Complexity
We often hear programmers and marketing executives brag that their program is superior to competing programs, even when the feature sets are virtually identical. Is there some mathematical basis for comparing the efficiencies of two programs?
Defining the complexity of algorithms, programs, and functions
Assume algorithm A implements function F. Assume we encode A as program P:
Implements(A, F) && Encodes(P, A)
There are four popular ways to measure the complexity of A:
TA(N) = Worst case runtime complexity = The maximum number of steps of P that will be executed given any input of size N, not including the time required to read the input.
tA(N) = Average case runtime complexity = The average number of steps of P that will be executed given any input of size N, not including the time required to read the input.
SA(N) = Worst case space complexity = The maximum number of words of memory used by P when executed given any input of size N, not including the space required to store the input.
sA(N) = Average case space complexity = The average number of words of memory used by P when executed given any input of size N, not including the space required to store the input.
Algorithm Analysis Rules
Here are a few rules for computing the complexity of an algorithm:
Expressions
STEPS(EXP1 OPERATION EXP2) = 1 + STEPS(EXP1) + STEPS(EXP2)
STEPS(f(EXP)) = STEPS(EXP) + TA(N)
STEPS(CONSTANT) = 0
STEPS(VARIABLE) = 0
Where N is the size of the value of EXP and A is the algorithms that implements f.
Simple Statements
STEPS(VAR = EXP) = 1 + STEPS(EXP)
STEPS(return EXP) = STEPS(EXP)
STEPS(goto LABEL) = STEPS(continue) = STEPS(break) = 1
Loops
STEPS[for(i = 0; i < n; i++) STMT] = n * STEPS[STMT]
Conditionals
STEPS[if(COND) STMT1; else STMT2] = STEPS[COND] + max(STEPS[STMT1], STEPS[STMT2])
Sequences
STEPS[{STMT1; STMT2;}] = STEPS[STMT1] + STEPS[STMT2]
Estimating complexity
Notice that we are really defining the complexity of P rather than A. It might make more sense to write:
TP(N), tP(N), SP(N), and sP(N)
Certainly algorithm A might be encoded by programs P1 and P2 that contain different numbers of steps. For example, P1 might be a very long assembly language program while P2 might be a very short program written in some high-level language. In this case we would expect TP1(N) to be different from TP2(N).
In the end, we will be estimating the complexity of an algorithm rather than computing its exact complexity. When N is large, the margin of error in our estimate will generally be greater than the differences between TP1(N) and TP2(N), even when P1 and P2 are from different languages. This margin of error will also overshadow the difference in time it takes to execute a primitive instruction on a computer equipped with a 200 GHz processor versus an antique computer equipped with an 8 MHz processor.
One might argue that such a large margin of error renders our complexity estimates useless. On the other hand, by marginalizing the importance of the choice of language or the speed of the underlying computer, we can feel confident that differences in efficiency between two algorithms that implement the same function are truly due to the choice of algorithm rather than the choice of language or computer.
Measuring the complexity of functions
We can extend our complexity measures for algorithms to complexity measures for functions. For example:
TF(N) = TA(N) where A is an optimal implementation of F
It is often quite difficult to compute TF(N) because this involves not only computing TA(N), but also proving that A is an optimal implementation of F.
Measuring the size of an input
For functions that operate on integers, the size of the input will be the input itself. For sequences and sets, we take the size of the input to be the length or cardinality of the input.
