException e)
{
Tools.error("File not found: " + e);
}
}
public void controlLoop()
{
boolean more = true;
while(more)
try
{
consume();
}
catch (EOFException e)
{
more = false;
}
catch (IOException e)
{
Tools.error("Read failed: " + e);
}
try
{
din.close();
}
catch(IOException e)
{
Tools.error("Can't close file: " + e);
}
}
// for testing purposes only, redefine in extension
protected void consume() throws IOException
{
int nextInt = din.readInt();
System.out.println(nextInt);
}
// test harness
public static void main(String[] args)
{
if (args.length != 1)
Tools.error("Usage: java JavaFileConsumer InFile");
JavaFileConsumer jfc = new JavaFileConsumer(args[0]);
jfc.controlLoop();
System.out.println("done");
}
}
Running the Program
We can use thc consumer to print the file created by the producer:
C:\pearce\Java\Projects\streams2>java JavaFileConsumer aaa
1
3
5
7
9
11
13
15
17
19
21
etc.
81
83
85
87
89
91
93
95
97
99
101
done
C:\pearce\Java\Projects\streams2>
Example: Java File Filter
To complete our suite of file processing tools, we need a reusable filter class that reads data from an input file, processes the data, then writes it to an output file:
import java.io.*;
import java.util.*;
import pearce.java.util.*;
class JavaFileFilter
{
protected DataOutputStream dout;
protected DataInputStream din;
public JavaFileFilter(String inFile, String outFile)
{
try
{
FileInputStream fin = new FileInputStream(inFile);
din = new DataInputStream(fin);
FileOutputStream fout = new FileOutputStream(outFile);
dout = new DataOutputStream(fout);
}
catch(IOException e)
{
Tools.error("Failed to open or create a file: " + e);
}
}
public void controlLoop()
{
boolean more = true;
while(more)
try
{
filter();
}
catch (EOFException e)
{
more = false;
}
catch (IOException e)
{
Tools.error("Read or write failed: " + e);
}
try
{
din.close();
}
catch(IOException e)
{
Tools.error("Can't close file: " + e);
}
}
// redefine in extension
protected void filter() throws IOException
{
int next = din.readInt();
if (next % 3 == 0)
dout.writeInt(next * next);
}
// test driver
public static void main(String[] args)
{
if (args.length != 2)
Tools.error("Usage: java JavaFileFilter InFile OutFile");
JavaFileFilter jff = new JavaFileFilter(args[0], args[1]);
jff.controlLoop();
System.out.println("done");
}
}
Running the Program
We can now set up pipelines of the form:
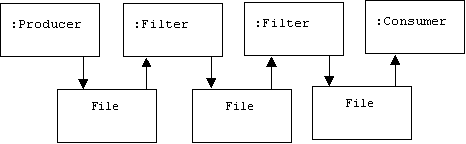
For example:
C:\pearce\Java\Projects\streams2>java JavaFileFilter aaa
Usage: java JavaFileFilter InFile OutFile
C:\pearce\Java\Projects\streams2>java JavaFileFilter aaa bbb
done
C:\pearce\Java\Projects\streams2>java JavaFileConsumer bbb
9
81
225
441
729
1089
1521
2025
2601
3249
3969
4761
5625
6561
7569
8649
9801
done
C:\pearce\Java\Projects\streams2>
Character Streams (Readers and Writers)
Java programs can read and write text files using the character encoding scheme of the local platform. This is done using readers and writers. Readers and writers form inheritance hierarchies parallel to the input and output stream hierarchies.
