Concurrency
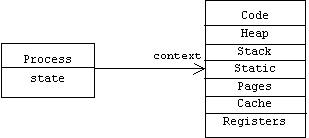
From a human perspective a process is a sequence of instruction executions— a running program —but from the operating system's point of view a process is an object— a record of a running program —consisting of a state and a memory context.
The memory context of a process consists of the memory segments that constitute its address space (code, heap, stack, static, etc.) as well as its caches, page table, and the contents of the CPU's registers:
A process is always in one of at least four states: Ready (waiting for the CPU), Running (using the CPU), Blocked (waiting for input), or Terminated:
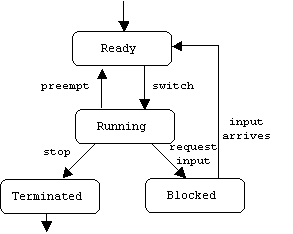
It is the job of an operating system component called a scheduler to allocate and de-allocate the CPU. Typically, all ready processes are stored in a ready queue. If process B is at the front of the ready queue when process A requests input, the scheduler performs a process switch:
1. Change A's state from Running to Blocked;
2. Save A's memory context;
3. Place A in a queue of blocked processes;
4. Restore B's memory context;
5. Change B's state from Ready to Running;
6. Remove B from the ready queue.
What happens if A never requests input? Some schedulers will let A use the CPU until it terminates, other schedulers are preemptive. This means they automatically take the CPU away from A after it has used the CPU for a fixed amount of time (called a time slice) without requesting input. A moves to the rear of the ready queue and the CPU is allocated to the process at the front of the ready queue.
A process switch is time consuming. Saving A's memory context and restoring B's memory context involves writing A's registers, caches, and page table to main memory, then reading B's registers, caches, and page table from main memory. If B hasn't run for a while, we can also expect a rash of page faults. The inefficiency of process switching has often discouraged programmers from using distributed architectures when the collaborating objects share the same CPU, because we must add process switching time to the time already consumed performing application-specific tasks.
To solve this problem, many operating systems allow programs to create threads. A thread is a lightweight process: it has a state and memory context, but the memory context is small, consisting only of registers and a stack. The other segments are shared with the process that created the thread.

The scheduler allocates the CPU to threads the same way it allocates the CPU to processes. (In fact, some schedulers simply consider processes to be special types of threads.) However, their smaller memory contexts make switching threads far more efficient than switching processes.
Threads
Unfortunately, threads are not part of the standard C++ library. Instead, we must rely on thread libraries provided by the underlying platform. Obviously this will make our programs platform-dependent. In Programming Note 7.1 we present implementation techniques that mitigate this problem. For now, assume the following thread class has been defined:
class Thread
{
public:
Thread(int d = 5) { state = READY;
delay = d; peer = 0; }
virtual ~Thread() { stop(); }
ThreadState getState() { return state;
}
void stop(); // RUNNING ->
TERMINATED
void start(); // READY -> RUNNING
void suspend(); // RUNNING ->
BLOCKED
void resume(); // BLOCKED -> RUNNING
void sleep(int ms); // BLOCKED for ms
miliseconds
void run(); // sleep-update loop
protected:
virtual bool update() { return false; }
// stop immediately
ThreadOID peer; // reference to a
system thread
int delay; // # msecs blocked between
calls to update()
ThreadState state;
};
A thread's state member variable indicates its current state. There are four possible values:
enum ThreadState { TERMINATED, READY, RUNNING, BLOCKED };
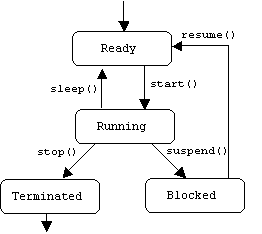
The run() function perpetually calls update() and sleep(delay) until either update() returns false, or until the thread state is set to TERMINATED:
void Thread::run()
{
while (state != TERMINATED && update())
sleep(delay); // be cooperative
state = TERMINATED;
}
The interleaved calls to sleep() will guarantee that CPU-bound threads won't dominate the CPU on non-preemptive operating systems.
Of course update() is a virtual function that immediately returns false. The idea is that programmers will create thread derived classes that will re-implement update() to do something more useful.
Active Objects
Most objects are passive. A passive object does nothing unless a client calls one of its member functions. When the member function terminates, the object goes back to doing nothing. The primary purpose of a passive object is to encapsulate a set of related variables. Thus, passive objects are simply high-level memory organization units.