Example
Assume the function F is defined as the sum of all integers from 0 to N, where N is any non-negative integer:
F(N) = 0 + 1 + 2 + 3 + ... + N
Here are the encodings of three algorithms that implement F:
// recursive algorithm:
int P1(int N) {
if (N <= 0) return 0;
return N + P1(N – 1);
}
// iterative algorithm:
int P2(int N) {
int result = 0;
for(int i = 1; i <= N; i++) {
result = result + i;
}
return result;
}
// Gauss's algoruthm:
int P3(int N) {
return N * (N + 1) / 2;
}
Here are the respective complexity measures:
TP1(N) = 2 + TP1(N - 1) = 2 + 2 + TP1(N
- 2) = ... = 2N
tP1(N) = TP1(N) = 2N
SP1(N) = 1 + SP1(N - 1) = N
sP1(N) = SP1(N) = N
TP2(N) = 2 N
tP2(N) = TP2(N) = 2N
SP2(N) = 2 = # of variables used
sP2(N) = 2
TP3(N) = 3
tP3(N) = 3
SP3(N) = 0
sP3(N) = 0
Example
Comparing growth rates
Notice that the measure of complexity of a program, algorithm, or function turns out to be a function. Usually a measurement is something that can be compared to other measurements, like seconds, miles, dollars, or tons. How do we compare functions? For example, assume A and B are both algorithms that implement function F. To say that A is a more efficient algorithm than A, we need to be able to say that tA(N) is smaller than tB(N). But for some values of N tA(N) may be bigger than tB(N), while for other values the reverse will be true. Instead, what we try to claim is that tA is eventually smaller than tB. In other words, for some positive c and k:
tA(N) < c * tB(N) for all N > k
For example, assume:
tA(N) = 500N
tB(N) = N2
Then for k = 500
tA(N) < tB(N) for all N > k
Computer Scientists abbreviate the above assertion by writing:
tA = O(tB)
Or equivalently:
tB = Ω(tA)
We also say that tB majorizes tA.
If
tA = O(tB) && tB = O(tA)
we write:
tA = Θ(tB)
Of course this is a symmetric relationship:
tB = Θ(tA)
If
tA = O(tB) && tB ≠ O(tA)
we write:
tA = o(tB)
Of course we only use tA and tB as examples. We could have just as easily used TA and TB, SA and SB, sA and sB, or arbitrary functions F and G for that matter.
Facts about O
Notice that the relationship f = O(g) is not a total ordering. There are many examples of functions f and g such that neither f = O(g) nor g = O(f) are true.
Limit Formulations:
It's not difficult to prove:
f = o(g) iff limN->¥f(N)/g(N) = 0
f = o(g) iff limN->¥g(N)/f(N) = ¥
f = Θ(g) iff 0 < limN->¥f(N)/g(N)
< ¥
Using L'Hopital's Rule
Recall:
limN->¥f(N)/g(N) = limN->¥f'(N)/g'(N)
Fact: Assume f(N) is a degree n polynomial and g(N) is a degree m polynomial, then:
f = o(g) if n < m
g = o(f) if m < n
f = Θ(g) if m = n
Fact: Assume f(N) = logk(N) (= log base 2 of N raised to the kth power for k > 0), then
f = o(N)
Fact: Assume f(N) = cN for c any number > 1, assume g(N) is any polynomial, then:
g = o(f)
Fact: Assume f(N) = g(N) + h(N), and g = O(h), then f = O(h).
Fact: Assume f(N) = g(N) * h(N), then f = O(g * h).
Famous complexity classes
Instead of computing TA(N) exactly (or any of the other complexity measures), we will often show:
TA = O(F)
where F(N) is some well known function such as 1 (the constant function), log(N), N, N2, N3, or 2N.
It's worth mentioning a few famous complexity classes:
P = all algorithms A such that TA(N) = O(Nk)
for some k.
PSPACE = all algorithms A such that SA(N) = O(Nk) for
some k.
NP =
union of O(Nk) for all k
The Tyranny of growth rate
Assume function F can be implemented by four algorithms: A1, A2, A3, A4 where:
A1 = Θ(log
N)
A2 = Θ(N)
A3 = Θ(N2)
A4 = Θ(2N)
The following table shows worst case runtimes for these algorithms assuming one operation per millisecond (1 ms = 1/1000 seconds).
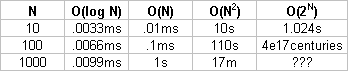
Key:
s = seconds
m = minutes
Notice the runtimes of all three algorithms are reasonable when N is small.