Commands
A command (also called a statement) is a phrase that updates a variable when it is executed. Executing a command is called execution. The variables that are updated when a command is executed reside in the context. The value returned by executing a command is a simple token indicating that the operation was successful:
token = exec(command, context)
For example:
exec("x = x + 1", context)
assumes the context contains a variable named x. (If not, an error results.) This variable is incremented by one and the token "ok" is returned.
Data Control
Stores and Storables
Not all values can be stored in variables. Values that can be stored are called storables. For example, functions, types, and modules in C/C++/Java are not storable, while numbers, objects, and arrays are storable.
The variables of a context reside in a special data structure called a store. A store can be a stack, array, heap, file, or any combination of these.
In a simple array model the store is an array of cells. A cell is the simplest form of a variable, holding a single byte or integer
class Context {
static int CAPACITY = 1024;
int next = 0;
int[] store = new int[CAPACITY];
// etc.
}
We could think of an index for this array as the address or location of the corresponding cell, but in the interests of distinguishing between numbers and addresses, we will declare locations as objects:
class Location {
int index = -1;
// etc.
}
Declaring an integer variable:
int x = 10;
Causes the context to allocate the next available cell. The location of this cell will be bound to the name x in the environment, and the initial value, 10, will be stored in this cell:
Location allocate(int init) throws ContextError {
if (CAPACITY <= next) throw new
ContextError("memory full");
int location = next++;
store[location] = init;
return new Location(location);
}
If the allocated location is 100, then the binding created by our declaration is:
x = Location(100)
The assignment command:
x = x + 1;
simply updates the store:
store[100] = store[100] + 1;
Variables and References
A cell is an example of a simple variable, but programmers also need to allocate and update composite variables. The components of a composite variable may be simple variables or other composite variables. Arrays and objects are examples of composite variables. If simple variables (i.e., cells) only store single bytes, then variables that hold numbers are also composite variables.
We also need to extend the notion of location to composite variables. We call the address of a variable, composite or simple, a reference. Locations, as defined earlier, are simple references. A reference to a composite variable-- which may give information about the locations of the component variables-- is called a composite reference.
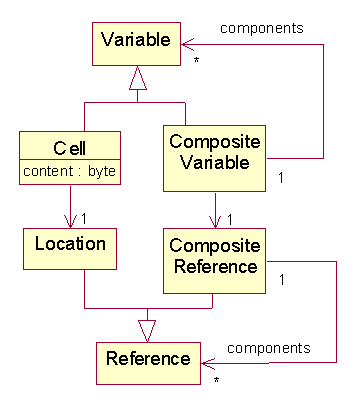
Let's redefine Location so that it extends an abstract Reference class:
abstract class Reference { }
class Location extends Reference {
int index = -1;
// etc.
}
We might have as many types of composite references as we do composite variables. For example, a reference to an array might be an array of references:
class ArrayRef extends Reference {
Reference[] components;
int size;
// etc.
}
The idea here is that if ref is a reference to an array, vals, then ref[i] is a reference to vals[i].
Assume Employee is a class:
class Employee {
String name;
int ssn;
float salary;
// etc.
}
An employee reference might be an instance of the class:
class EmployeeRef extends Reference {
Reference name;
Reference ssn;
Reference salary;
}
Thus, if ref is a reference to employee emp, then ref.age is a reference to emp.age, etc.
Assignment Operators
Executing an assignment command of the form:
x = x + 1;
updates the variable referenced by x, if one exists. Otherwise, an exception is thrown. (Do not attempt to allocate a variable to cover for the programmer's mistake. New variables can only come into existence through a proper declaration.)
Note the different interpretation of x depending on which side of the assignment operator it occurs on. If the current value contained in x is 10, then the x on the right hand side is interpreted as 10, and the entire right hand side is interpreted as the expression 10 + 1 or 11. On the other hand, the x on the left hand side definitely is not interpreted as 10, Otherwise this command would be equivalent to:
10 = 11;
If x is bound to the reference Location(100), then this is the interpretation of the left side, and the entire command is interpreted as:
store 11 into the cell at Location(100)
Copy versus Reference Semantics
C++ and Java disagree over the interpretation of assigning objects. Assume a Date class is declared in either language:
class Date {
int m, d, y;
}
In C++ the declaration:
Date today;
actually creates a Date object. The declaration:
Date tomorrow = today;
creates a copy of today and stores it in tomorrow. Changes to today won't affect tomorrow:
today.m = 7; // no change to tomorrow.m
By contrast, the declaration of today creates no object in Java. All Java objects are created by calling the new operator:
today = new Date();
This assignment creates a Date object in the heap, and places a reference to this object in today.