Example: Text File Producer
As an example of a writer, let's create a reusable text file producer class. The constructor first creates a file writer. It uses this to create a buffered writer (i.e., a writer that buffers its output for efficiency). Finally, a print writer is created from the buffered writer. Like a print stream, a print writer provides translators that translate Java values into strings using the local character encoding. Print writers don't throw exceptions, instead they set a flag that the control loop must check.
import java.io.*;
import java.util.*;
import pearce.java.util.*;
public class TextFileProducer
{
protected PrintWriter pout;
private int count; // size of file produced
public int getCount() { return count; }
public TextFileProducer(String fname)
{
count = 0;
try
{
FileWriter fw = new FileWriter(fname);
BufferedWriter bw = new BufferedWriter(fw);
pout = new PrintWriter(bw, true); // autoFlush = true
}
catch(IOException e)
{
Tools.error("File creation failed: " + e);
}
}
public void controlLoop()
{
boolean more = true;
while(more)
{
more = produce();
if (pout.checkError())
{
System.out.println("Write failed, count = " + count);
more = false;
}
else
count++;
}
pout.close();
// for testing purposes only, redefine in extension
protected boolean produce()
{
if (count > 50)
return false;
else
{
pout.println(2 * count); // write consecutive evens
return true;
}
}
// test driver
public static void main(String[] args)
{
if (args.length != 1)
Tools.error("Usage: java TextFileProducer FileName");
TextFileProducer tfp = new TextFileProducer(args[0]);
tfp.controlLoop();
System.out.println("done");
}
}
Running the Program
Note that the file created by the text file producer can be read using the DOS type program.
C:\pearce\Java\Projects\streams2>java TextFileProducer ccc
done
C:\pearce\Java\Projects\streams2>type ccc
0
2
4
6
8
10
12
14
16
18
20
22
24
26
28
etc.
80
82
84
86
88
90
92
94
96
98
100
C:\pearce\Java\Projects\streams2>
Example: Text File Filter
The text file filter constructor shows how a buffered reader is constructed from a file reader. Because we know that we are reading and writing strings, the control loop can do most of the work. It reads a line of input, turns it into a sequence of tokens, passes it to the filter program, which returns a string that is written to the out file. The control loop is terminated when null is returned by readLine().
import java.io.*;
import java.util.*;
import pearce.java.util.*;
class TextFileFilter
{
protected PrintWriter pout;
protected BufferedReader bin;
public TextFileFilter(String inFile, String outFile)
{
try
{
FileReader fr = new FileReader(inFile);
bin = new BufferedReader(fr);
FileWriter fw = new FileWriter(outFile);
BufferedWriter bw = new BufferedWriter(fw);
pout = new PrintWriter(bw, true); // autoFlush = true
}
catch(IOException e)
{
Tools.error("Failed to open or create a file: " + e);
}
}
public void controlLoop()
{
boolean more = true;
while(more)
try
{
String line = bin.readLine();
if (line != null)
{
StringTokenizer tokens = new StringTokenizer(line);
String result = filter(tokens);
if (!result.equals(""))
pout.println(result);
if (pout.checkError())
{
System.out.println("Write failed");
more = false;
}
}
else
more = false;
}
catch (IOException e)
{
Tools.error("Read failed: " + e);
}
try
{
bin.close();
pout.close();
}
catch(IOException e)
{
Tools.error("Can't close file: " + e);
}
}
// redefine in extension
protected String filter(StringTokenizer tokens)
{
String result = new String();
while(tokens.hasMoreElements())
{
String token = tokens.nextToken();
int next = 0;
try
{
next = Tools.toInt(token);
if (next % 3 == 0)
result = result + next * next + ' ';
}
catch(NumberFormatException e) {}
}
return result;
}
// test driver
public static void main(String[] args)
{
if (args.length != 2)
Tools.error("Usage: java TextFileFilter InFile OutFile");
TextFileFilter tff = new TextFileFilter(args[0], args[1]);
tff.controlLoop();
System.out.println("done");
}
}
Running the Program
nums.txt is an ordinary text file created using NotePad. It can be filtered by the filter program to produce another file that can be read by the DOS type program:
C:\pearce\Java\Projects\streams2>type nums.txt
100 35
42
16
37
99 1
2
5
C:\pearce\Java\Projects\streams2>java TextFileFilter nums.txt ddd
done
C:\pearce\Java\Projects\streams2>type ddd
1764
9801
C:\pearce\Java\Projects\streams2>
Tools.java
Recall the reusable interpreter class introduced earlier:
abstract public class Interpreter
{
public void controlLoop()
{
boolean more = true;
String cmmd = " ";
String result = " ";
while(more)
{
Tools.cout.print(prompt);
Tools.cout.flush(); // force the write
try
{
cmmd = Tools.cin.readLine();
}
catch(IOException ioe)
{
Tools.cerr.println("Error: " + ioe.toString());
}
if (cmmd.equals("quit"))
{
more = false;
Tools.cout.println("bye\n");
}
else if (cmmd.equals("help")) // undo, redo, etc.