Like a passive object, an active object[1] encapsulates a set of related variables, and like a passive object, an active object's member functions can be called by clients[2], but unlike a passive object, an active object is associated with its own thread of control. This thread of control gives an active object a temporal as well as a spatial dimension. Active objects not only passively provide services to clients, they can also be seen as tiny virtual machines that drive the application toward a goal using a perpetual control loop:
1. Inspect environment;
2. Compare environment state to goal state;
3. If same, quit;
4. Update environment;
5. Repeat.
Of course there may be many active objects, each with its own goal. In some cases these goals may even conflict with each other, but the overall effect is that the application is collectively driven toward some larger goal. In effect, active objects allow us to structure our programs as societies of virtual machines. Active objects are particularly useful in simulations of systems containing autonomous, active elements.
In this text active objects are simply instances of classes derived from the Thread class. In this case the perpetual control loop is Thread::run() and the environmental update procedure is Thread::update(), which returns false when the environment reaches the goal state.
The Master-Slave Design Pattern
Most multithreaded applications instantiate some variant of the Master-Slave design pattern:
Master-Slave [POSA]
Problem
An identical computation must be performed many times, but with different inputs and context. The results of these computations may need to be accumulated. If possible, we would like to take advantage of multiple processors.
Solution
A master thread creates multiple slave threads. Each slave performs a variation of the computation, reports the result to the master, then terminates. The master accumulates the results.
Static Structure
An active master object creates many active slave objects. Each slave object retains a pointer back to its master:
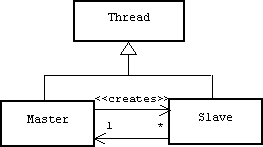
Implementation
The Slave::update() function performs a basic task, then returns true if it needs to be called again, otherwise false is returned and the slave terminates. Each slave is equipped with a pointer back to its master:
class Slave: public Thread
{
public:
Slave(Master* m = 0) { myMaster = m; }
protected:
bool update() { /* basic slave task
goes here */ }
Master* myMaster;
};
The master controls communication and coordination among its collection of slaves. The master's work is also accomplished by repeated calls to its update() function:
class Master: public Thread
{
protected:
bool update() { /* basic master task
goes here */ }
vector<Slave*> mySlaves(N);
};
The master's basic task typically includes creating and starting its slaves:
for(int i = 0; i < N; i++)
{
mySlaves[i] = new Slave(this);
mySlaves[i]->start();
}
Example: The Producer-Consumer Problem
In the traditional Producer-Consumer problem a producer thread produces imaginary objects called widgets and places them in a buffer. At the same time a consumer thread removes widgets from the buffer and consumes them.
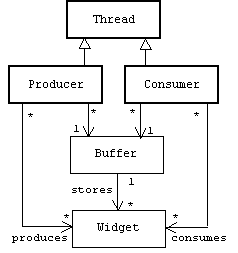
Despite its simplicity, this problem contains a number of synchronization problems. For example, assume the buffer is a length N array of widget pointers:
Widget* buffer[N];
Assume the producer always places new widget pointers at
buffer[k] and the consumer always consumes *buffer[k - 1], where k is the
current number of widgets in the buffer (0 £ k < N). Assume the
consumer consumes *buffer[k - 1] at the same moment the produce places a
pointer to a new widget at buffer[k]. Which widget will the consumer consume
next? Will it consume *buffer[k – 2], not realizing there is a pointer to a new
widget in buffer[k]? After the consumer consumes *buffer[0] it will enter a
blocked state waiting for the producer to produce more widgets. Meanwhile,
after the producer fills buffer[N – 1], it will enter a blocked state waiting
for the consumer to make some more room. This is called deadlock. Alternatively,
the consumer may notice the new widget pointer and consume *buffer[k] next.
Eventually, the consumer will attempt to re-consume *buffer[k – 1]. The invalid
pointer in
buffer[k – 1] will cause a program error or a crash.