The declaration:
Date tomorrow = today;
copies the reference contained in today to tomorrow. In other words, today and tomorrow both refer to the same object. This means changes to today will be reflected in tomorrow:
today.m = 7; // tomorro.m = 7, too!
We distinguish Java and C++ by saying that Java uses reference semantics, while C++ uses copy semantics.
Although copy semantics is safer than reference semantics, it is less efficient and can lead to synchronization problems when multiple virtual objects represent a single real world object. For example, if an object-oriented database has multiple objects representing Joe Smith, then all of these objects must be updated when Joe moves. If one doesn't get updated, then the database will no longer be consistent.
As a final note, Java and C++ both employ copy semantics when primitive values are involved. For example, in both languages the declarations:
int x = 10, y = x;
create to integer variables each containing distinct copies of the number 10.
C/C++ Address and Dereferencing Operators
Some people view C as a high-level assembly language. As such, C programmers often need to manipulate addresses as well as data. Given a variable, x, we can access the address of x using the address-of operator: &x. Given an address, we can access the contents of that address using the dereferencing operator: *&x.
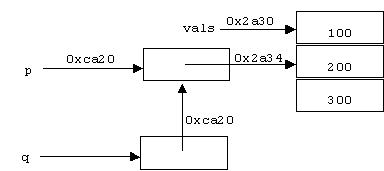
For example, assume the following declarations have been made:
int vals[] = {100, 200, 300};
int *p = &vals[1];
int **q = &p;
Let us further assume:
&p = 0x0000ca20
p = 0x00002a34
sizeof(int) = sizeof(int*) = sizeof(int**) = 4 bytes
What are the values of:
&vals[0]
&vals[2]
*p + 1
*(p + 1)
*q
**q
Box-and-Pointer Diagrams
To help with this problem, we can draw a Box-and-Pointer diagram. In such a diagram boxes represent variables and arrows represent addresses:
Streams and I/O Commands
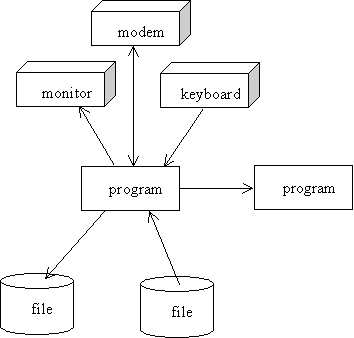
Streams
Programs access devices, files, and other programs by sending messages through streams. Thus, we can view the runtime environment of a program as a network in which nodes are devices, files, or programs, and links are one-way or two-way streams:
A stream can be thought of as a pipe or queue filled with messages. Messages are inserted into one end of a stream using the write command:
outStream.write(msgTo);
Messages are extracted from the other end using the read command:
msgFrom = inStream.read();
On the receiving end the stream is an input stream, while the sending end it is an output stream. To achieve two way communication, two streams are required (just like a telephone). (There are io streams which can be used for sending and receiving.)
Messages are character strings. The read and extraction operators automatically convert messages to and from binary data, as needed.
The standard input stream (stdin) is connected to the keyboard. The standard output stream (stdout) is connected to the monitor.
We can modify the source of stdin and the target of stdout using Unix/DOS pipes and redirection operators:
% program1 < file1 | program2 | program3 > file2
Sequence Control
The instruction pointer (IP) is a special variable used by the CPU to point to the next command to be executed. Here's a typical Fetch-Execute cycle performed by a typical CPU:
while(!terminate) {
command = store[IP++]; // fetch next
command
terminate = execute(command); // this
may modify IP!
}
Sequence control commands update the instruction pointer (IP) when executed. This allows for the possibility that the next command to be executed may not be the physically next command in memory. In other words, using sequence control commands, programs can alter their own flow of control. There are four types of control commands:
CONTROL ::= SELECTION | SEQUENCE | ITERATION | ESCAPE
Selections
Selections, also called conditionals, allow programmers to specify that a command should be executed only if a certain condition is true. Of course the truth of the condition generally won't be known until runtime. Selections are classified as one-way, two-way, and multi-way.