{
Tools.cout.println("Sorry, no help available");
Tools.cout.println("type \"quit\" to quit");
}
else
{
StringTokenizer tokens = new StringTokenizer(cmmd);
result = execute(tokens);
Tools.cout.println(result);
}
} // while
} // controlLoop
// must redefine in the extension
abstract protected String execute(StringTokenizer tokens);
protected String prompt = "-> ";
} // Interpreter
Heavy use was made of Tools.cin, Tools.cout, and Tools.cerr. These are readers and writers constructed from the streams System.out, System.err, and System.in:
public class Tools
{
static public PrintWriter makeWriter(String path)
throws IOException
{
return new PrintWriter(
new BufferedWriter(
new FileWriter(path)), true);
}
static public PrintWriter makeWriter(OutputStream os)
{
return new PrintWriter(
new BufferedWriter(
new OutputStreamWriter(os)), true);
}
static public PrintWriter cout = makeWriter(System.out);
static public PrintWriter cerr = makeWriter(System.err);
static public void error(String gripe)
{
cerr.println(gripe);
System.exit(1);
}
static public BufferedReader makeReader(InputStream is)
{
return new BufferedReader(new InputStreamReader(is));
}
static public BufferedReader cin = makeReader(System.in);
static public BufferedReader makeReader(String path)
throws FileNotFoundException
{
return new BufferedReader(new FileReader(path));
}
// etc.
} // Tools
Object Streams
An object that can be written to and read from a file is called persistent or serializable. Otherwise we say the object is transient. Serializable objects are read from and saved to object streams.
Reading and writing objects presents three problems:
1. An object may contain references to other objects. When saving the object, these other objects must also be saved.
In fact, we can think of an object as the root of an object digraph, where nodes represent objects and arrows represent references:
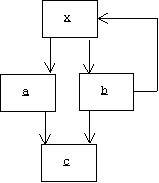
Saving x means recursively traversing the object digraph rooted by x in depth-first order, saving a, b, and c.
2. An object digraph may contain cycles or multiple paths to a single object. We want to avoid duplicating objects in the object stream and we want to avoid non terminating recursions.
In the example above, there are two ways to get to c, but we don't want to have two copies of c in the object stream. There is also a reference from b to x that could cause a non terminating recursion.
3. The reading program must know how much memory to allocate to hold the object digraph.
How will the reading program know how much memory to allocate for x? How will it know that memory should also be allocated for a, b, and c?
Using its run time type identification features, Java automatically solves all three problems.
For programmers, Java provides a filter-like object output stream class:
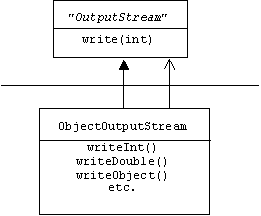
a filter-like object input stream class:
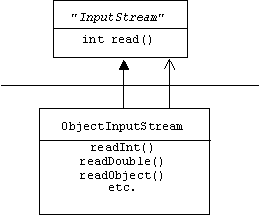
and an interface to flag serializable objects:
interface Serializable {}
Most pre-defined classes implement this interface.
