Hints for Project 1
Document Management
In my mind the key features of a futuristic document management system (DMS) are:
1. The ability to support intelligent searches of a large repository of documents.
2. The ability to view a document in a variety of formats (PDF, HTML, etc.) and structures (tree, list, table, etc.)
Here's a fragment of a possible use-case diagram:
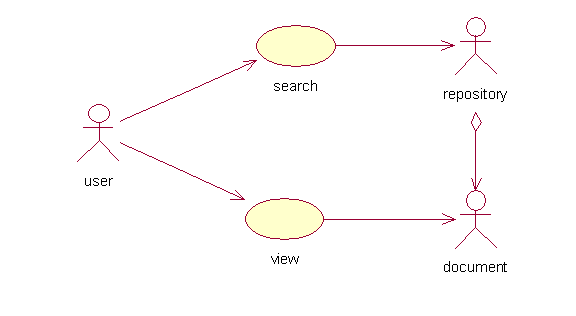
An example of this would be a repository of XML documents. Each document might be associated with a meta-document that specifies its syntax (such as a DTD or schema) as well as an ontology-- a meta-document that specifies its semantics. In addition, XSL style sheet meta-documents would describe how to transform XML documents into various types of HTML or PDF documents.
For example, an XML document describing the products of a winery might be associated with an ontology about wine, which extends a pre-defined food ontology and a pre-defined business ontology. There's also an ontology spectrum. At the "dumb" end of the spectrum are glossaries, taxonomies, and thesauri. At the "smart" end are detailed domain models expressed in languages like UML, OWL, or FOL (first-order logic).
Here's a fragment of a possible domain model:
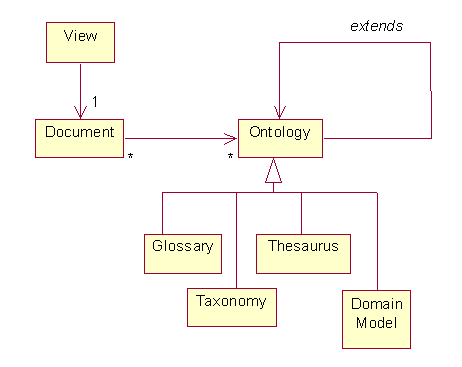
Content Management
The key feature of a Content Management System (CMS) is to view a document as a container of smaller units of information. IBM's Darwin Information Typing Architecture (http://www-106.ibm.com/developerworks/xml/library/x-dita1/) calls these smaller units "topics." A topic might be a description of a process (step 1, step 2, etc.), a description of a concept (The Modularity Principle, etc.), or a reference (a description of some API). Topics might be composed of smaller sections such as paragraphs, tables, or diagrams. A topic might be associated with a simple thesaurus that maps phrases used in the topic with equivalent phrases used in other topics.
Here's a fragment of the DITA domain model:
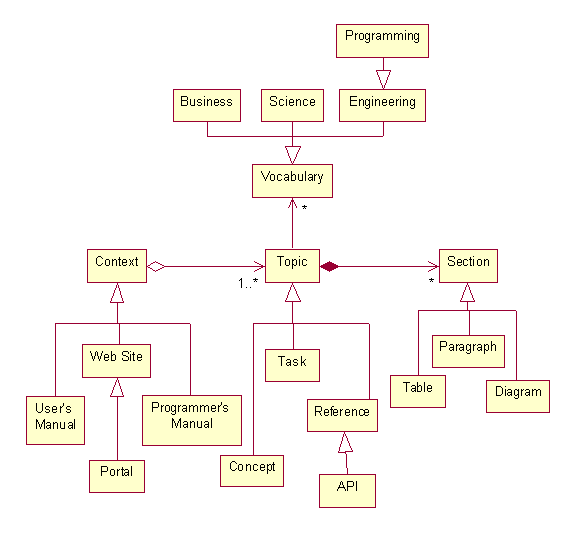
Returning to our earlier example, imagine the XML documents in our repository are much smaller, containing information about a single topic. The context or document might be an HTML document containing scripts (JSP scriptlettes or XSLT commands). Before the document is downloaded, the server executes the scripts. These scripts replace themselves with information extracted from the XML topic documents.