Buffers
A joint bank account provides a simple example of the Producer-Consumer problem. In this context the buffer is a shared bank account, widgets are dollars, producers deposit dollars into the account, and consumers withdraw dollars from the account.
class Account
{
public:
Account(double bal = 0) { balance =
bal; }
void deposit(double amt);
void withdraw(double amt);
private:
double balance;
};
Our first implementation of the deposit() member function copies the balance member variable into a local variable, adds the deposited amount, goes to sleep for 500 milliseconds to simulate production time, then copies the local variable back into the deposit member variable. The output statements merely print diagnostic messages:
void Account::deposit(double amt)
{
cout << "depositing $"
<< amt << endl;
double temp = balance + amt;
System::impl->sleep(500); //
simulate production time
balance = temp;
cout << "exiting deposit(),
balance = $" << balance << endl;
}
Like the deposit() function, the withdraw() function also copies the balance member variable into a local variable, performs the deduction, sleeps for 350 milliseconds to simulate consumption time (spending it is always easier than making it), then copies the local variable back into the balance member variable:
void Account::withdraw(double amt)
{
cout << "... withdrawing
$" << amt << endl;
double temp = balance – amt;
System::impl->sleep(350); //
simulate consumption time
if (amt <= balance)
balance = temp;
else
cout << "... sorry,
insufficient funds\n";
cout << "... exiting
withdraw(), balance = $";
cout << balance << endl;
}
(See Programming Note 7.1 for a discussion of System::impl and System::sleep().)
Producer Slaves
Each producer encapsulates a pointer to the joint account and a counter that determines how many times its update() function will be called by the inherited Thread::run() function. (Recall that Thread::run() terminates when update() returns false.) If the counter is non-negative, then the update() function decrements the counter and deposits $10 in the joint account. If the initial value of the counter is 5, the default, then the total amount deposited will be 6 * $10 = $60.
class Depositor: public Thread
{
public:
Depositor(Account* acct = 0, int cycles
= 5)
{
account = acct;
counter = cycles;
}
bool update()
{
if (counter-- < 0) return false;
account->deposit(10);
return true;
}
private:
int counter;
Account* account;
};
Consumer Slaves
Each consumer thread also encapsulates a pointer to the shared account and a counter that determines how many times its update() function will be called. If the counter is non-negative, then the update() function decrements the counter and withdraws $8 from the joint account. If the initial value of the counter is 5, the default, and if the "insufficient funds" message never appears, then the total amount withdrawn will be 6 * $8 = $48.
class Withdrawer: public Thread
{
public:
Withdrawer(Account* acct = 0, int
cycles = 5)
{
account = acct;
counter = cycles;
}
bool update()
{
if (counter-- < 0) return false;
account->withdraw(8);
return true;
}
private:
int counter;
Account* account;
};
The Master
The master thread creates an account with an initial balance of $100, a producer slave and a consumer slave are created and started, then the master enters a blocked state waiting for keyboard input from the user. This prevents the master from terminating while its slaves are still at work.
int main()
{ // the master thread
Account* acct = new Account(100);
Depositor* depositor = new
Depositor(acct);
Withdrawer* withdrawer = new
Withdrawer(acct);
depositor->start();
withdrawer->start();
cout << "press any key to
quit\n";
cin.sync();
cin.get(); // block until slaves are
done
return 0;
}
A Sample Run
Here's the output produced by the first test run of the program. For readability, the diagnostic messages from Account::withdraw() are indented, while the Account::deposit() messages are left justified:
depositing $10
... withdrawing $8
... exiting withdraw(), balance = $92
... withdrawing $8
exiting deposit(), balance = $110
depositing $10
... exiting withdraw(), balance = $84
... withdrawing $8
exiting deposit(), balance = $120
depositing $10
... exiting withdraw(), balance = $76
... withdrawing $8
... exiting withdraw(), balance = $68
... withdrawing $8
exiting deposit(), balance = $130
depositing $10
... exiting withdraw(), balance = $60
... withdrawing $8
exiting deposit(), balance = $140
depositing $10
... exiting withdraw(), balance = $52
exiting deposit(), balance = $150
depositing $10
exiting deposit(), balance = $160
Synchronization
Notice that the producer
deposited $10 six times for a total of $60. The consumer withdrew $8 six times—
the "insufficient funds" message never appeared — for a total of $48.