Example
Address Book
An address book is a good example of an object that should be serializable. Our implementation simply maintains an array of person objects:
class AddressBook implements Serializable
{
private Person[] people;
private int size, maxSize;
AddressBook()
{
maxSize = 50;
size = 0;
people = new Person[maxSize];
}
public void addPerson(Person p)
{
if (size < maxSize)
people[size++] = p;
else
Tools.error("Address book is full");
}
public Person findPerson(String name)
{
boolean found = false;
Person result = null;
int i = 0;
while (!found && i < size)
found = name.equals(people[i++].getName());
if (found)
result = people[i - 1];
return result;
}
public void println()
{
for(int i = 0; i < size; i++)
{
people[i].println();
System.out.println("++++++++++++++++++");
}
}
} // AddressBook
Person
A person object must also be serializable:
class Person implements Serializable
{
private String name;
private Address address;
private String phone;
public Person(String nm, Address addr, String ph)
{
name = nm;
address = addr;
phone = ph;
}
public String getName() { return name; }
public Address getAddress() { return address; }
public String getPhone() { return phone; }
public void println()
{
System.out.println("Name = " + name);
address.println();
System.out.println(" " + phone);
}
} // Person
Address
Of course Java strings are serializable, but we must explicitly declare our Address class to be serializable:
class Address implements Serializable
{
private int number;
private String street;
private String city;
private String state;
public Address(int n, String st, String c, String s)
{
number = n;
street = st;
city = c;
state = s;
}
public void println()
{
System.out.println(" " + number + " " + street);
System.out.println(" " + city + ", " + state);
}
} // Address
An Object Writer
To test our address book we will need an object writer class and an object reader class. The object writer creates an address book, adds three people to the book, then saves it to an object output stream.
class ObjectWriter
{
public static void test(String outFile)
{
Address addr1 =
new Address(123, "Sesame St.", "New York", "N.Y.");
Address addr2 =
new Address(1600, "Pennsylvania Ave.",
"Washington", "D.C.");
String ph1 = "(212) 653-9875";
String ph2 = "(105) 953-5555";
Person george = new Person("George Jetson", addr1, ph1);
Person spock = new Person("Spock", addr2, ph2);
Person judy = new Person("Judy Jetson", addr1, ph1);
// make an address book
AddressBook book = new AddressBook();
book.addPerson(george);
book.addPerson(spock);
book.addPerson(judy);
book.println();
// do judy and george have the same address?
System.out.print("george.getAddress() == judy.getAddress() = ");
System.out.println(george.getAddress() == judy.getAddress());
try
{
ObjectOutputStream bookStream =
new ObjectOutputStream(
new FileOutputStream(outFile));
bookStream.writeObject(book);
}
catch(IOException e)
{
Tools.error("Error: " + e);
}
}
} // ObjectWriter
Here's the object digraph created. Note that Judy and George both contain references to the same address. This will be proved by comparing their addresses using ==.
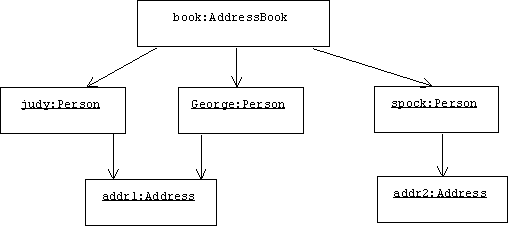
Object Reader
Our object reader simply declares a reference to an address book and an object input stream. The reader will also compare Judy and George's address to verify that their address wasn't duplicated:
class ObjectReader
{
public static void test(String inFile)
{
AddressBook book; // just a reference
try
{
ObjectInputStream bookStream =
new ObjectInputStream(
new FileInputStream(inFile));
book = (AddressBook) bookStream.readObject();
book.println();
Person x = book.findPerson("George Jetson");
Person y = book.findPerson("Judy Jetson");
if (x != null && y != null)
{
// do judy and george have the same address?
System.out.print("george.getAddress() == judy.getAddress() = ");
System.out.println(x.getAddress() == y.getAddress());
}
else
Tools.cout.println("Find failed!");
} // try
catch(IOException e)
{
Tools.error("Error: " + e);
}
catch(ClassNotFoundException e)
{
Tools.error("Error: " + e);
}
} // test
} // ObjectReader
Sample output
Demo is simply a test harness:
public class Demo
{
public static void main(String[] args)
{
if (args.length != 1)
Tools.error("usage: java Demo File");
System.out.println("calling ObjectWriter.test()");
ObjectWriter.test(args[0]);
System.out.println("\n\ncalling ObjectReader.test()");
ObjectReader.test(args[0]);
System.out.println("done");
}
}
Here's the output produced:
C:\Pearce\Java\Projects\streams>java Demo book1
calling ObjectWriter.test()
Name = George Jetson
123 Sesame St.
New York, N.Y.
