Language Processors
Assume L is a programming language. There are two broad categories of language processors for L: interpreters and translators.
Interpreters
Assume L is any programming language. Let
[L] = an L interpreter or virtual machine
[L] is a program, implemented in hardware or software, which can execute L programs. We write
[L](P) = the result produced by executing P
This result might have the form of a final answer or it might be a final state of [L].
A simple design for an interpreter might consist of four components:
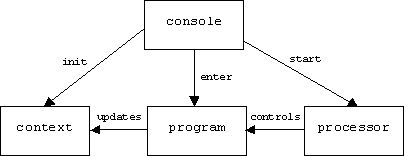
The console is a simple user interface that allows programmers to initialize and inspect the context, enter a program to be executed, and start the processor. The processor determines the next instruction in the program to be executed and executes it. Program instructions make reference to variables, names, remote servers, files, and primitive arithmetic and logic operations. All of these are defined in the context. We can think of the context as a state machine. The current state is the content is the current content of every variable, file, symbol table, etc.
For example, executing the assignment instruction:
x = x + 1;
Requires us to locate the variable names x, fetch its current content, add one to this value, and store the result back into the variable.
Translators
Assume S and T are programming languages, let
[S->T] = an S to T translator
[S->T] is a program which, given a program P written in language S as input, will translate it into a program P' written in language T such that P and P' do the same thing. We write this symbolically as:
[S->T](P) = P'
P and P' do the same thing means:
[S](P) = [T](P')
In other words:
[S](P) = [T]([S->T](P))
We refer to S as the source language and T as the target language.
Traditionally, translators favored a pipeline architecture:
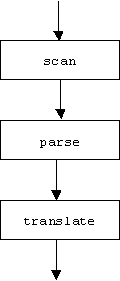
The input to the scan phase is a source program P. During this phase the characters of P are grouped into tokens (names, numbers, punctuation, reserved words, delimiters, operators, etc.). If any illegal tokens are detected, the translation process stops with an error. During the parse phase the tokens are organized into a tree-like structure that shows the syntactic relationships between the tokens. In the translate phase the tree is used to generate equivalent instructions in the target language. The output is P'.
Compilers and Assemblers
We can loosely define the level of a language, L, to be a measure of the semantic gap between L and the actual hardware of a computer. Traditionally, there are three levels. In descending order they are: high level languages (HLL), assembly level languages (ALL), and machine level languages (MLL).
Although it's possible to translate any source language into and (complete) target language, the most common scenario is when the level of the source language is greater than the level of the target language. Obviously, the greater the gap between levels, the more complex the translator.
A compiler translates a high level language into an assembly or a machine level language:
[HLL->ALL], [HLL->MLL]
An assembler translates an assembly level language into a machine level language.
[ALL->MLL]
Of course it's common practice to combine translators:
[HLL->MLL] = [HLL->ALL].[ALL->MLL]
Disassemblers and Decompilers
In certain situations we need to go the other direction: translating from a low level language to a high level language (for example, lost or "unavailable" source code). A disassembler translates from MLL to ALL:
[MLL->ALL]
A decompiler translates from ALL to HLL:
[ALL->HLL]
Tombstone Diagrams

http://www.dcs.gla.ac.uk/~simon/teaching/pldi3/lec2/sld036.htm
http://www.cs.auc.dk/~bt/SPOF03/SPOF03-2-1.ppt