Since the account initially contained $100, the final balance should have been
$100 + $60 - $48 = $112, not $160. We got into trouble right away when the
consumer interrupted the producer before the balance was updated to $110:
depositing $10
... withdrawing $8
... exiting withdraw(), balance = $92
... withdrawing $8
exiting deposit(), balance = $110
Readers might think that the
root of the problem is the leisurely pace of the Account's deposit() and
withdraw() member functions. Perhaps if we reduced these functions to single
lines we could have avoided the interruption problem:
void Account::deposit(double amt) { balance += amt; }
void Account::withdraw(double amt) { balance -= amt; }
This idea appears to work
until we set the withdrawer and depositor counters to a large value, say
30,000, then, eventually, the problem reappears. The real problem is that while
a typical CPU will complete the execution of an assembly language instruction
without interruption, the same is not true for a C++ instruction. Even the
simple C++ instruction:
balance += amt;
may translate into several
assembly language instructions:
mov reg1, balance //
register1 = balance
mov reg2, amt // register2 = amt
add reg1, reg2 // register1 +=
register2
mov balance, reg1 // balance =
register1
Eventually this sequence will
be interrupted by the withdrawer thread sometime after the first instruction
but before the last. When that happens, the amount withdrawn will be lost.
Locks
One way to coordinate access
to a shared resource like a joint bank account is to associate a lock with the
resource. A lock is an object that is always in either a locked or an unlocked
state, and it provides indivisible lock() and unlock() operations for changing
this state. (An operation is indivisible
if it can't be interrupted by another thread.)
If a lock is unlocked, the
lock() operation simply changes the state to locked. If the lock is locked,
then the thread calling the lock() function enters a blocked state and is
placed on a queue of blocked threads waiting to access the associated resource.
If a lock is unlocked, the
unlock() operation does nothing. If it is locked and there are no blocked
threads waiting to access the associated resource, then the unlock() operation
simply changes the state back to unlocked. If there are blocked threads waiting
to access the resource, the first thread on the queue is unblocked. From the
perspective of this unblocked thread, the lock() operation it called has just
been succesfully completed: the lock is locked and the thread has gained access
to the associated resource. Unless the thread checks the system clock, it is
unaware that it has been languishing on a queue of blocked threads since it
called lock().
Assume the following Lock
class has been implemented:
class Lock
{
public:
Lock();
void lock(); // state = locked
void unlock(); // state = unlocked
private:
LockOID peer; // reference to a system lock
};
Implementing Lock::lock() and Lock::unlock() requires the ability to disable interrupts and the ability to block, queue, and unblock system threads. For this reason locks are usually created, managed, and destroyed by the operating system. Semaphores and mutexes are examples of system level locks. In our implementation the peer member variable identifies the corresponding system lock. The Lock::lock() and Lock::unlock() functions simply delegate to corresponding system lock member functions. See Programming Note 7.2 for details.
A Thread-Safe Buffer
We can make shared resources such as joint bank accounts safe for access by multiple threads by equipping them with locks.
class Account
{
public:
Account(double bal = 0) { balance =
bal; }
void deposit(double amt);
void withdraw(double amt);
private:
double balance;
Lock
myLock;
};
Account::deposit() and Account::withdraw() call the associated lock's lock() function upon entry and call the unlock() function upon exit:
void Account::deposit(double amt)
{
myLock.lock();
// as before
myLock.unlock();
}
void Account::withdraw(double amt)
{
myLock.lock();
// as before
myLock.unlock();
}
It's important to realize that there is only one lock per bank account. When it's locked, either by the call to lock() at the top of Account::withdraw() or the call at the top of Account::deposit(), all other threads must wait for unlock() to be called before they can call either of these functions. If we could peer into the computer's memory, we might see a locked account with an associated queue of depositors and withdrawers waiting to gain access:
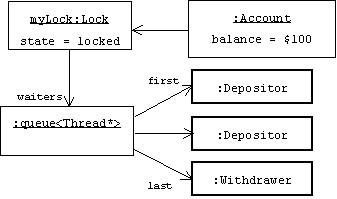
Another Sample Run
Running the simulation a second time using a lockable account produces the desired synchronization between the depositor and withdrawer threads:
depositing $10
exiting deposit(), balance = $110
... withdrawing $8
... exiting withdraw(), balance = $102
depositing $10
exiting deposit(), balance = $112
... withdrawing $8
... exiting withdraw(), balance = $104
depositing $10
exiting deposit(), balance = $114
... withdrawing $8
... exiting withdraw(), balance = $106
depositing $10
exiting deposit(), balance = $116
... withdrawing $8
... exiting withdraw(), balance = $108
depositing $10
exiting deposit(), balance = $118
... withdrawing $8
... exiting withdraw(), balance = $110
depositing $10
exiting deposit(), balance = $120
... withdrawing $8
... exiting withdraw(), balance = $112
Notice that the depositor never interrupts the withdrawer, and the withdrawer never interrupts the depositor. At the end of the simulation, no money has been lost or gained.