(212) 653-9875
++++++++++++++++++
Name = Spock
1600 Pennsylvania Ave.
Washington, D.C.
(105) 953-5555
++++++++++++++++++
Name = Judy Jetson
123 Sesame St.
New York, N.Y.
(212) 653-9875
++++++++++++++++++
george.getAddress() == judy.getAddress() = true
calling ObjectReader.test()
Name = George Jetson
123 Sesame St.
New York, N.Y.
(212) 653-9875
++++++++++++++++++
Name = Spock
1600 Pennsylvania Ave.
Washington, D.C.
(105) 953-5555
++++++++++++++++++
Name = Judy Jetson
123 Sesame St.
New York, N.Y.
(212) 653-9875
++++++++++++++++++
george.getAddress() == judy.getAddress() = true
done
Are Java Programs Clairvoyant?
What would happen if the object reader ran in a separate program from the object writer? Everything would work as above provided the class loader could find AddressBook.class, Person.class and Address.class. This would happen if these files were in the current directory or in a directory listed in the CLASSPATH. Otherwise, a "class not found" exception would be thrown.
Java Database Connectivity (JDBC) is a package consisting of eight interfaces:
java.sql.Driver
java.sql.Connection
java.sql.Statement
java.sql.PreparedStatement
java.sql.CallableStatement
java.sql.ResultSet
java.sql.ResultSetMetaData
java.sql.DatabaseMetaData
The class diagram in Error! Reference source not found. shows the relationships between implementations of these interfaces:
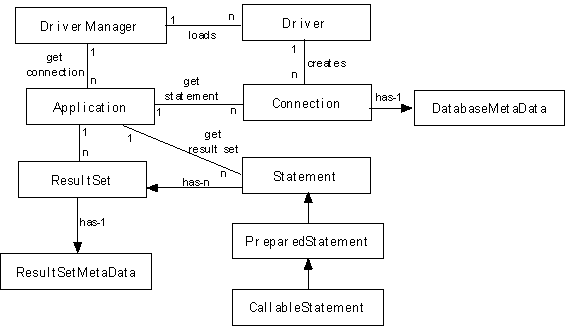
The central class in JDBC is java.sql.DriverManager. It maintains a list of all available drivers. A driver knows how to create a connection to a particular database. Drivers can be a little hard to find. JDBC drivers for most well known databases are available for a price. If a database has an ODBC driver, then one can use a JDBC-ODBC bridge, which is provided free on Windows NT, but must be purchased for Sun platforms. Consult the javasoft web site for a list of drivers and bridges.
An application loads the driver manager class, then asks it for a database connection using the URL of the database. The driver manager searchs its list of drivers, and, if it finds a matching driver, asks the driver to create the connection:
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
String url = "jdbc:odbc:ODBC_Addresses";
String user = "smith";
String pswd = "foobar";
Connection myConn = DriverManager.getConnection(url, user, pswd);
A connection represents a single database session. It stores information about the session and provides statement (or prepared or callable statement) object to the application:
Statement myStmt = myConn.createStatement();
A statement represents a template for an SQL statement (UPDATE, DELETE, INSERT, or SELECT). It provides executeQuery() and executeUpdate() methods. The executeQuery() method returns a result set representing a list of rows:
String sql = "SELECT columns FROM table WHERE column = xxx;
ResultSet rs = stmt.executeQuery(sql);
We can collect these objects in a Database class encapsulating a connection and a statement. The constructor loads a driver manager, uses the driver manager to find a driver, uses the driver to establish a connection, then uses the connection to create a statement:
import java.sql.*;
class Database {
private Connection myConn;
private Statement myStmt;
public Database(String dm, String url, String user, String pswd) {
try {
Class.forName(dm); // loads a DriverManager class
myConn = DriverManager.getConnection(url, user, pswd);
myStmt = myConn.getStatement();
} //try
catch(SQLException sqlexp) {
Tools.error("connection failed: " + sqlexp);
}
catch (ClassNotFoundException cnfe) {
Tools.error("Failed to load driver; " + cnfe);
}
}
// etc.