One-Way Selections
The form of a one-way selection is:
if (EXPRESSION) COMMAND;
Semantically, the expression, called the condition, is evaluated. If the value of this expression is different from 0 or false, then the command is executed, otherwise, control falls through to the next command. We often use fragments of flowcharts to describe the semantics of control commands:
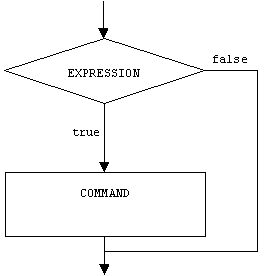
Note that in C/C++ the value of the condition does not have to be exactly true. Any non-zero value will be interpreted as truth.
One-way selections are typically used to terminate programs and functions when error conditions arise. For example, the following command might be used early in main to terminate the program if the value of x isn't positive:
if (x <= 0) return 1; // STOP, x must be positive!
// control only reaches this point if 0 < x
Two-Way Selections
The syntax of a two-way selection is
if (EXPRESSION) COMMAND; else COMMAND;
Once again, the expression is called the condition. The first command is called the consequence, and the second command is called the alternative:
if (CONDITION) CONSEQUENCE; else ALTERNATIVE;
Semantically, the condition is evaluated. If its value is not 0 or false, then the consequence is evaluated and the alternative is ignored. Otherwise, the alternative is evaluated and the consequence is ignored. Here's the flowchart representation:
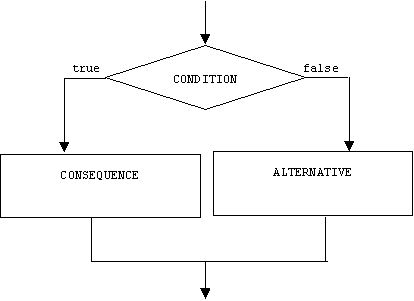
In the following example, a two-way selection prevents the user from dividing by zero:
if (den) result = 1/den; else cerr << "can't divide by 0";
Multi-Way Selections
Multi-way selections can be achieved by nesting two-way selections:
if (income < 0)
cerr << "income must be
non-negative\n";
else if (income < 10000)
tax = 0;
else if (income < 20000)
tax = .2 * income;
else if (income < 35000)
tax = .3 * income;
else if (income < 50000)
tax = .5 * income;
else
tax = .75 * income;
Question: What would a flow chart for this command look like?
Question: Why don't we need to check that income is also greater than or equal to the lower limit:
if (income < 0)
cerr << "income must be
non-negative\n";
else if (0 <= income && income < 10000)
tax = 0;
else if (10000 <= income && income < 20000)
tax = .2 * income;
// etc.
Beware of the dangling else.
Question: How much tax does a person making $15,000 pay? (Answer = unknown.) $8000? (Answer = $800.)
if (income < 10000)
if (5000 < income)
tax = .1 * income;
else tax = .2 * income;
Both Java and C++ inherit the bizarre switch command from C. The syntax and semantics of the switch command are so awkward that they almost render the command unusable. Here is the syntax:
switch(EXPRESSION)
{
case EXPRESSION: COMMANDS
case EXPRESSION: COMMANDS
case EXPRESSION: COMMANDS
// etc.
default: COMMANDS
}
The expression in parenthesis, called the key, must produce an integer or integer subtype value when executed. The switch command contains one or more case clauses. Each case clause begins with an expression called a guard, followed by zero or more commands, called consequences. The last case clause traditionally begins with the reserved word "default". The list of commands following it are called alternatives:
switch(KEY)
{
case GUARD: CONSEQUENCES
case GUARD: CONSEQUENCES
case GUARD: CONSEQUENCES
// etc.
default: ALTERNATIVES
}
Semantically, the key is evaluated. The value of the key is compared to the value of each guard, starting with the topmost guard. When a match is found, all commands following the guard, including commands that follow subsequent guards, are executed. The defaule guard matches all keys. For example, here is a flowchart describing the semantics of a switch command with three case clauses guarded by expressions called GUARD1, GUARD2, and GUARD3, respectively:
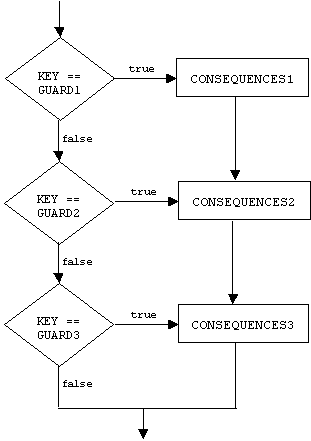
Notice that if KEY == GUARD1 is false, but KEY == GUARD2 is true (i.e., not 0 or false), then CONSEQUENCES1 will be ignored, but CONSEQUENCES2 and CONSEQUENCES3 will be executed. This happens even if KEY == GUARD3 is false!