} // Database
The principle method provided by the Database class is execute(). Given a standard SQL statement, represented as a String, it returns a result represented as a formatted string. The execute method uses private predicates to determine if its input is a select, update, or insert statement. In case it is an update or insert method, the treatement is the same: myStmt.executeUpdate(sql) is called and the number of rows affected is returned. In case the statement is a select statement, myStmt.executeQuery(sql) is called. A result set is returned. This is converted into a formatted string and returned:
class Database {
private Connection myConn;
private Statement myStmt;
public Database(String dm, String url, String user, String pswd) {
...
}
public String execute(String sql) {
try {
if (isSelect(sql)) {
ResultSet rs = myStmt.executeQuery(sql);
return formatResultSet(rs);
}
else if (isUpdate(sql) || isInsert(sql)) {
int rs = myStmt.executeUpdate(sql);
return "# of rows affected = " + rs;
}
else
Tools.error("unrecognized SQL: " + sql);
} // try
catch (SQLException sqle) {
Tools.error("Dbase access failure; " + sqle);
} // catch
catch(IOException ioe) {
Tools.error("Request read failure; " + ioe);
} // catch
} // execute
// etc.
private boolean isSelect(String stmt) {
return (stmt.substring(0, 6).equalsIgnoreCase("SELECT"));
}
private boolean isUpdate(String stmt) {
return stmt.substring(0, 6).equalsIgnoreCase("UPDATE");
}
private boolean isInsert(String stmt) {
return stmt.substring(0, 6).equals("INSERT");
}
} // Database
A result set represents a list of rows extracted from a table. We can iterate through these rows using the result set's next() method. Each row is a list of columns. Each column is a String.
A result set has an associated metadata object that tells us the number of colums and the name and type of each column. The Database class supplies a formatResultSet() method can be used to convert the result set into a table string suitable for stream input or tokenizing. The format of a table string is given by the EBNF:
TABLE ::= table: ROW ...
ROW ::= row: COL ...
COL ::= name: NAME type: TYPE value: VALUE
where NAME, TYPE, and VALUE are Strings:
class Database {
private Connection myConn;
private Statement myStmt;
public Database(String dm, String url, String user, String pswd) {
...
}
public String execute(String sql) { ... }
private String formatResultSet(ResultSet rs)
throws SQLException
{
ResultSetMetaData rsmd = rs.getMetaData();
int cc = rsmd.getColumnCount(); // = # of columns
String result = " table: ";
// iterate through each row
while(rs.next()) {
result = result + " row: ";
// iterate through each column
for(int i = 1; i <= cc; i++) {
String colName = " name: " + rsmd.getColumnName(i);
String colType = " type: " + rsmd.getColumnType(i);
String colVal = " value: " + rs.getString(i);
result = result + colName + colType + colVal;
} // for
} // while
return result;
} // formatResultSet
// etc.
} // Database
Assume an address book is represented by a table called People, which is in a database with URL: jdbc:odbc:ODBC_Addresses. Assume the fully qualified name of the driver manager class provided by Java is sun.jdbc.odbc.JdbcOdbcDriver. (This class manages a single JDBC-ODBC bridge.) Each row in the table represents one address book entry and consists of seven columns named:
FNAME LNAME ADDRESS CITY STATE ZIP PHONE
The client program finds and displays all entries with a phone number specified by a command line argument:
class DbaseClient {
public static void main(String[] args) {
String sql =
"SELECT FNAME, LNAME, ADDRESS, CITY, STATE, ZIP, PHONE " +
"FROM People " +
"WHERE PHONE = " +
"'" + args[0] + "'\n";
Database db =
new Database("sun.jdbc.odbc.JdbcOdbcDriver",
"jdbc:odbc:ODBC_Addresses",
"smith", // owner
"foobar"); // password
Tools.cout.println(db.execute(sql));
}
JDBC can also be used to create databases.