To prevent the consequences of subsequent case clauses from being executed, programmers often end each sequence of consequences with a break command. Break commands will be discussed later. Essentially, a break command causes control to exit the current control command and pass to the next command.
Here's an example of a switch command:
switch(op)
{
case '+': result = arg1 + arg2; break;
case '*': result = arg1 * arg2; break;
case '-': result = arg1 - arg2; break;
case '%': result = arg1 % arg2; break;
case '/':
if (arg2) result = arg1 / arg2;
else cout << "can't
divide by 0\n";
break;
default: cout <<
"unrecognized operator: " << op << endl;
}
We can only use this switch command if op happens to be declared as a character, since char <: int:
double arg1, arg2, result;
char op; // = operator used to combine arg1 & arg2
If we declare op as a string:
string op;
then we must use nested if commands.
Sequence Commands
What happens if several commands must be executed when a condition is true:
if (CONDITION)
COMMAND1;
COMMAND2;
COMMAND3;
Unfortunately, the compiler ignores indentation. Commands 2 and 3 will be executed if CONDITION is true or false.
However, most languages allow programmers to group a sequence of commands into a single command called a sequence. Syntactically, a sequence is just a list of commands, each terminated by a semi-colon, delimited by curly braces:
{ COMMAND; COMMAND; COMMAND; etc. }
Semantically, each command in a sequence is executed in order of appearance:
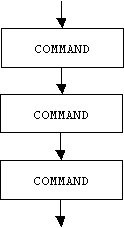
The following example shows how several commands can be grouped into a single command serving as the consequence of a conditional. Note that this example also shows that commands can be nested inside of commands. It also shows that sequences may contain declarations. A sequence that contains declarations is called a block. These will be discussed in the next chapter:
if (rad > 0)
{
int min = center + rad;
int max = center + rad;
if (min < result && result
< max)
{
double error = fabs(result -
center);
cout << "you only missed
by " << error << " inches\n";
}
}
Iterations
Iterations can be classified as indeterminate and determinant. Indeterminate iterations can be classified as test-at-top and test-at-bottom.
Indeterminate, Test-at-top Iterations
The indeterminate test-at-top iteration is called a while loop in C++. Here's its syntax:
while(EXPRESSION) COMMAND;
Semantically, the expression, called the condition, is evaluated. If its value is not 0 or false, then the command, called the body, is executed. This process repeats until the condition evaluates to 0 or false. Of course this may never happen, which is why this is called an indeterminate loop. In this case the condition and body are executed again and again and again. This is called a perpetual or infinite loop.
Here's the flowchart for a while command:
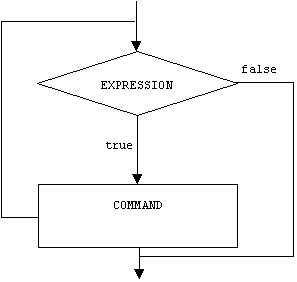
Indeterminate loops are often used as control loops. A control loop perpetually prompts the user for a command, executes the command, then repeats:
while(more == 'y')
{
cout << "enter a
non-negative number: ";
cin >> num;
if (num >= 0)
cout << "sqrt("
<< num << ") = " << sqrt(num) << endl;
cout << "more (y/n)?";
cin >> more;
}
Indeterminate, Test-at-bottom Iterations
Notice that if the condition of a while command is initially false, then the body is never executed. The indeterminate test-at-bottom iteration is called a do loop in C++. Here's its syntax:
do COMMAND; while (EXPRESSION);
Semantically, a do loop executes its body, then its condition. Thus, even if the condition is initially false, the body will be executed at least once.
We can formalize the semantics of the do loop by translating it into an equivalent while loop:
{ COMMAND; while(CONDITION) COMMAND; }
Here's our same control loop as a while command. The body will be executed at least once even if the initial value of more is not 'y':
do {
cout << "enter a
non-negative number: ";
cin >> num;
if (num >= 0)
cout << "sqrt("
<< num << ") = " << sqrt(num) << endl;
cout << "more (y/n)?";
cin >> more;
} while (more == 'y');
Determinate Iterations
Determinate iterations are called for commands in C++. Here's the syntax:
for(EXPRESSION; EXPRESSION; EXPRESSION) COMMAND;
The first expression is called the initialization; it may also be a sequence of local declarations. The second expression is called the condition; the last expression is called the update. The command is called the body. All are optional:
for(INITIALIZATION; CONDITION; UPDATE) BODY;
Semantically, the initialization is executed once. This usually declares and/or initializes loop control variables. Next, the condition is evaluated. If the value of the condition is not 0 or false, then the body is executed, then the update is executed. The update expression usually updates any loop control variables. The condition is re-executed and the process repeats, ending when and only when the condition becomes 0 or false. Of course this may never happen, which makes the designation "determinate loop" a bit of a misnomer.
Here's the equivalent while loop:
{
INITIALIZATION;
while (CONDITION)
{
BODY;
UPDATE;
}
}
The most common for loop uses a loop control variable to control the number of times the body will be executed. The following command
for(int lcv = 5; 0 <= lcv; lcv--)
cout << "count = "
<< lcv << endl;
produces the output:
5
4
3
2
1
0
Of course the body of a for loop may be another for loop. The following command:
for(int row = 0; row <= height; row++)
{
for(int col = 0; col <= width;
col++)
{
cout << '*';
}
cout << endl;
}
produces the output:
***********
***********
***********
***********
***********
***********
Notice that the body of the inner loop is a block command containing a single command. Technically, it's not necessary to make a single command into a block, but it is good programming practice as it makes the program more readable.
Escapes
Sometimes we find ourselves in a desperate situation: we can't continue the present task, perhaps because of bad input, and we would just like to escape to a happier place in our program. C++ provides several escape mechanisms:
goto LABEL;
break;
continue;
return value;
throw exception;
We have already met the break command. It causes control to exit the immediate control structure. The continue command is used inside of a loop. It causes control to branch back to the loop condition. For example, the following block:
{
int n = 0;
while (n++ < 10)
{
if (n == 5) continue;
cout << "n = "
<< n << endl;
if (n == 7) break;
}
cout << "while command
exited\n";
}
produces the output:
n = 1
n = 2
n = 3
n = 4
n = 6
n = 7
while command exited
In main the return command causes immediate termination of the program:
int main()
{
cout << "enter your income:
";
float income;
cin >> income;
if (income < 0) return 1; //
abnormal program termination
cout << "your tax = "
<< income * .25 << endl;
return 0; // normal program temination
cout << "bye\n"; //
never executed
}
We will discuss the throw command later.
Every command in a C++ program can be labeled. The goto command causes an unconditional transfer of control to the command with the indicated label. The following command:
{
int n = 0;
while (n++ < 10)
{
A: cout << "n = "
<< n << endl;
}
cout << "while command
exited\n";
goto A;
}
produces the output:
n = 1
n = 2
n = 3
n = 4
n = 5
n = 6
n = 7
n = 8
n = 9
n = 10
while command exited
n = 11
while command exited
n = 12
while command exited
n = 13
etc.
Structured Programming
The structured programming movement (Wirth, Dijkstra, Hoare, et. al.) aimed at making the correctness of programs mathematically provable. The idea was to bracket each command with an entry and exit condition:
assert(ENTRY CONDITION);
COMMAND;
assert(EXIT CONDITION);
Entry and exit conditions assert conditions on the state of the environment, while executing a command causes a change in the environment. We can turn a bracketed command into a mathematical proposition:
if the enviroment satisfies ENTRY CONDITION, then after we execute COMMAND, the environment will satisfy EXIT CONDITION.
Of course the exit condition of one command is the entry condition of the next command:
assert(C1);
{
assert(C1);
S1;
assert(C2);
S2;
assert(C3);
}
assert(C3);
Thus, we could hope to provide a mathematical proof of the correctness of an entire program.
The idea worked well except in situations where there was more than one way to enter a block command. (Multiple exit points were fine, though). This could only happen when goto commands were used unwisely. Our previous example demonstrated this point: there were two ways to enter the while block: from the top, or using the goto command.
To remedy this situation structured programming recommended limited use of the goto command. Structured languages, like C, Pascal, Algol, C++, Java, etc. provided the break and continue commands to wean programmers away from the few situations where a goto command might legitimately be used: to exit a block early. With the availability of such commands, structured programming could call for the abolishment of the goto command. (Something that only happened in Java.)
In general, you should avoid using the goto command.